In this tutorial, we will explore a range of SHAP-IQ visualizations which provide an overview of how an automatic learning model arrives at its predictions. These visuals help decompose the behavior of the complex model into interpretable components – revolutionizing the individual and interactive contributions of the characteristics to a specific prediction. Discover the Complete codes here.
Dependencies installation
!pip install shapiq overrides scikit-learn pandas numpy seabornfrom sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import train_test_split
from tqdm.asyncio import tqdm
import shapiq
print(f"shapiq version: {shapiq.__version__}")Import of the data set
In this tutorial, we will use the MPG dataset (Miles by Gallon), which we will directly load the Seaborn library. This data set contains information on various car models, including features such as power, weight and origin. Discover the Complete codes here.
import seaborn as sns
df = sns.load_dataset("mpg")
dfProcessing of the data set
We use label coding to convert the categorical columns (s) to digital format, which makes them suitable for model training.
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# Drop rows with missing values
df = df.dropna()
# Encoding the origin column
le = LabelEncoder()
df.loc(:, "origin") = le.fit_transform(df("origin"))
df('origin').unique()for i, label in enumerate(le.classes_):
print(f"{label} → {i}")Divide data into training and test subsets
# Select features and target
X = df.drop(columns=("mpg", "name"))
y = df("mpg")
feature_names = X.columns.tolist()
x_data, y_data = X.values, y.values
# Train-test split
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.2, random_state=42)Model training
We form a random forest regressor with a maximum depth of 10 and 10 decision trees (n_estimars = 10). A fixed random_state ensures reproducibility.
# Train model
model = RandomForestRegressor(random_state=42, max_depth=10, n_estimators=10)
model.fit(x_train, y_train)Model assessment
# Evaluate
mse = mean_squared_error(y_test, model.predict(x_test))
r2 = r2_score(y_test, model.predict(x_test))
print(f"Mean Squared Error: {mse:.2f}")
print(f"R2 Score: {r2:.2f}")Explain a local body
We choose a specific test instance (with instance_id = 7) to explore how the model came to its prediction. We will print the true value, the predicted value and the functionality values for this instance. Discover the Complete codes here.
# select a local instance to be explained
instance_id = 7
x_explain = x_test(instance_id)
y_true = y_test(instance_id)
y_pred = model.predict(x_explain.reshape(1, -1))(0)
print(f"Instance {instance_id}, True Value: {y_true}, Predicted Value: {y_pred}")
for i, feature in enumerate(feature_names):
print(f"{feature}: {x_explain(i)}")Generate explanations for several interaction orders
We generate explanations based on Shapley for different interaction orders using the Shapiq package. More specifically, we calculate:
- Order 1 (standard shapley values): contributions from individual functionalities
- Order 2 (Interactions by pair): combined effects of functional pairs
- Order N (Complete Interaction): all interactions up to the total number of features
# create explanations for different orders
feature_names = list(X.columns) # get the feature names
n_features = len(feature_names)
si_order: dict(int, shapiq.InteractionValues) = {}
for order in tqdm((1, 2, n_features)):
index = "k-SII" if order > 1 else "SV" # will also be set automatically by the explainer
explainer = shapiq.TreeExplainer(model=model, max_order=order, index=index)
si_order(order) = explainer.explain(x=x_explain)
si_order1. Force graphics
The strength route is a powerful visualization tool that helps us understand how an automatic learning model has come to a specific prediction. It displays the basic prediction (that is to say the expected value of the model before seeing the functionality), then shows how each function “pushes” the prediction higher or lower.
In this intrigue:
- Red bars represent characteristics or interactions that increase prediction.
- Blue bars represent those that decrease it.
- The length of each bar corresponds to the magnitude of its effect.
When you use Shapley interaction values, the force layout can visualize not only individual contributions but also the interactions between functionalities. This makes it particularly insightful when interpreting complex models, because it visually decomposes how functional combinations work together to influence the result. Discover the Complete codes here.
sv = si_order(1) # get the SV
si = si_order(2) # get the 2-SII
mi = si_order(n_features) # get the Moebius transform
sv.plot_force(feature_names=feature_names, show=True)
si.plot_force(feature_names=feature_names, show=True)
mi.plot_force(feature_names=feature_names, show=True)
From the first route, we can see that the basic value is 23.5. Characteristics such as weight, cylinders, power and displacement have a positive influence on the prediction, pushing it above the base line. On the other hand, the model year and acceleration have a negative impact, drawing the prediction down.
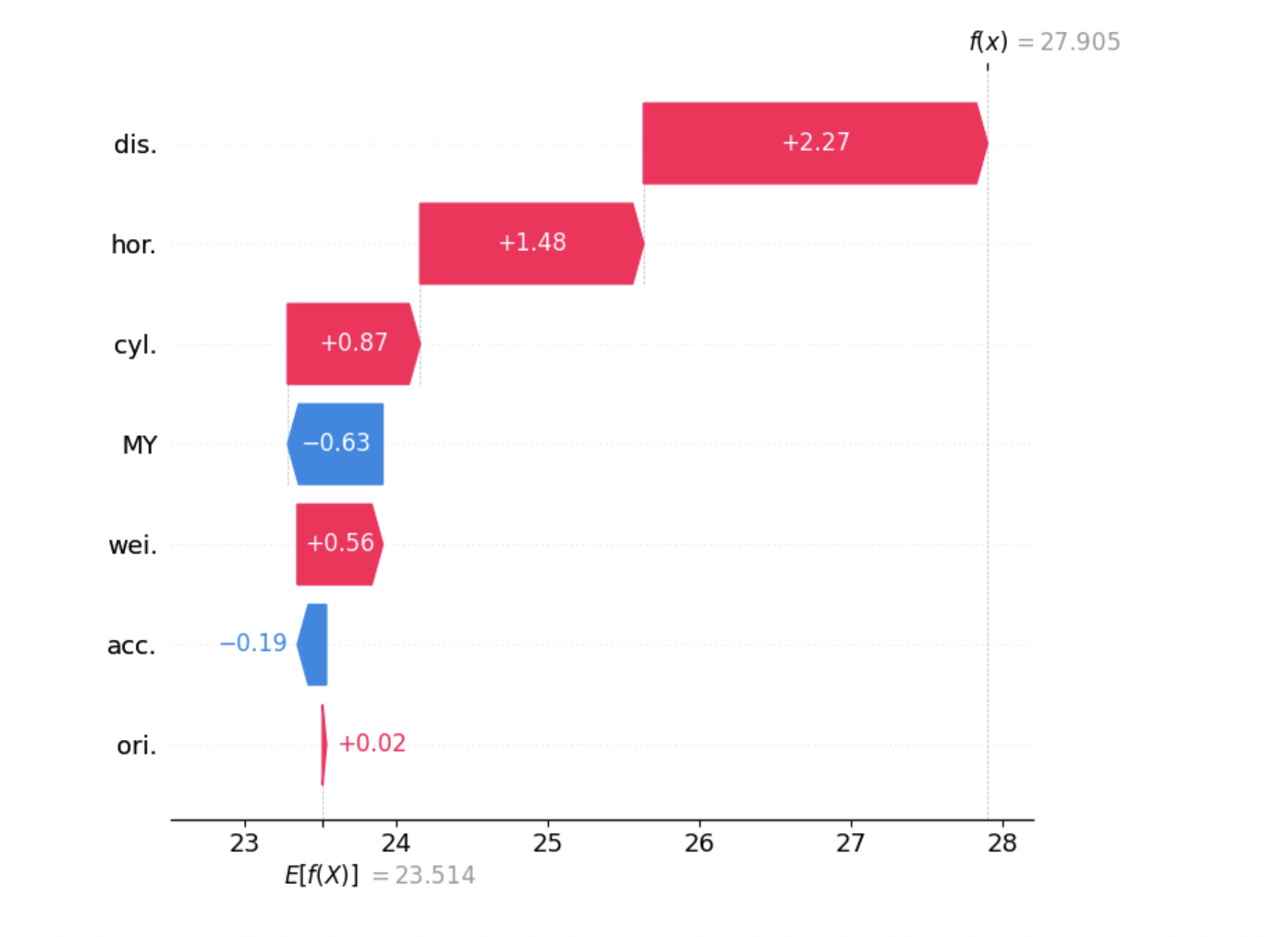
2. Cascade charter
Similar to the intrigue of force, the layout of the waterfall is another popular means of visualizing the values of Shapley, originally introduced with the form library. It shows how different features push prediction higher or less than the basic line. A key advantage of cascading intrigue is that it automatically brings together features with very low impacts in a “other” category, which makes the graphic cleaner and easier to understand. Discover the Complete codes here.
sv.plot_waterfall(feature_names=feature_names, show=True)
si.plot_waterfall(feature_names=feature_names, show=True)
mi.plot_waterfall(feature_names=feature_names, show=True)


3. Network layout
The network layout shows how the features interact with each other using the first and second -order Shapley interactions. The size of the knot reflects the impact of individual features, while the width and color of the edge show the resistance and the direction of interaction. It is particularly useful for dealing with many features, revealing complex interactions that simpler plots could miss. Discover the Complete codes here.
si.plot_network(feature_names=feature_names, show=True)
mi.plot_network(feature_names=feature_names, show=True)
4. Graphic stud if
The layout of the graphic if the network layout extends by visualizing all higher order interactions as hyper-edges connecting several features. The size of the knot shows the impact of individual characteristics, while the width, color and transparency of the edges reflect the strength and direction of interactions. It offers a complete view of how the characteristics jointly influence the prediction of the model. Discover the Complete codes here.
# we abbreviate the feature names since, they are plotted inside the nodes
abbrev_feature_names = shapiq.plot.utils.abbreviate_feature_names(feature_names)
sv.plot_si_graph(
feature_names=abbrev_feature_names,
show=True,
size_factor=2.5,
node_size_scaling=1.5,
plot_original_nodes=True,
)
si.plot_si_graph(
feature_names=abbrev_feature_names,
show=True,
size_factor=2.5,
node_size_scaling=1.5,
plot_original_nodes=True,
)
mi.plot_si_graph(
feature_names=abbrev_feature_names,
show=True,
size_factor=2.5,
node_size_scaling=1.5,
plot_original_nodes=True,
)


5.
The bar plot is suitable for global explanations. While other plots can be used both locally and overall, the bar route summarizes the overall importance of functionalities (or interactions of characteristics) by showing the average values of Shapley (or interaction) absolute to all instances. In Shapiq, it highlights the interactions according to the interactions contribute the most on average. Discover the Complete codes here.
explanations = ()
explainer = shapiq.TreeExplainer(model=model, max_order=2, index="k-SII")
for instance_id in tqdm(range(20)):
x_explain = x_test(instance_id)
si = explainer.explain(x=x_explain)
explanations.append(si)
shapiq.plot.bar_plot(explanations, feature_names=feature_names, show=True)
The “distance” and “power” are the most influential characteristics overall, which means that they have the strongest individual impact on the predictions of the model. This is obvious from their absolute interaction values of Absolute Shapley raised in the route of the bar.
In addition, when you look at second-rate interactions (that is, how two characteristics interact together), “power × weight” and “distance × power” combinations show significant joint influence. Their combined attribution is approximately 1.4, indicating that these interactions play an important role in the formation of the predictions of the model beyond what each characteristic contributes individually. This highlights the presence of non -linear relationships between the characteristics of the model.
Discover the Complete codes here. Do not hesitate to consult our GitHub page for tutorials, codes and notebooks. Also, don't hesitate to follow us Twitter And don't forget to join our Subseubdredit 100k + ml and subscribe to Our newsletter.

I graduated in Civil Engineering (2022) by Jamia Millia Islamia, New Delhi, and I have a great interest in data science, in particular neural networks and their application in various fields.
