
Large reasoning models (LRM) quickly advanced, with impressive performance in complex problem solving tasks in fields such as mathematics, coding and scientific reasoning. However, current assessment approaches are mainly focused on tests with a single question, which reveals significant limitations. This article presents Rest (assessment of reasoning by simultaneous tests) -A new framework for multi-problem stress tests designed to push LRM beyond the isolated resolution of problems and better reflect their multi-contained reasoning capacities of the real world.
Why current assessment references are below major reasoning models
The most recent benchmarks, such as GSM8K and mathematics, assess the LRM by asking a question at a time. Although effective for the initial development of the model, this approach to isolated questions faces two critical drawbacks:
- Decrease in discriminating power: Many advanced LRMs now obtain almost perfect scores on popular references (for example, Deepseek-R1 reaching 97% accuracy on Math500). These saturated results make the distinction of real model improvements are increasingly difficult, forcing the costly and continuous creation of harder datasets to differentiate capacities.
- Lack of multi-contained real world evaluation: Applications of the real world – such as educational tutoring, technical support or AI multitasking assistants – require reasoning on several questions potentially interfering simultaneously. The tests with a single question do not capture these dynamic and multi-problem challenges which reflect the real cognitive load and the robustness of the reasoning.
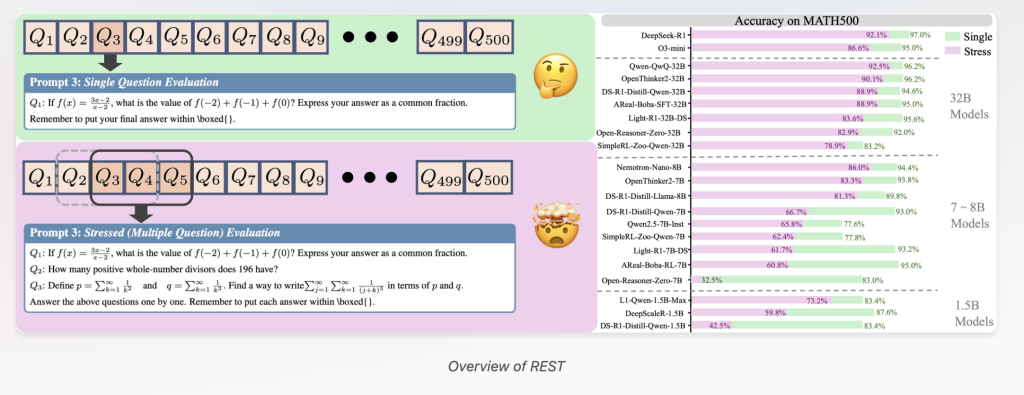
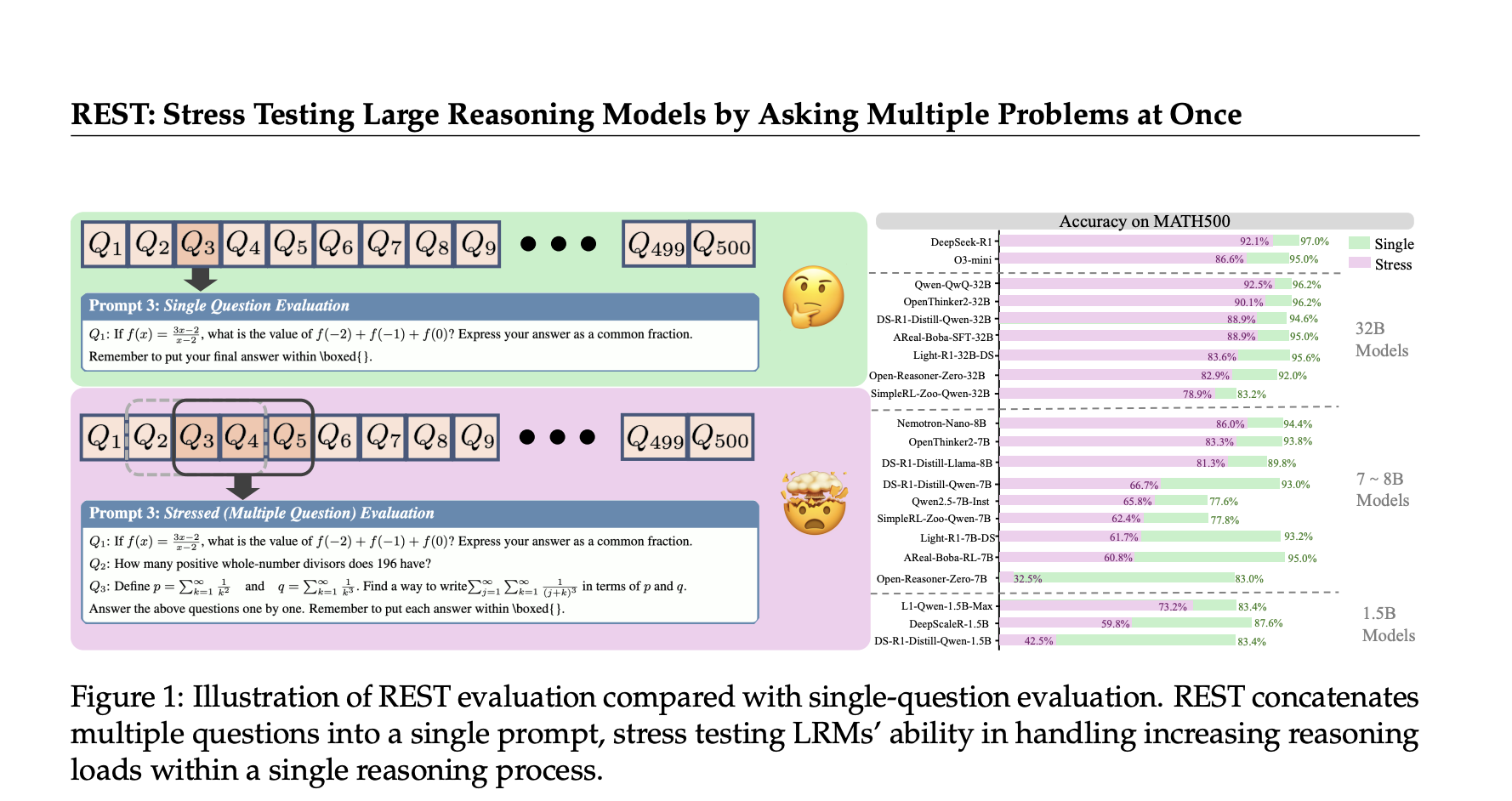
Presentation of rest: TRM at stress test with several problems at the same time

To meet these challenges, researchers at Tsinghua University, Opendatalab, Shanghai AI Laboratory and Renmin University have developed RESTA simple but powerful evaluation method that simultaneously tests the LRM on several questions grouped in a single invite.
- Reference reconstruction to several questions: REST reuses existing landmarks by crushing several questions in a single prompt, by adjusting the stress level Parameter which controls the number of questions presented simultaneously.
- Complete evaluation: Rest assesses critical reasoning skills beyond the basic problem solving – including contextual priority allowance,, Resistance to interference of crossed problemsAnd Dynamic cognitive load management.
- Large applicability: The frame is validated on 34 advanced LRMs ranging from 1.5 billion to 671 billion parameters, tested on 7 various landmarks through different levels of difficulty (from the simple GSM8K to a difficult Like and GPQA).
Rest reveals key ideas on LRM reasoning skills
The rest assessment discovers several revolutionary results:
1. Significant degradation of performance under multi-problem stress
Even Peak lrms As Deepseek-R1 shows the notable accuracy of falls when managing several questions together. For example, the precision of Deepseek-R1 on difficult landmarks as loves24 falls almost 30% under rest compared to the tests of isolated questions. This contradicts the previous hypotheses according to which major language models are intrinsically capable of effortless multitasking through problems.
2.. Improved discriminating power among similar models
Rest considerably amplifies the differences between models with almost identical unique question scores. On Math500, for example:
- R1-7B And R1-32B Reach details with a single narrow question of 93% and 94.6%, respectively.
- Under rest, the precision of R1-7B falls to 66.75% while R1-32B maintains a high 88.97%revealing a Stark 22% performance difference.
Similarly, among models of the same size like Areal-Boba-RL-7B and OpenHinker2-7b, Rest Capture of significant differences in multi-problem manipulation capacities that the unique question evaluations mask.
3. Post-training methods may not guarantee robust multi-problems reasoning
The refined models of learning by strengthening or supervised adjustment on reasoning to a single problem often do not manage to preserve their advantages in the multi-question framework of REST. This calls for rethinking training strategies to optimize the robustness of reasoning in realistic multi-context scenarios.
4. The “Long2Short” training improves performance under stress
Models formed with “Long2Short” techniques – which encourages concise and effective reasoning chains – maintain higher precision under rest. This suggests that a promising avenue for the design of models better suited to simultaneous multi-problems.
How rest stimulates realistic reasoning challenges
By increasing the cognitive load On the LRM thanks to the presentation of simultaneous problems, REST simulates real world demands when reasoning systems must be dynamically prioritized, avoid thinking too much about a problem and resist interference of simultaneous tasks.
Rest also systematically analyzes the types of error, revealing current failures such as:
- Question omission: Ignore subsequent questions in a multi-question prompt.
- Summary errors: Incorrectly summarizing the answers between problems.
- Reasoning errors: Logical or calculation errors in the reasoning process.
These nuanced ideas are largely invisible in unique question assessments.
Practical evaluation configuration and reference cover
- REST evaluated 34 lrms covering the sizes of Parameters from 1.5b to 671b.
- The benchmarks tested include:
- Simple: GSM8K
- AVERAGE: MATH500, AMC23
- Stimulating: Loves24, love25, gpqa diamond, livecodebench
- Model generation parameters are defined according to official guidelines, with output token limits 32K for reasoning models.
- The use of the standardized OpenCompass toolbox ensures consistent and reproducible results.

Conclusion: Rest as a realistic and realistic LRM assessment paradigm
Rest is a leap forward in the evaluation of large models of reasoning by:
- Approach the reference saturation: Revitalize existing data sets without expensive complete replacements.
- Reflecting the multi-tasted requirements of the real world: Test models under realistic and high cognitive load conditions.
- Guide the development of the model: Underlines the importance of training methods like Long2Short to alleviate the outset and encourage the objective of adaptive reasoning.
In short, REST opens the way to a more reliable, robust and relevant comparative analysis analysis to the applications of new generation AI reasoning systems.
Discover the Paper,, Project page And Code. All the merit of this research goes to researchers in this project. Subscribe now to our newsletter IA

Sajjad Ansari is a last year's first year of the Kharagpur Iit. As a technology enthusiast, he plunges into AI's practical applications by emphasizing the understanding of the impact of AI technologies and their real implications. It aims to articulate complex AI concepts in a clear and accessible way.