
The generative landscape of AI is dominated by models of solid language, often designed for the vast capacities of cloud data centers. These models, although powerful, make it difficult or impossible for everyday users to deploy advanced AI in private and effectively on local devices such as laptops, smartphones or integrated systems. Instead of compressing models on the edge for the edge – often causing substantial performance compromises – the team behind Little boost Asked a more fundamental question: What if a language model was architectically architectically for local constraints?
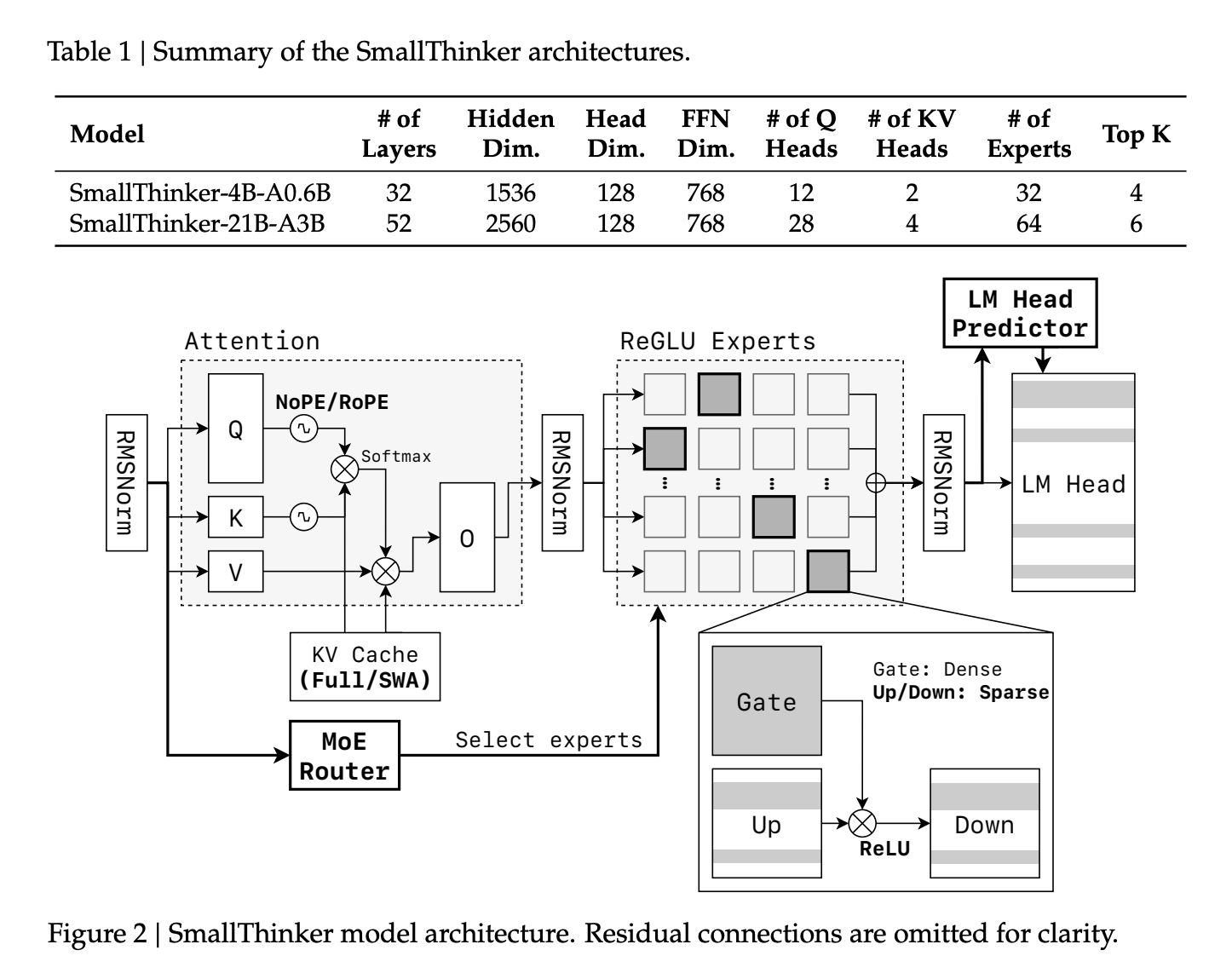
It was Genesis for Little boostA family of models of mixing experts (MOE) developed by researchers from the University of Shanghai Jiao Tong and the Zennergize AI, which targets high performance, limited by memory and limited on the devices available. With two main variants-Smallthinker-4B-A0.6b and Smallthinker-21B-A3B-they have established a new reference for an effective and accessible AI.
Local constraints become design principles
Architectural innovations

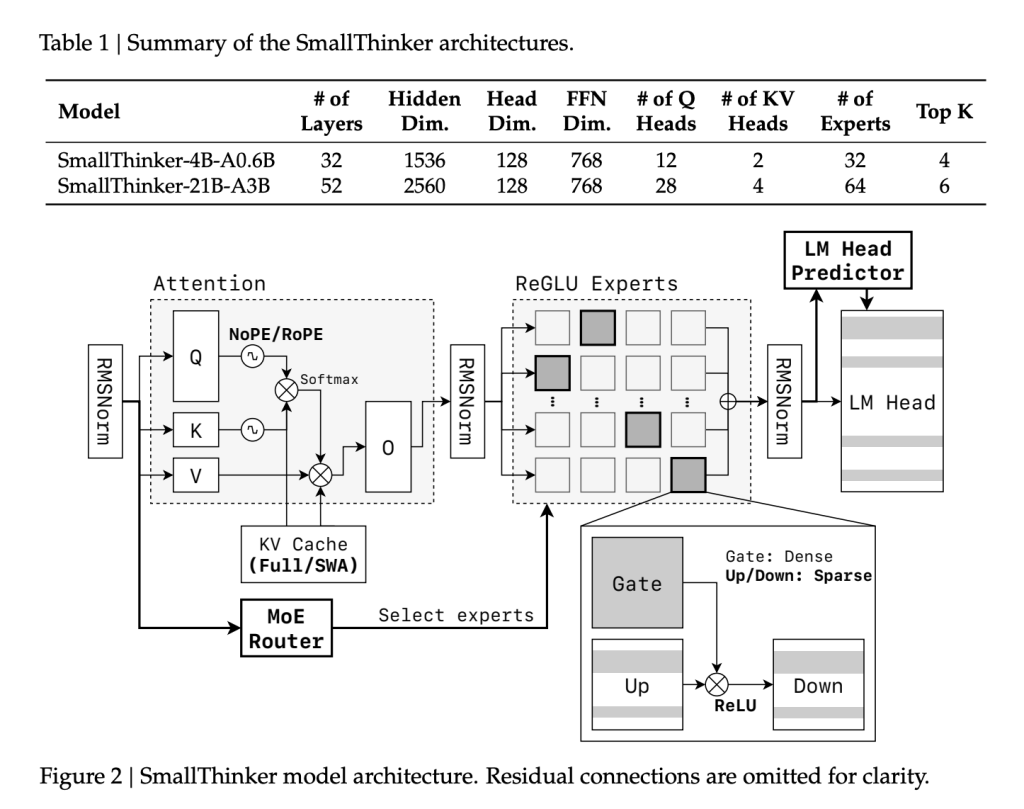
Mixture of fine grain experts (MOE):
Unlike typical monolithic LLM, the spine of Smallthinker has a fine -grained design. Several networks of specialized experts are trained, but only a small subset is activated For each entry token:
- Smallthinker-4b-a0.6b: 4 billion parameters in total, with only 600 million games per token.
- Smallthinker-21b-A3B: 21 billion parameters, of which only 3 billion are active at the same time.
This allows a large capacity without the penalties of memory and calculation of dense models.
Feed-Forward Corteled based on Reglu:
The rarity of activation is also applied using Reglu. Even within activated experts, more than 60% of neurons are inactive in terms of inference, carrying out massive calculations and memory savings.
CAUTION hybrid with rope no:
For effective context handling, Smallthinker uses a new model of attention: alternate between the global layers of the NopositionalMembedding (NOPE) and the local layers of the yarking rope. This approach supports large context lengths (up to 32k tokens for 4B and 16K for 21b), but cuts the size of the key / value cache compared to traditional all-gloubal attention.
Pre-discovery router and intelligent unloading:
Decoupling is essential for use on devices on the device speed of inference from slow storage. Smallthinker's “pre-retention router” predicts what experts will be necessary before each stage of attention, so that their parameters are predefined from SSD / Flash in parallel with the calculation. The system is based on the cache of “hot” RAM experts (using a LRU policy), while less used specialists remain in rapid storage. This design mainly hides the delay of E / O and maximizes the flow even with a minimum system memory.
Data training regime and procedures
The Smallthinker models have been trained again, and not as distillations, on a program that goes from general knowledge to STEM data, mathematics and highly specialized coding:
- The 4B variant treated 2.5 billions of tokens; Model 21B experienced 7.2 Billions.
- The data comes from a mixture of organized open source collections, sets of mathematics and increased synthetic code and monitoring corpus of supervised instructions.
- Methodologies included quality filtering, a synthesis of MGA style data and rapid person -oriented strategies – in particular to increase performance in formal and heavy fields.
Reference results
On academic tasks:
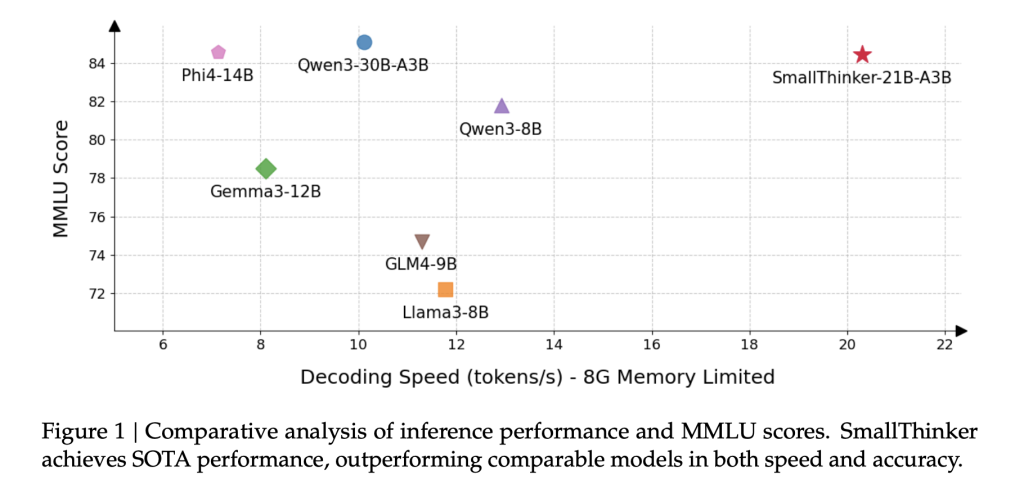
Smallthinker-21b-A3B, despite the activation much fewer parameters than equivalent competitors, stands in the shoulder with or beats in fields ranging from mathematics (Math-500, GPQA-Diamond) to the generation of code (Humanval) and at large knowledge assessments (MMLU) ::
| Model | Mmlu | Gpqa | Math-500 | Ifeval | Lively | Human | Average |
|---|---|---|---|---|---|---|---|
| Smallthinker-21b-A3b | 84.4 | 55.1 | 82.4 | 85.8 | 60.3 | 89.6 | 76.3 |
| QWEN3-30B-A3B | 85.1 | 44.4 | 84.4 | 84.3 | 58.8 | 90.2 | 74.5 |
| Phi-4-14b | 84.6 | 55.5 | 80.2 | 63.2 | 42.4 | 87.2 | 68.8 |
| Gemma3-12b-it | 78.5 | 34.9 | 82.4 | 74.7 | 44.5 | 82.9 | 66.3 |
The 4B-A0.6b model surpasses or also corresponds to other models with similar activated The number of parameters, does not include in particular in reasoning and code.
On real material:
Where Smallthinker really shines on hungry memory devices:
- The 4B model works comfortably with as little as 1 GIB RAM, and the 21B model with only 8 GIB, without catastrophic speed drop.
- The pre-shot and cache mean that even under these limits, inference remains largely faster and smoother than the basic models exchanged towards the disc.
For example, the 21B-A3B variant maintains more than 20 tokens / sec on a standard CPU, while QWEN3-30B-A3B is almost under similar memory constraints.
Impact of rarity and specialization
Specialization of experts:
Activation newspapers reveal that 70 to 80% of experts are little used, while few “hotspot” experts come on for specific areas or languages – a property that allows highly predictable and effective cache.
Rappétuity at the level of neurons:
Even within active experts, median neurons' inactivity rates exceed 60%. The first layers are almost entirely rare, while the deeper layers keep this efficiency, illustrating why Smallthinker manages to do so much with so little calculation.
System limitations and future work
Although the achievements are substantial, Smallthinker is not without warning:
- Size of the training set: Its pre -training corpus, although massive, is even smaller than those behind certain models of border clouds – potentially limiting generalization in rare or obscure fields.
- Model alignment: Only a supervised fine setting is applied; Unlike the main llm of cloud, no learning to strengthen human feedback is used, which can possibly leave security and service gaps.
- Linguistic coverage: English and Chinese, with STEM, dominate training – other languages can see reduced quality.
The authors plan to develop data sets and introduce RLHF pipelines into future versions.
Conclusion
Little boost represents a radical difference compared to the tradition of “models of retractable clouds”. Starting from local constraints, it offers high -capacity, high speed and low -memory use thanks to architectural innovation and systems. This opens the door to a private, reactive and competent AI on almost all devices: democratizing advanced language technology for a much wider band of users and use cases.
Models-Smallthinker-4B-A0.6B-ISTRUCT and Smallthinker-21B-A3B-ISTRUCT-are available for free for researchers and developers, and are convincing proof of what is possible when the design of the model is motivated by the realities of deployment, not just the ambition of the data center.
Discover the Paper, Smallthinker-4b-a0.6b-instruct And Smallthinker-21b-a3b-instruct here. Do not hesitate to Consult our tutorial page on the AI agent and agency AI for various applications. Also, don't hesitate to follow us Twitter And don't forget to join our Subseubdredit 100k + ml and subscribe to Our newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc .. as a visionary entrepreneur and engineer, AIF undertakes to exploit the potential of artificial intelligence for social good. His most recent company is the launch of an artificial intelligence media platform, Marktechpost, which stands out from its in-depth coverage of automatic learning and in-depth learning news which are both technically solid and easily understandable by a large audience. The platform has more than 2 million monthly views, illustrating its popularity with the public.