
Understand the equity of the sub-groups in the ML automatic learning
The assessment of equity in automatic learning is often to examine how the models work in different subgroups defined by attributes such as breed, sex or socioeconomic background. This assessment is essential in contexts such as health care, where the performance of the unequal model can cause disparities in treatment recommendations or diagnostics. An analysis of performance at the subgroup helps to reveal involuntary biases that can be integrated into data design or model. Understanding this requires careful interpretation because equity does not only concern statistical parity – it is also a question of ensuring that predictions lead to fair results when they are deployed in real world systems.
Data distribution and structural bias
A major problem arises when the performance of the model differs between the sub-groups, not due to the bias in the model itself but due to real differences in the distributions of subgroup data. These differences often reflect broader social and structural inequalities that shape the data available for the training and evaluation of models. In such scenarios, the insistence on equal performance between the sub-groups could lead to misinterpretation. In addition, if the data used for the development of models are not representative of the target population – due to sampling or structural exclusions – models can poorly generalize. Inaccurate performance on invisible or under-represented groups can introduce or amplify disparities, especially when the structure of the bias is unknown.
Limits of traditional equity measures
Current equity assessments often involve disintegrated measures or conditional independence tests. These measures are widely used to assess algorithmic equity, in particular accuracy, sensitivity, specificity and positive predictive value, in various subgroups. Managers such as demographic parity, equal dimensions and sufficiency are common benchmarks. For example, the equal chances guarantee that real and false positive rates are similar between groups. However, these methods can produce misleading conclusions in the presence of distribution changes. If the prevalence of labels differs between sub-groups, even specific models may not meet certain equity criteria, which led practitioners to assume the bias where it does not exist.
A causal frame for equity assessment
Researchers from Google Research, Google Deepmind, New York University, Massachusetts Institute of Technology, the hospital for sick children in Toronto and the University of Stanford have introduced a new framework that improves equity assessments. Research has introduced causal graphic models that explicitly model the structure of the data generation, including the way in which subgroup differences and sampling bias influence the behavior of the model. This approach avoids uniform distributions hypotheses and provides a structured means of understanding how the performance of the subgroups varies. Researchers propose to combine traditional disintegrated assessments with causal reasoning, encouraging users to critically think about the sources of disparities in subgroups rather than relying solely on metric comparisons.
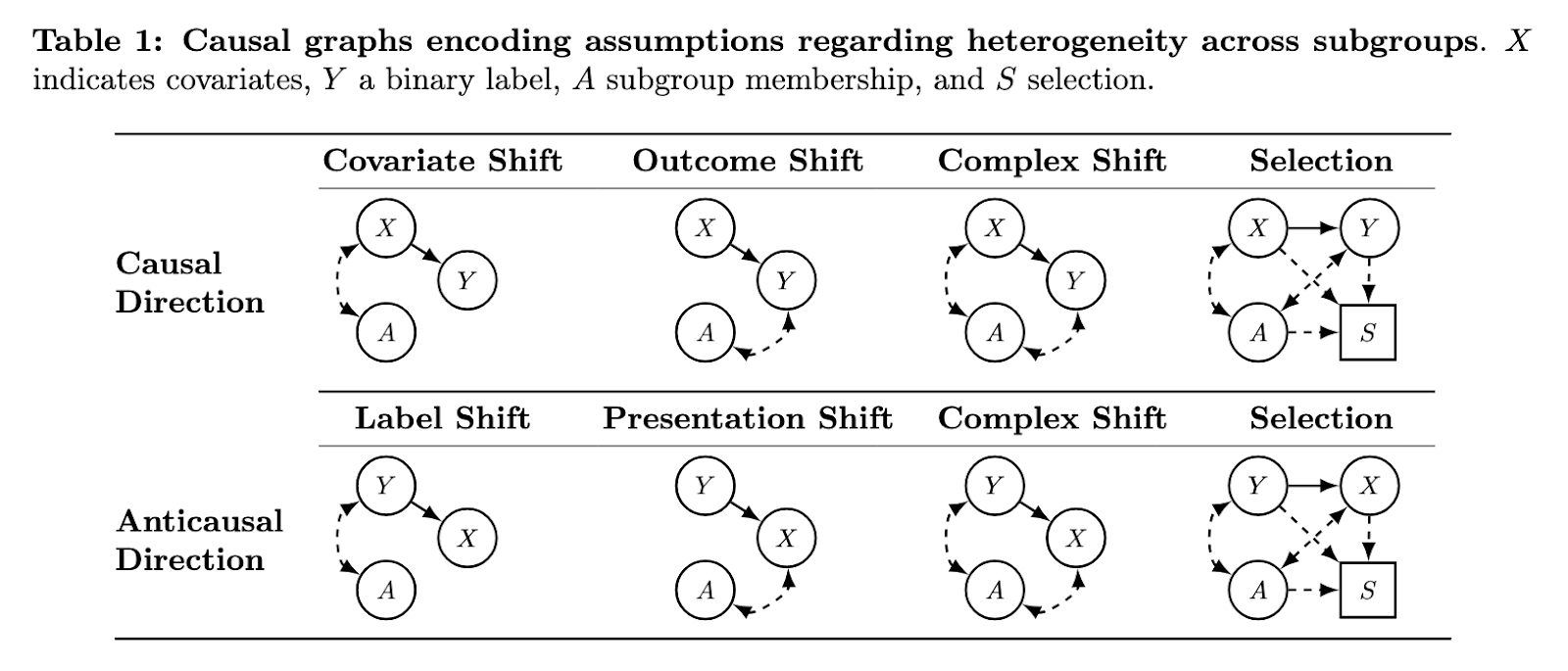
Types of modeled distribution changes
The framework categorizes the types of discrepancies such as the discrepancy of the covariable, the shift in the results and the presentation shift using causal -directed acyclic graphs. These graphs include key variables such as belonging to the subgroup, results and covariables. For example, Covariat Shift describes situations where the distribution of characteristics differs between subgroups, but the relationship between the result and the characteristics remains constant. The change of result, on the other hand, captures cases where the relationship between characteristics and results changes by subgroup. The graphics also adapt to the label shift and selection mechanisms, explaining how subgroup data can be biased during the sampling process. These distinctions allow researchers to predict when the models aware of the sub-groups would improve fairness or when they may not be necessary. The framework systematically identifies the conditions under which standard assessments are valid or deceptive.
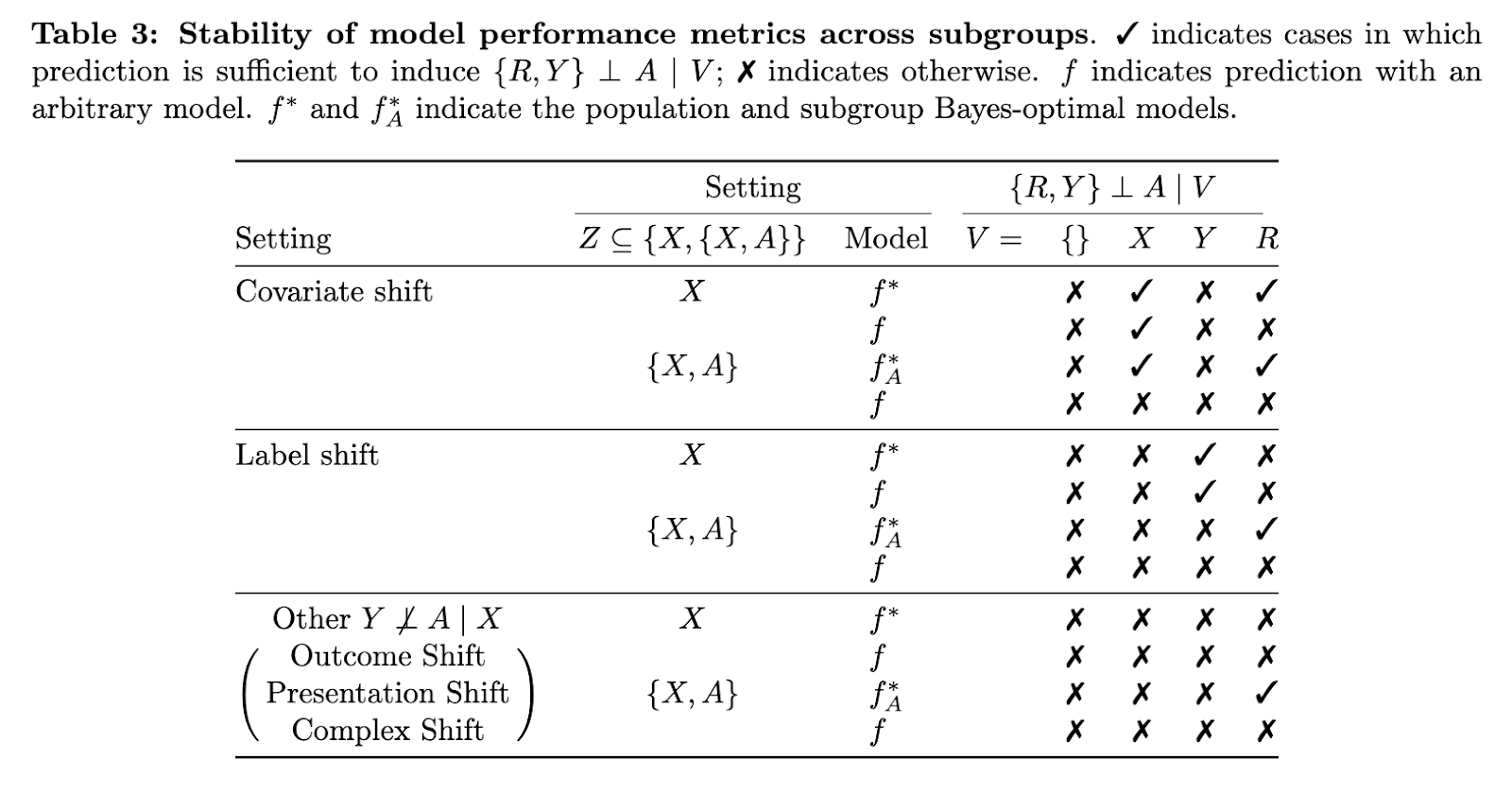
Empirical assessment and results
In their experiences, the team assessed the optimal models of Bayes under various causal structures to be examined when conditions of equity, such as sufficiency and separation, hold. They found that sufficiency, defined as y ⊥ a | F * (Z), is satisfied under the quarter of covariable but not under other types of changes such as the result or complex change. On the other hand, separation, defined as f * (z) ⊥ a | Y, maintained only under the quarter label when belonging to the subgroup was not included in the input of the model. These results show that subgroup models are essential in most practical contexts. The analysis also revealed that when the selection bias only depends on variables like X or A, the equity criteria can always be respected. However, when the selection depends on Y or combinations of variables, the equity of the sub-groups becomes more difficult to maintain.
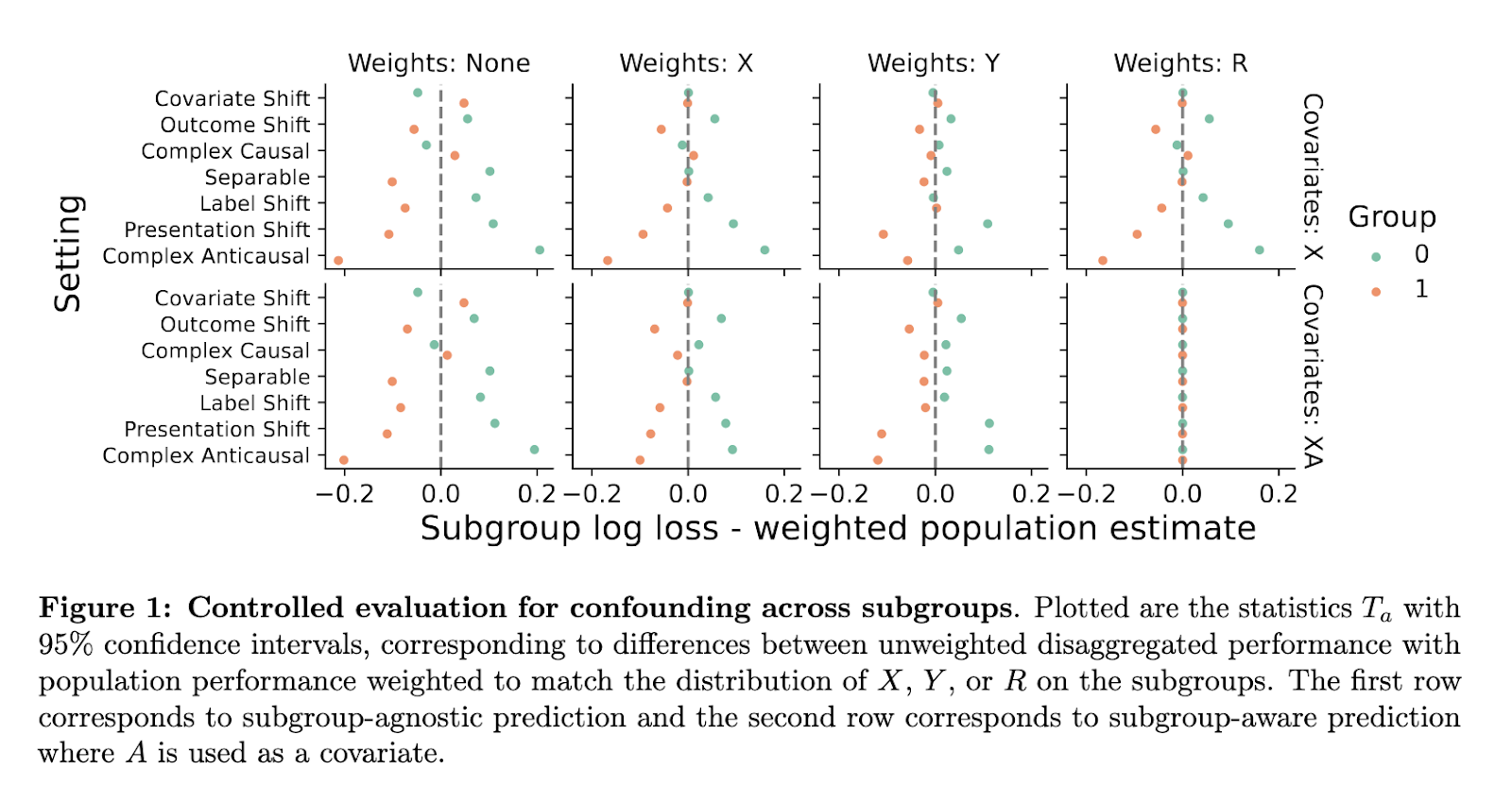
Conclusion and practical implications
This study specifies that equity cannot be judged precisely by the only metrics of the sub-groups. Performance differences can result from underlying data structures rather than biased models. The proposed Causal frame offers tools tools to detect and interpret these nuances. By explicitly modeling causal relationships, researchers provide a way to assessments that reflect both statistical and real concerns about equity. The method does not guarantee perfect equity, but it gives a more transparent foundation to understand how algorithmic decisions have an impact on different populations.
Discover the Paper And GitHub page. All the merit of this research goes to researchers in this project. Also, don't hesitate to follow us Twitter And don't forget to join our Subseubdredit 100k + ml and subscribe to Our newsletter.
Nikhil is an intern consultant at Marktechpost. It pursues a double degree integrated into materials at the Indian Kharagpur Institute of Technology. Nikhil is an IA / ML enthusiast who is still looking for applications in fields like biomaterials and biomedical sciences. With a strong experience in material science, he explores new progress and creates opportunities to contribute.
