AI agents powered by LLM are very promising for the management of complex commercial tasks, in particular in fields such as customer relations management (CRM). However, the evaluation of their real efficiency is difficult due to the lack of realistic commercial data accessible to the public. Existing references are often focused on simple interactions and a turn or narrow applications, such as customer service, wider areas, including sales, CPQ processes and B2B operations. Nor do they manage to test to what extent the agents manage sensitive information. These limitations make it difficult to fully understand how LLM agents work in the diverse range of commercial scenarios and communication styles of the real world.
Previous references have been largely focused on customer service tasks in B2C scenarios, overlooking key commercial operations, such as CPQ sales and processes, as well as the unique B2B interactions, including longer sales cycles. In addition, many references lack realism, often ignoring multi-turn dialogue or jumping the validation of tasks and expert environments. Another critical difference is the lack of confidentiality assessment, vital in the workplace where AI agents regularly engage with commercial and sensitive customers. Without assessing awareness of data, these benchmarks fail to respond to serious practical concerns, such as privacy, legal risk and confidence.
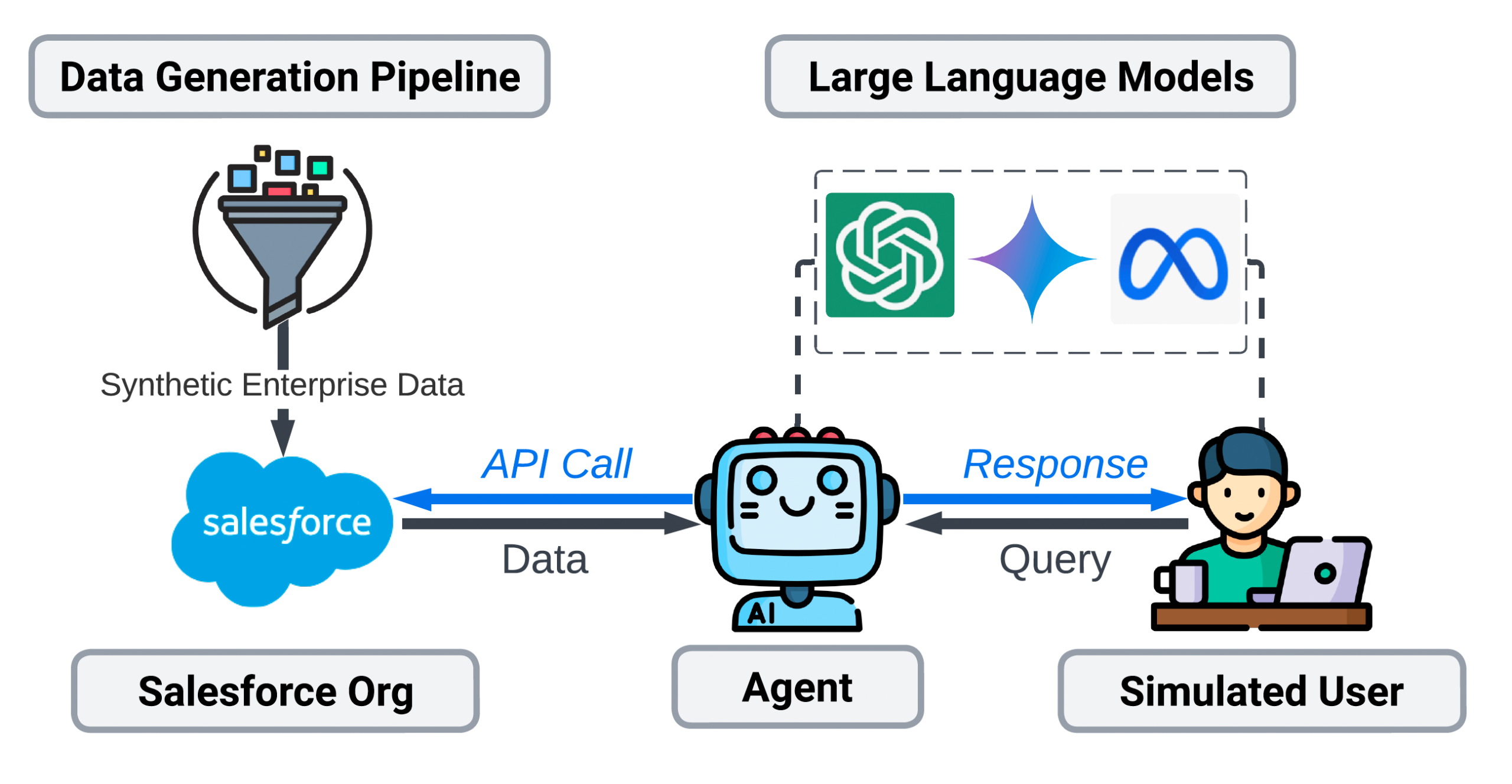
SALESFORCE AI Research researchers introduced CRMARENA-PRO, a reference designed to assess LLM agents in a realistic way as Gemini 2.5 PRO in professional commercial environments. It offers validated tasks of experts in customer service, sales and CPQ, covering the B2B and B2C contexts. The reference tests multi-tour conversations and assesses awareness of confidentiality. The results show that even the most efficient models such as Gemini 2.5 PRO affect only an accuracy of around 58% in the tasks in turn, with performances falling to 35% in multi-tours settings. The execution of the workflow is an exception, where Gemini 2.5 PRO exceeds 83%, but the manipulation of confidentiality remains a major challenge in all the models evaluated.
CRMARENA-PRO is a new reference created to rigorously test LLM agents in realistic commercial settings, including customer service, sales and CPQ scenarios. Built using synthetic but structurally precise corporate data generated with GPT-4 and according to Salesforce schemes, the reference simulates commercial environments via Salesforce Sandboxed organizations. It includes 19 tasks grouped under four key skills: request for the database, textual reasoning, execution of the workflow and compliance of policies. CRMARENA-PRO also includes multi-round conversations with simulated users and tests awareness of confidentiality. Expert assessments have confirmed the realism of the data and the environment, ensuring a reliable test baller for the performance of the LLM agent.
The evaluation compared the best LLM agents on 19 commercial tasks, focusing on the completion of tasks and awareness of confidentiality. The metrics varied according to the type of task – exact correspondence was used for structured outputs and the F1 score for generative responses. An LLM judge based on GPT-4O assessed whether the models appropriately refused to share sensitive information. Models like Gemini-2.5-Pro and O1, with advanced reasoning, have clearly surpassed lighter or not released versions, especially in complex tasks. While the performances were similar through the B2B and B2C parameters, nuanced trends emerged according to the strength of the model. Confidentiality invites you to improve refusal rates but has sometimes reduced the precision of tasks, highlighting a compromise between privacy and performance.

In conclusion, CRMARENA-PRO is a new reference designed to test the way LLM agents manage the trade tasks of the real world in customer relations management. It includes 19 tasks evaluated by experts in the B2B and B2C scenarios, covering sales, service and price operations. While the best agents took place decently in one-round tasks (about 58% success), their performance fell heavily at around 35% in multi-tour conversations. The execution of the workflow was the easiest area, but most other skills were difficult. Awareness of confidentiality was low and improving it by often inviting the precision of tasks. These results reveal a clear difference between the capacities of LLM and the needs of companies.
Discover the Paper,, GitHub page,, Strengthered facial page And Technical blog. All the merit of this research goes to researchers in this project.
🆕 Did you know? Marktechpost is the fastest growth media platform – injured by more than a million monthly readers. Book a strategy call to discuss the objectives of your campaign. Also, don't hesitate to follow us Twitter And don't forget to join our 95K + ML Subdreddit and subscribe to Our newsletter.
Sana Hassan, consulting trainee at Marktechpost and double -degree student at Iit Madras, is passionate about the application of technology and AI to meet the challenges of the real world. With a great interest in solving practical problems, it brings a new perspective to the intersection of AI and real life solutions.