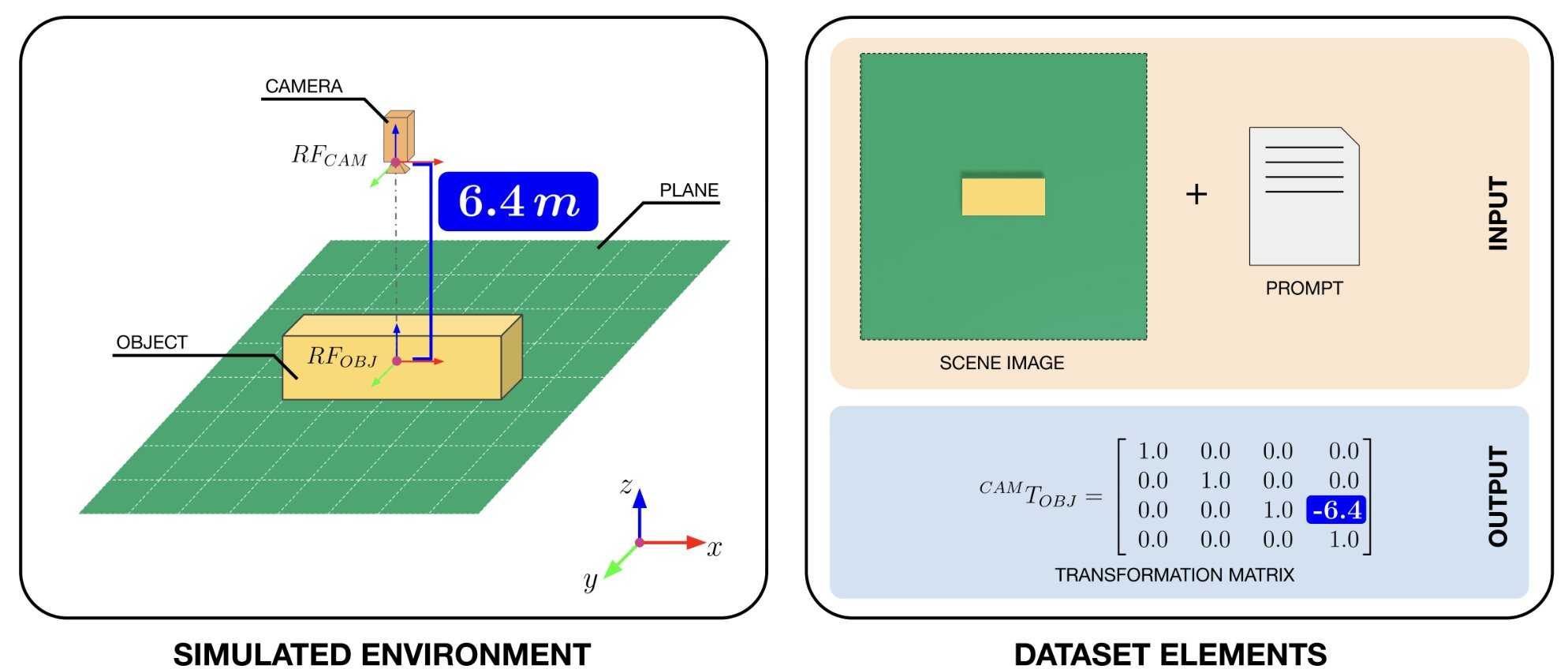

On the left, the simulated environment containing a cuboid placed on a plane and observed by a camera, placed directly above the object at different distances. On the right, an example of the elements of the data set used to form the model: an image and a textual prompt as input, with the spatial relationship between the Cuboid and the camera represented as a transformation matrix as a desired output. Credit: Gioele Migno.
The language vision models (VLM) are advanced calculation techniques designed to process both images and written texts, which makes predictions accordingly. Among other things, these models could be used to improve the capacities of robots, helping them to interpret their environment with precision and to interact more effectively with human users.
A team of researchers from the Italian Institute of Technology (IIT) and the University of Aberdeen recently introduced a new conceptual framework and a set of data containing data generated by calculation, which could be used to form VLM on space reasoning tasks. Their framework and data set, presented in a paper Published on arxiv A prior server could contribute to the development of artificial intelligence (AI) Systems that are better equipped to sail in real world environments and communicate with humans.
This research marks the outcome of the Fair * project and follows from a recent collaboration between the research line of social cognition in human-robot interaction (S4HRI) at IIT, guided by Professor Agnieszka Wykowska, and the Action Prediction Laborat at the University of Aberdeen, which is led by Professor Patric Bach.
“Our research group examines how human social cognition mechanisms are engaged during interactions with artificial agents,” Tech Xplore Davide in Tommaso, technologist at Iit and Co-Senor author of the newspaper, told Tech Xplore. “Our previous studies have indicated that, under specific conditions, people attribute intentionality to robots and interact with them in a way that closely resembles interactions with other social partners.
“Consequently, the understanding of these mechanisms, in particular the role of non -verbal indices such as the gaze, gestures and spatial behavior, is crucial to develop effective calculation models social cognition in robots. “”
The visual perspective (VPP), the ability to understand what a visual scene from the point of view of another, could be very advantageous for robotic systems, because it could allow them to give meaning to the instructions given to them, cooperate with other agents and succeed in completing the missions. From Tommaso and his colleagues recently tried to reproduce this key capacity in robots, while ensuring that robots can apply it in a wide range of contexts.
“Our main objective was to allow robots to reason effectively on what other agents (humans or artificial) may or cannot perceive their views in shared environments,” said Tommaso. “For example, robots must assess precisely if the text is read from another person's point of view, if an object is hidden behind an obstacle, or if an object is appropriate for a human to grasp or point to him.
“Despite the current fundamental models without sophisticated spatial reasoning capacities, we firmly believe that the exploitation of large -language models for understanding scenes, as well as synthetic scene representations, is a significant promise for the modeling of human -type VPT capacities in incarnated artificial agents.”
To improve the VPP capacities of VLMs, the researchers have compiled a set of data that could support their training on space reasoning tasks. Using the Nvidia omaverse replicator, a platform to generate synthetic data, they created a new “artificial world”, which consisted essentially in a simple scene capturing a cube, which was seen from different angles and distances.
They then took captured 3D images of the cube in this synthetic world, adding a description of natural language for each of them, as well as a 4×4 transformation matrix, a mathematical structure which represents the position and the orientation of the cube. The set of data was Published online And can be used by other teams to train their VLM.
“Each image captured by the virtual camera is delivered with a text prompt containing the dimensions of the cube, and a precise transformation matrix which code the spatial relationship between the camera and the object, the type of data robots used to plan the movements and interact with the world,” explained Joel Currie, the first author of the newspaper, which is a ph.d. Student at the University of Aberdeen and researcher at the Italian Institute of Technology.
“Because the environment is synthetic, we control all the aspects and quickly generate tens of thousands of image-image pairs (something almost impossible with the configurations of the real world). It is a way of teaching robots not only to see, but to understand space as a physical being.”
Until now, the framework introduced by researchers is simply theoretical, but it could soon open new possibilities for the formation of real VLM. The researchers themselves could soon assess its potential by forming a model using the data set they have compiled or data generated by similar synthesis.
“What we have done is fundamentally conceptual,” said Currie. “We propose a new way for AI to learn space, not only from its own point of view, but from someone else. Instead of a hard coded geometry, we treat the visual perspective as something that the model can learn by using vision and language. It is a step towards embodied cognition – observations that do not just see the world, but can imagine what it looks like. True social intelligence in machines. “
The recent work of De Tommaso, Currie, Migno and their colleagues could inspire the generation of other sets of similar synthetic data for the formation of VLM on space reasoning tasks. These efforts could collectively contribute to the improvement of humanoid robots and other embodied AI agents, potentially facilitating their deployment in real contexts.
“Our next step will be to make the virtual environment as realistic as possible, bringing the distance between a scene from simulated and real world,” added Gioele Migno, a graduate in artificial intelligence and robotics from the Sapienza University of Rome and recently joined the S4HRI research unit at Iit as a scholarship holder.
“This step is crucial to transfer the knowledge acquired by the model in the real world, and to allow an embodied robot to exploit spatial reasoning. Once this is affected, we are then interested in studying how these capacities can make interactions with humans more effective in scenarios where they share a spatial understanding of the scene.”
Written for you by our author Ingrid Fadelledited by Lisa Lock
and verified facts and examined by Robert Egan – This article is the result of meticulous human work. We are counting on readers like you to keep independent scientific journalism alive. If this report matters to you, please consider a donation (especially monthly). You will get a without advertising count as a thank you.
More information:
Joel Currie et al, towards cognition embodied in robots via spatially anchored synthetic worlds, arxiv (2025). DOI: 10.48550 / Arxiv. 2005.14366
© 2025 Science X Network
Quote: Visual language models acquire space reasoning skills through artificial worlds and 3D stage descriptions (2025, June 13) recovered on June 20, 2025 from https://techxplore.com/news/2025-06-vison-laging-gain-spatial-skills.html
This document is subject to copyright. In addition to any fair program for private or research purposes, no part can be reproduced without written authorization. The content is provided only for information purposes.