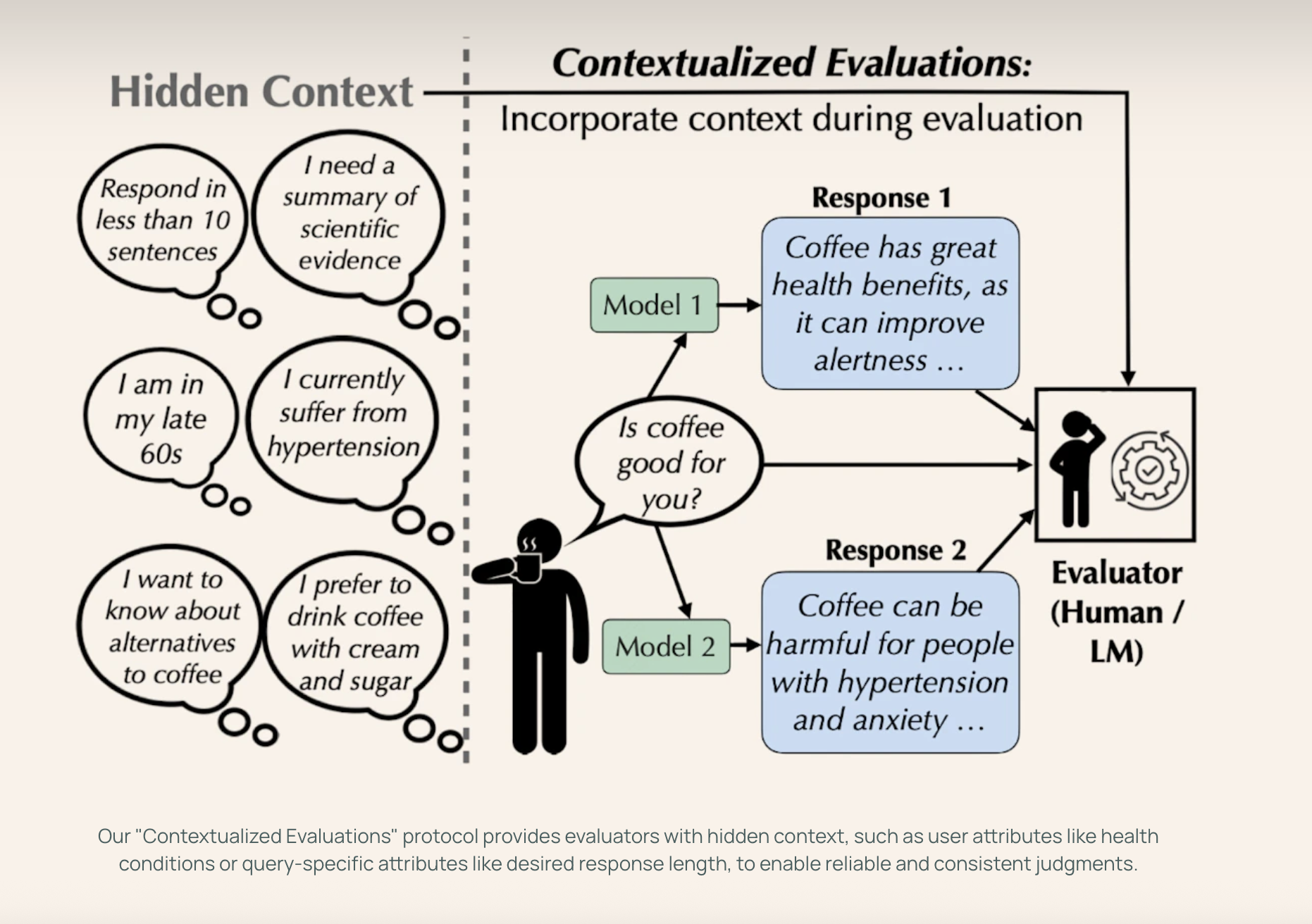
Users of the language model often ask questions without enough details, which makes it difficult to understand what they want. For example, a question like “What book should I read next?” strongly depends on personal taste. At the same time, “How do antibiotics work?” should be answered differently according to the basic knowledge of the user. Current evaluation methods often neglect this missing context, resulting in inconsistent judgments. For example, an answer renting coffee may seem well, but could be useless or even harmful for a person with a state of health. Without knowing the intention or the user's needs, it is difficult to assess the quality of a model's response fairly.
Previous research has focused on the generation of clarification questions to combat ambiguity or missing information in tasks such as questions and answers, dialogue systems and information search. These methods aim to improve understanding of users' intention. Likewise, studies on monitoring instructions and personalization highlight the importance of adaptation of responses to user attributes, such as expertise, age or style preferences. Some works have also examined to what extent the models adapt to various contexts and the training methods offered to improve this adaptability. In addition, assessors based on linguistic models have gained ground because of their effectiveness, although they can be biased, which has aroused efforts to improve their equity through clearer evaluation criteria.
Researchers from the University of Pennsylvania, the Allen Institute for the AI and the University of Maryland of College Park have proposed contextualized assessments. This method adds a synthetic context (in the form of follow-up of follow-up questions) to clarify sub-special requests when evaluating the language model. Their study reveals that the inclusion of the context can have a significant impact on the evaluation results, sometimes even by reversing the models of the models, while improving the agreement between the evaluators. It reduces dependence on superficial characteristics, such as style and discovers potential biases in the responses of the default model, in particular towards strange contexts (Western, educated, industrialized, rich, democratic). The work also shows that the models have variable sensitivities to different user contexts.
The researchers have developed a simple frame to assess how language models work when given more clear and contextualized queries. First, they selected sub-special requests from popular reference data games and enriched them by adding pairs of follow-up responses that simulate user-specific contexts. They then collected answers from different language models. They had both human assessors and based on models compare the responses in two parameters: one with only the original request, and another with the context added. This allowed them to measure how the context affects the classification of models, the assessor agreement and the criteria used for judgment. Their configuration offers a practical way to test how models manage the ambiguity of the real world.
The addition of context, such as the intention of users or the public, considerably improves the evaluation of the model, increasing the inter-eninger agreement by 3 to 10% and even reversing the models of the models in certain cases. For example, GPT-4 outperformed the Gemini-1.5-Flash only when the context was provided. Without this, the evaluations focus on tone or control, while the context attracts attention to precision and help. Default generations often reflect Western, formal and general biases, which makes them less effective for various users. The current benchmarks that ignore the risk of context produce unreliable results. To guarantee the equity and relevance of the real world, the evaluations must couple rich prompts in context with corresponding rating sections which reflect the real needs of users.
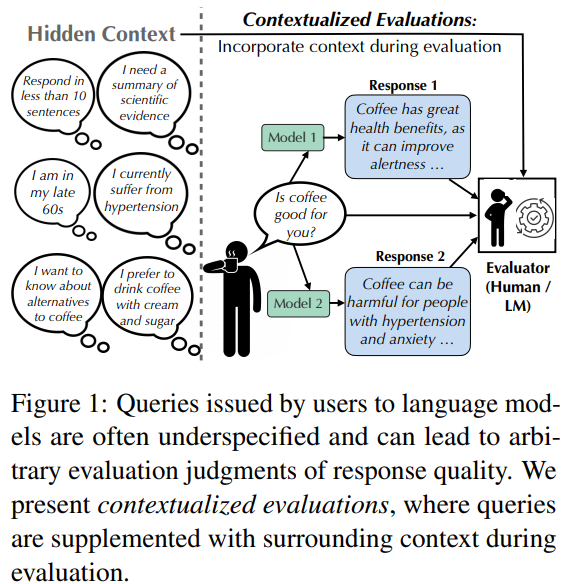
In conclusion, many user requests to language models are vague, lacking a key context such as the intention or expertise of users. This makes the evaluations subjective and unreliable. To remedy this, the study offers contextualized evaluations, where requests are enriched with relevant questions and answers. This additional context helps to move the focusing of lines to the surface level with significant criteria, such as utility, and can even reverse the model rankings. It also reveals underlying biases; The models are often by default with strange hypotheses (western, educated, industrialized, rich, democratic). Although the study uses a limited set of context types and is partly based on automated rating, it offers a solid case for more contextual assessments in future work.
Discover the Paper,, Code,, Data set And Blog. All the merit of this research goes to researchers in this project. Subscribe now to our newsletter IA
Sana Hassan, consulting trainee at Marktechpost and double -degree student at Iit Madras, is passionate about the application of technology and AI to meet the challenges of the real world. With a great interest in solving practical problems, it brings a new perspective to the intersection of AI and real life solutions.
