
Multimodal models of large language (MLLM) are designed to treat and generate content through various methods, including text, images, audio and video. These models aim to understand and integrate information from different sources, allowing applications such as answers to visual questions, image subtitling and multimodal dialogue systems. The development of MLLM represents an important step towards the creation of AI systems which can interpret and interact with the world in a more human way.
A main challenge in the development of effective MLLM lies in the integration of various types of input, in particular visual data, in language models while retaining high performance between tasks. Existing models often fight on the balance between a strong understanding of language and effective visual reasoning, especially when scaling complex data. In addition, many models require large data sets to work well, which makes it difficult to adapt to specific tasks or areas. These challenges highlight the need for more effective and evolving approaches to multimodal learning.
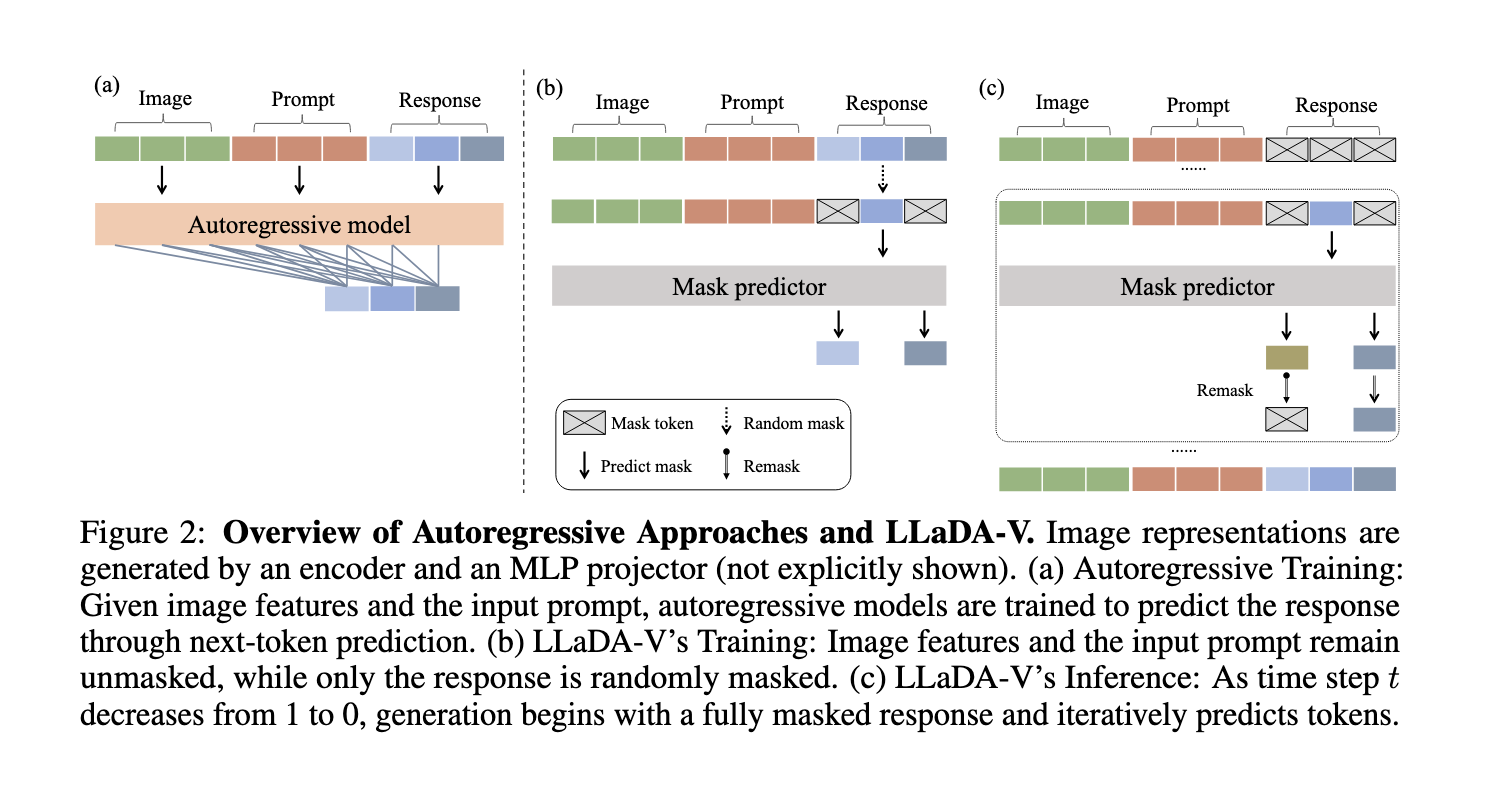
The current MLLMs mainly use self -regressive methods, predicting a token at the same time from left to right. Although effective, this approach has limits to the management of complex multimodal contexts. Alternative methods, such as diffusion models, have been explored; However, they often have an understanding of lower languages due to their limited architectures or their inadequate training strategies. These limitations suggest a gap where a model purely based on diffusion could offer competitive multimodal reasoning capacities if it was effectively designed.
Researchers from the Renmin University of China and the ANT group introduced Llada-V, a model of masked language modeling (MLLM) purely based on diffusion which integrates the adjustment of visual instruction with masked diffusion models. Built on Llada, a large-language diffusion model, Llada-V incorporates a vision coder and an MLP connector to project visual characteristics in the language integration space, allowing effective multimodal alignment. This conception represents a difference compared to dominant self -regressive paradigms in current multimodal approaches, aimed at overcoming existing limits while maintaining the efficiency and scalability of data.

Llada-V uses a masked distribution process where text responses are gradually refined by the iterative prediction of masked tokens. Unlike the self-regressive models that sequentially predict tokens, Llada-V generates outings by reversing the masked diffusion process. The model is formed in three stages: the first step aligns vision and incorporations of language by mapping visual features of Siglip2 in the linguistic space of Llada. The second step refines the model using 10 million unique image samples and 2 million Mammoth-VL multimodal samples. The third step focuses on reasoning, using QA pairs of 900K Visualwebinstruct and a mixed dataset. Bidirectional attention improves the understanding of the context, allowing a robust multimodal understanding.
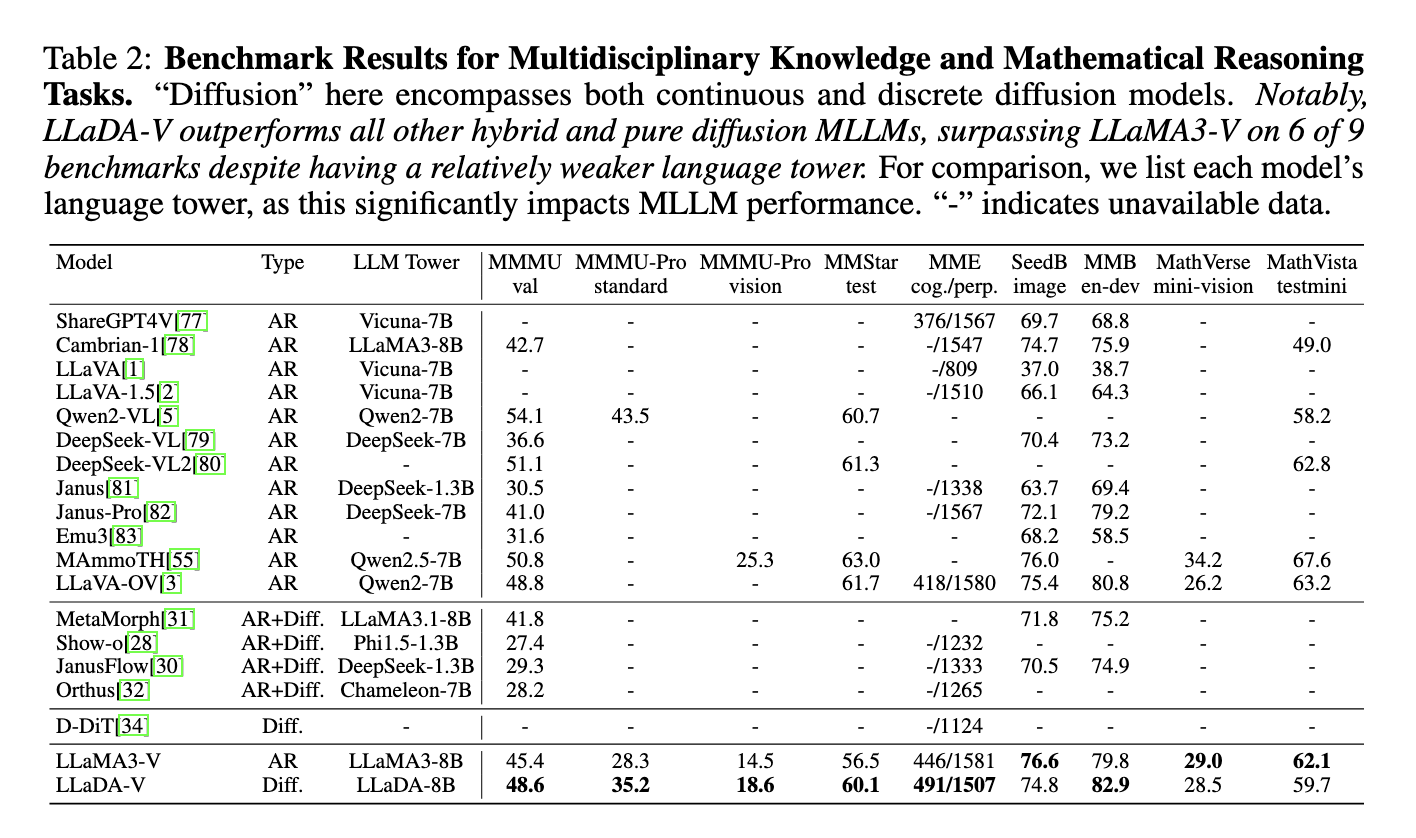
In evaluations on 18 multimodal tasks, Llada-V has demonstrated higher performance compared to self-regressive hybrid models and models purely based on diffusion. He outperformed LLAMA3-V on most multidisciplinary knowledge and mathematical reasoning tasks like MMMU, MMMU-PRO and MMSTAR, obtaining a score of 60.1 on MMSTAR, near the LLADA-VL linguistic tower of QWEN2. LLADA-V also excelled in data efficiency, outperforming LLAMA3-V on MMMU-PRO with 1m samples against 9M of LLAMA3-V. Although it is late in the references of understanding graphics and documents, such as AI2D, and in real world stage tasks, such as the results of Realworldqa, Llada-V highlight its promise of multimodal tasks.
In summary, Llada-V takes up the challenges of the construction of effective multimodal models by introducing an architecture purely based on the diffusion which combines a visual instruction agreement with a masked diffusion. The approach offers strong multimodal reasoning capacities while maintaining data efficiency. This work demonstrates the potential of diffusion models in multimodal AI, opening the way to a more in -depth exploration of probabilistic approaches to complex AI tasks.
Discover the Paper And GitHub page . All the merit of this research goes to researchers in this project. Also, don't hesitate to follow us Twitter And don't forget to join our 95K + ML Subdreddit and subscribe to Our newsletter.
Nikhil is an intern consultant at Marktechpost. It pursues a double degree integrated into materials at the Indian Kharagpur Institute of Technology. Nikhil is an IA / ML enthusiast who is still looking for applications in fields like biomaterials and biomedical sciences. With a strong experience in material science, he explores new progress and creates opportunities to contribute.