Learning strengthening with verifiable rewards (RLVR) allows LLMS to perform a complex reasoning on tasks with clear and verifiable results, with high performance in mathematics and coding. However, many real world scenarios do not have explicit verifiable answers, making a challenge for training models without direct reward signals. Current methods deal with this gap via RLHF via the preferences classification, where human judgments are collected on pairs or output lists of the model. In addition, preference-based reward models can increase performance in the early stages, but they tend to over-adapt to superficial artifacts such as response length, fitness quirks and annotators' biases. These models require large volumes of pairs comparisons, which makes them fragile and costly.
The RLVR methods are now extending beyond mathematics and coding, with general performance demonstrating solid performance in physics, finance and politics, achieving ten points on MMLU-Pro via GRPO FINEDING. The assessment based on sections has become a standard for advanced LLMs, with executives such as Healthbench Pailing Criteria writes clinicians with automated judges to assess billing, security and empathy. However, these headings appear only during the evaluation phases rather than the training. In addition, processes supervision methods try to provide more granular feedback by rewarding intermediate reasoning stages through labels generated by MCTS and generative reward models such as ThinkPRM.
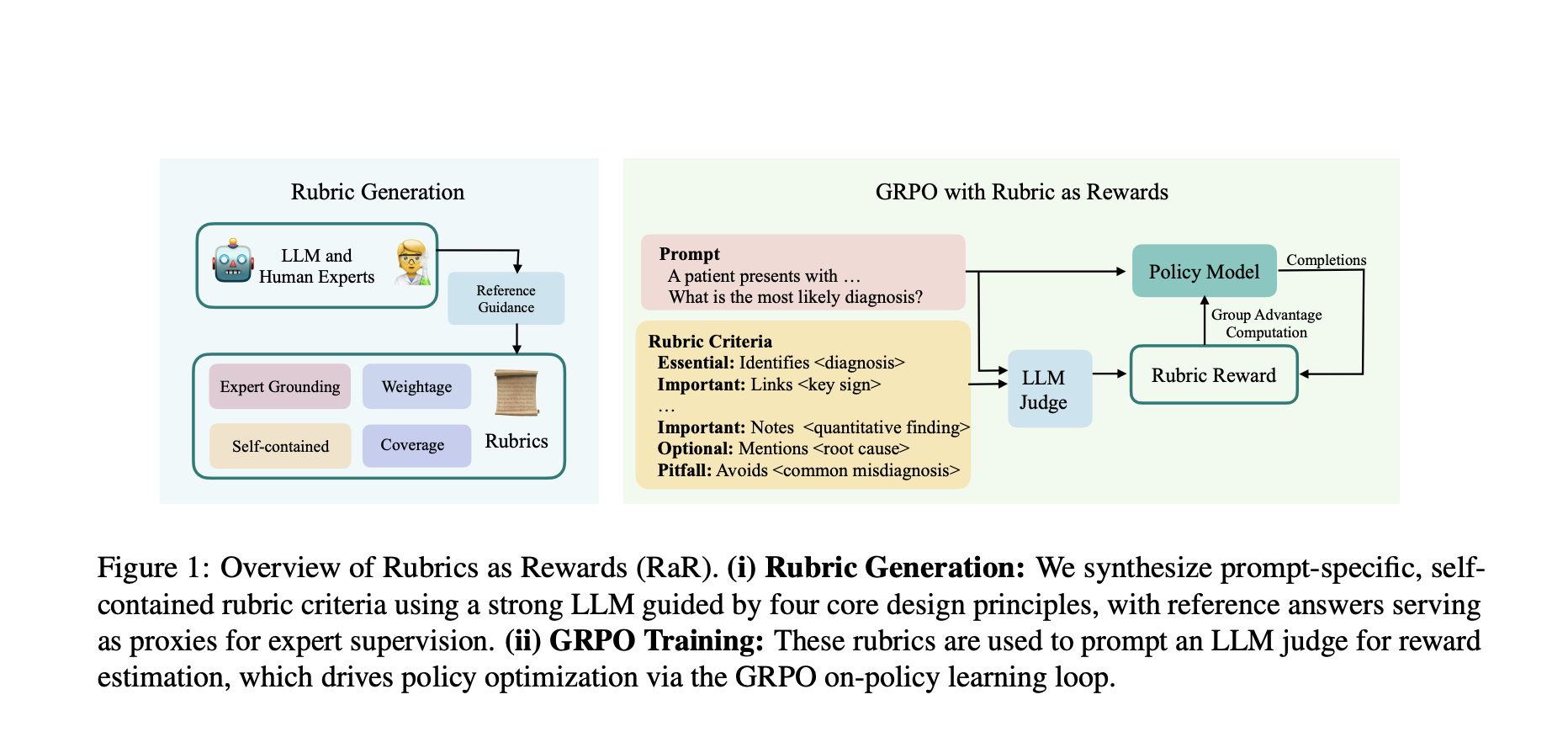
Researchers from Scale IA have proposed headings as awards (RAR), a policy learning framework on politics that uses control list sections to guide multi-critère tasks. The method generates invites heads based on carefully designed principles, where each section describes clear standards for high quality responses and provides supervision signals to the interpretation of man. In addition, it is applied to the fields of medicine and science, resulting in two sets of specialized training data, Rar-Medicine-20k and Rar-Science-20k. RAR allows smaller judge models to obtain higher alignment with human preferences by transforming the sections into structured reward signals while retaining robust performance on different model scales.
The researchers used LLM as expert proxies to generate these sections, ensuring adherence to the following wishes: anchored in expert councils, full coverage, semantic weighting and autonomous evaluation. For each area, specialized prompts allow the LLM to generate 7-20 elements of the section according to the complexity of the entry issue. Each element is assigned categorical weights, such as essential criteria or important criteria, to determine its meaning for correct answers. The training uses GRPO algorithm with QWEN2.5-7B as a basic policy model. In addition, the training pipeline works through three main components: response generation, reward calculation and policies update.
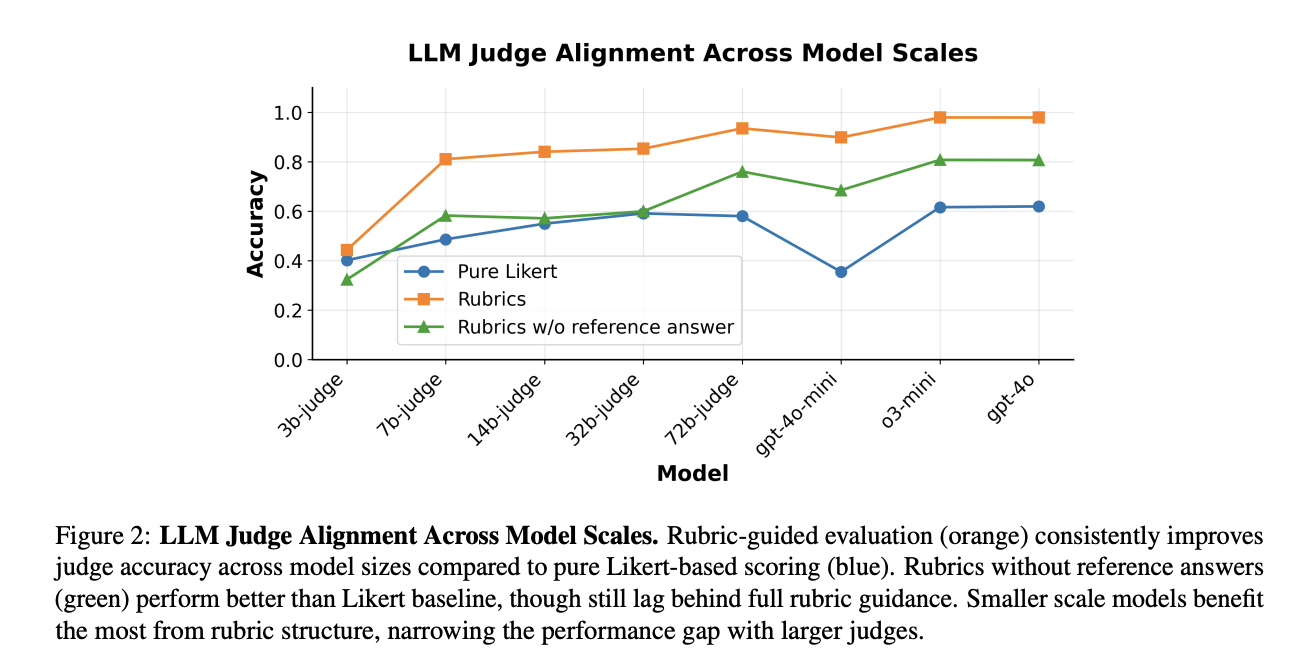
The Rar-implicit method surpasses basic methods such as simple-likert, the best variant reaching up to 28% relative improvement in Healthbench-1K and 13% on GPQA. It also surpasses basic policy and instructions models, showing the effectiveness of the training guided by the sections for the evaluation of the nuanced response while corresponding or exceeding the basic performance of the reference labels. Beyond the raw measures, the assessments guided by the sections provide clearer and more precise signals on the models of the model, reaching higher precision when the favorite responses receive appropriate notes. In addition, expert advice is essential for the generation of synthetic sections, the sections developed using reference responses reaching higher precision than those without human ideas.
In summary, the researchers introduced RAR which progresses after the formation of language models using structured sections of control list as a reward signals. It offers stable training signals, maintaining human interpretability and alignment. However, this research remains limited to medical and scientific fields, requiring validation between tasks such as open dialogue. The researchers explored only two reward aggregation strategies, implicit and explicit, leaving alternative weighting patterns. In addition, they did not carry out a controlled analysis of the risk of reward hacking, and the dependence on standard LLM because the judges suggest that future work could benefit from dedicated assessors with improved reasoning capacities.
Discover the Paper here. All the merit of this research goes to researchers in this project. Also, don't hesitate to follow us Twitter And don't forget to join our Subseubdredit 100k + ml and subscribe to Our newsletter.

Sajjad Ansari is a last year's first year of the Kharagpur Iit. As a technology enthusiast, he plunges into AI's practical applications by emphasizing the understanding of the impact of AI technologies and their real implications. It aims to articulate complex AI concepts in a clear and accessible way.
