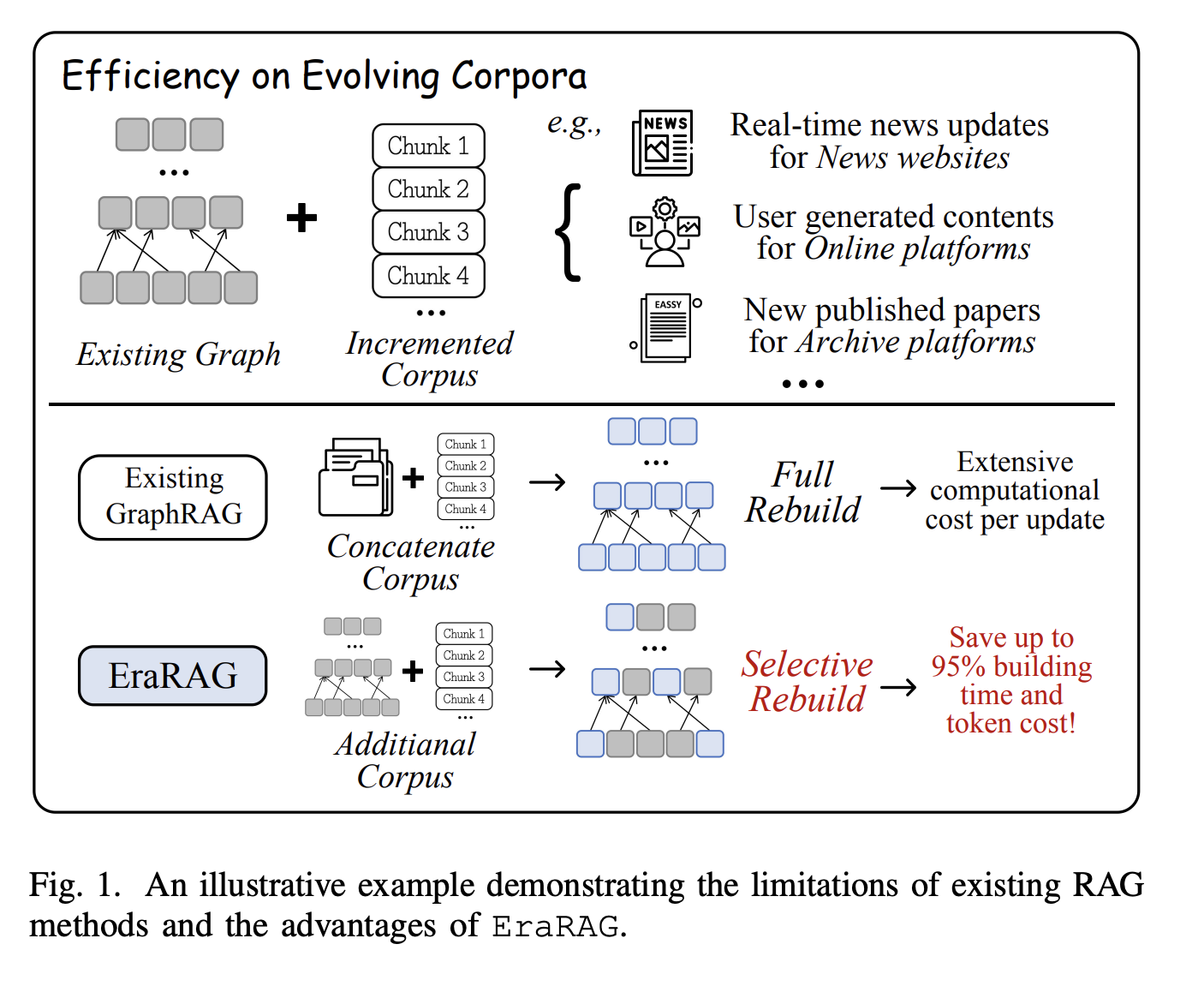
Large language models (LLM) have revolutionized many areas of natural language treatment, but they are always faced with critical limitations when processing up-to-date facts, information specific to the domain or complex multi-hop reasoning. Generation (RAG) (RAG) approaches to recovery aim to fill these shortcomings by allowing language models to recover and integrate information from external sources. However, most existing graphic rag systems are optimized for static corpus and fight with efficiency, accuracy and scalability when data are constantly developing, such as in news flows, research standards or online content generated by users.
Presentation of the Erarag: effective updates for data evolution
Recognizing these challenges, researchers from Huawei, from the Hong Kong University of Science and Technology, and Webank have developed ErarageA generation framework novel with recovery for dynamic and constant expansion corpus. Rather than rebuilding the entire recovery structure whenever new data arrives, Erarag is based on localized selective updates which only affect the parts of the recovery graph assigned by changes.
Basic characteristics:
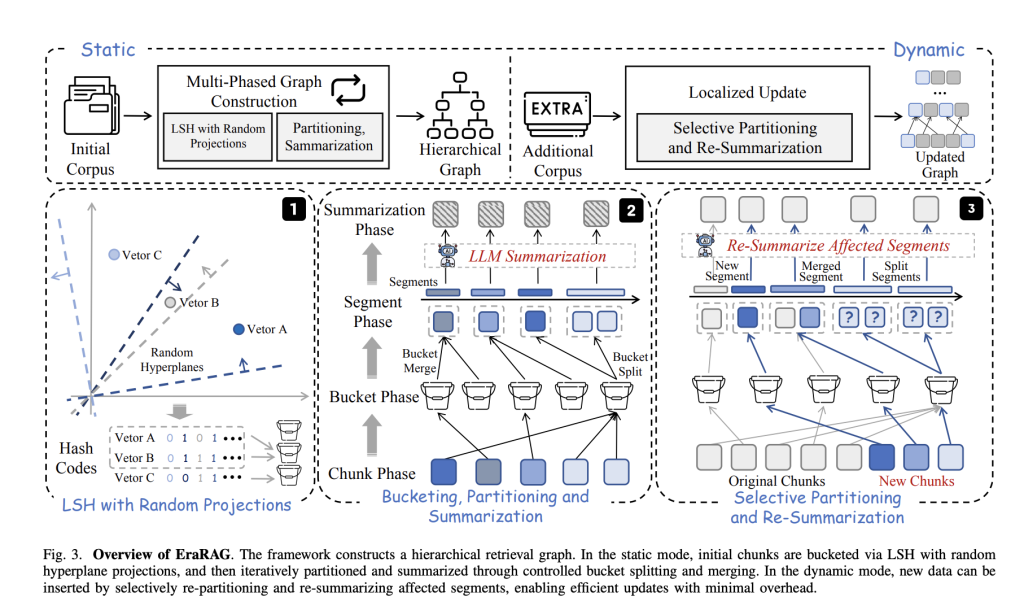
- Hanks sensitive to the locality based on hyperplan (LSH):
Each corpus is taken up in small passages of text which are integrated as vectors. Erarag then uses hyperplans sampled at random to project these vectors into binary chopping codes – a process that groups semantically similar pieces in the same “bucket”. This LSH -based approach maintains both semantic coherence and an effective group. - Construction of hierarchical and multilayer graphics:
The basic recovery structure in Erarag is a multilayer graph. Each layer, segments (or buckets) of similar text are summarized using a tongue model. The too large segments are divided, while those who are too small are merged – by invalidating both semantic coherence and balanced granularity. The representations summarized at higher layers allow effective recovery for fine and abstract grain queries. - Incremential and localized updates:
When new data arrives, its integration is chopped using the original hyperplans – enriching consistency with the construction of the initial graphic. Only the buckets / segments directly affected by the new entries are updated, merged, divided or re-depressed, while the rest of the graph remains intact. The update propagates the hierarchy of the graphics, but is still located in the affected region, which saves significant calculations and tokens costs. - Reproducibility and determinism:
Unlike the standard LSH clustering, Erarag keeps all the hyperplanes used during initial hash. This makes the attribution of deterministic and reproducible bucket, which is crucial for coherent and effective updates over time.
Performance and impact
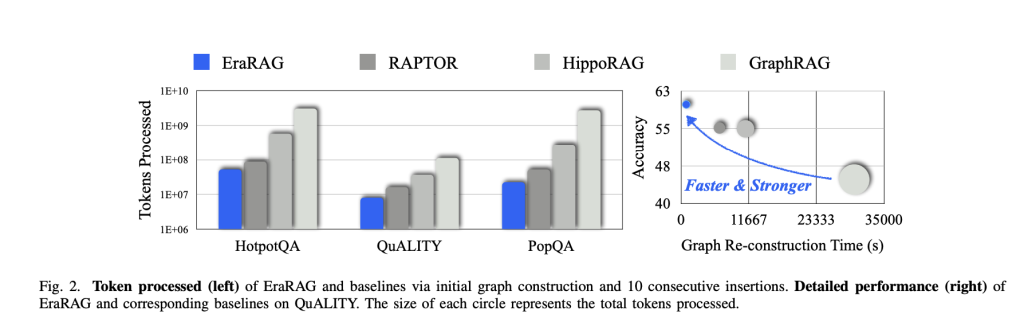
Complete experiences on a variety of questions of answers to the questions show that the Erarag:
- Reduces update costs: Reached up to 95% reduction in the time of reconstruction of graphics and the use of tokens compared to the main rag methods based on graphics (for example, Graphrag, Raptor, Hipporag).
- Maintains great precision: Erarag constantly surpasses other recovery architectures both in precision and recall – static, growing and abstract response tasks – with a minimum compromise of recovery quality or multi -hop reasoning capacities.
- Supports versatile query needs: The design of multilayer graphics allows Erarag to effectively recover the factual details with fine grain or the high -level semantic summaries, adapting its recovery model to the nature of each request.
Practical implications
Erarag offers an ideal evolutionary and robust recovery framework for the parameters of the real world where the data is continuously, such as live news, learned archives or user -oriented platforms. It establishes a balance between the efficiency of recovery and adaptability, which makes applications supported by LLM Plus, reactive and trustworthy in rapidly evolving environments.
Discover the Paper And Github. Any credit for this research goes to researchers in this project | Meet the Ai Dev Newsletter read by 40K + Devs And researchers from Nvidia, Openai, Deepmind, Meta, Microsoft, JP Morgan Chase, Amgen, Aflac, Wells Fargo and 100 others (Subscribe now)
Nikhil is an intern consultant at Marktechpost. It pursues a double degree integrated into materials at the Indian Kharagpur Institute of Technology. Nikhil is an IA / ML enthusiast who is still looking for applications in fields like biomaterials and biomedical sciences. With a strong experience in material science, he explores new progress and creates opportunities to contribute.