The growing need for evolving reasoning models in the machine intelligence
Advanced reasoning models are on the border of machine intelligence, in particular in fields such as solving mathematical problems and symbolic reasoning. These models are designed to carry out calculations in several stages and logical deductions, often generating solutions that reflect human reasoning processes. Reinforcement learning techniques are used to improve precision after pre-training; However, the scaling of these methods while retaining efficiency remains a complex challenge. While demand increases for smaller and more economical models in resources that always have high reasoning capacities, researchers are now turning to strategies that approach the quality of the data, exploration methods and the generalization of the long -term context.
Challenges in learning strengthening for important reasoning architectures
A persistent problem of learning to strengthen for large -scale reasoning models is the inadequacy between model capacities and the difficulty of training data. When a model is exposed to too simple tasks, its learning curve stagnates. Conversely, too difficult data can overcome the model and do not give any learning signal. This difficulty imbalance is particularly pronounced when applying recipes that work well for small models to the largest. Another problem is the lack of methods to effectively adapt the diversity of deployment and the length of exit during training and inference, which limits the reasoning capacities of a model on complex references.
Limits of existing post-training approaches to advanced models
Previous approaches, such as Deepscaler and GRPO, have shown that learning to strengthen can improve the performance of small -scale reasoning models with as little as 1.5 billion parameters. However, the application of these same recipes to more capable models, such as Qwen3-4B or Deepseek-R1-Distill-Qwen-7b, only leads to marginal gains or even performance drops. A key limitation is the static nature of data distribution and the limited diversity of sampling. Most of these approaches do not filter the data according to the capacity of the model, and they adjust the sampling temperature or the response length over time. Consequently, they often fail to evolve effectively when used on more advanced architectures.
POLARIS Presentation: a tailor -made recipe for an evolving RL in reasoning tasks
Researchers from the University of Hong Kong, Bytedance Seed and Fudan University have introduced Polaris, a post-training recipe specifically designed to scale the learning of strengthening for advanced reasoning tasks. Polaris includes two preview models: Polaris-4B-Preview and Polaris-7B-Preview. Polaris-4B-PREVIEW is refined from QWEN3-4B, while Polaris-7B-PREVIEW is based on Deepseek-R1-Distill-QWEN-7B. Researchers focused on creating an agnostic model model that changes data difficulty, encourages a diversified exploration through controlled sampling temperatures and extends the inference capacities by length extrapolation. These strategies have been developed using open source data sets and training pipelines, and the two models are optimized to run on consumer quality graphics units (GPU).
Polaris Innovations: balancing difficulty, controlled sampling and long context inference
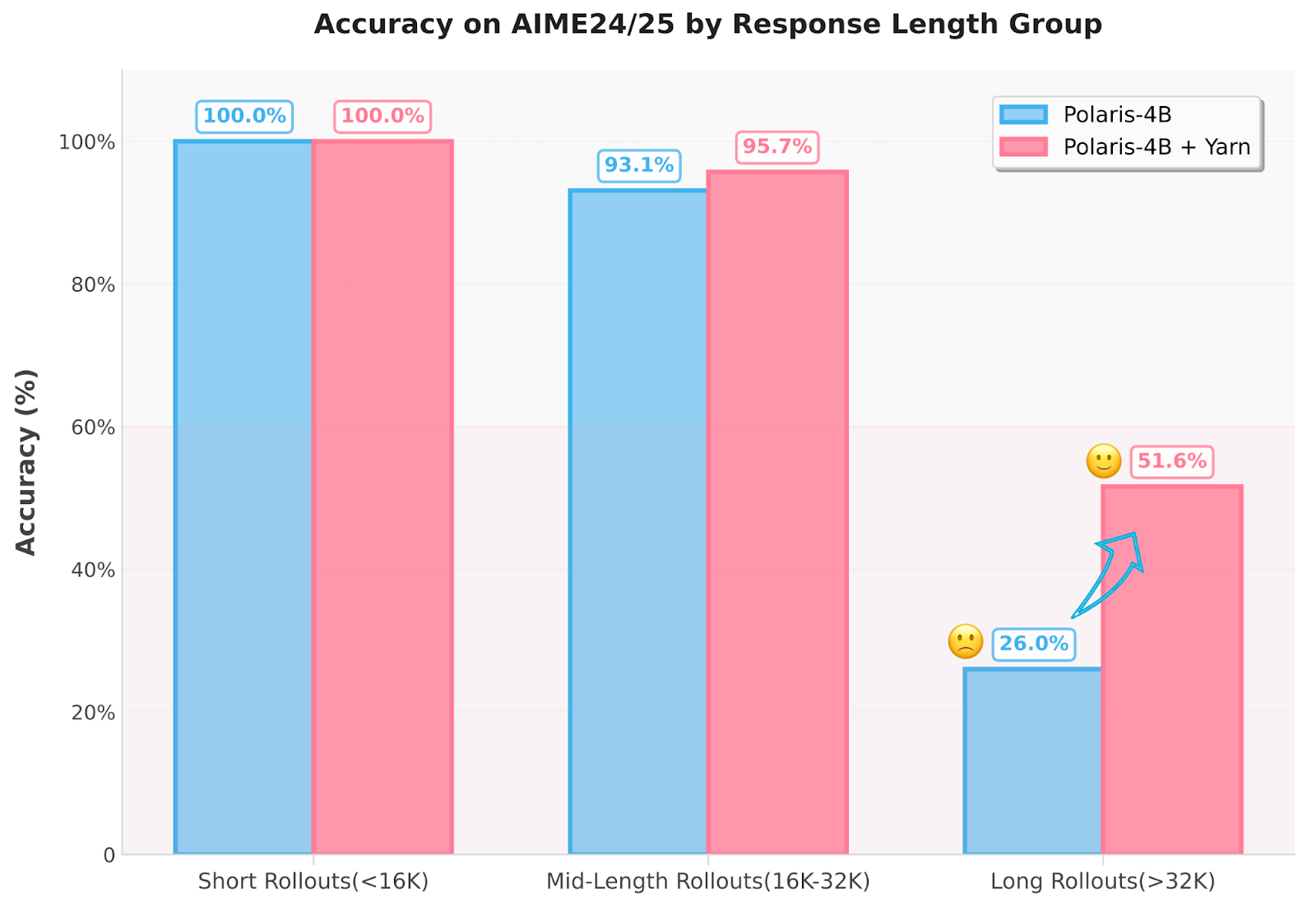
Polaris implements several innovations. First, the training data is organized by deleting problems which are either too easy or insoluble, creating a distribution of difficulty in the form of a mirror. This ensures that training data is evolving with model growth capabilities. Second, researchers dynamically adjust the sampling temperature between the drive stages, using 1.4, 1.45 and 1.5 for Polaris-4B and 0.7, 1.0 and 1.1 for Polaris-7B-to maintain the diversity of deployment. In addition, the method uses an extrapolation technique based on the wire to extend the duration of the context of inference to 96k tokens without requiring additional training. This deals with the ineffectiveness of long sequence training by allowing a “train short and testing” approach. The model also uses techniques such as the deployment rescue mechanism and intra-lot informative substitution to prevent zero reward lots and ensure that the useful training signals are kept, even when the deployment size is maintained small at 8.
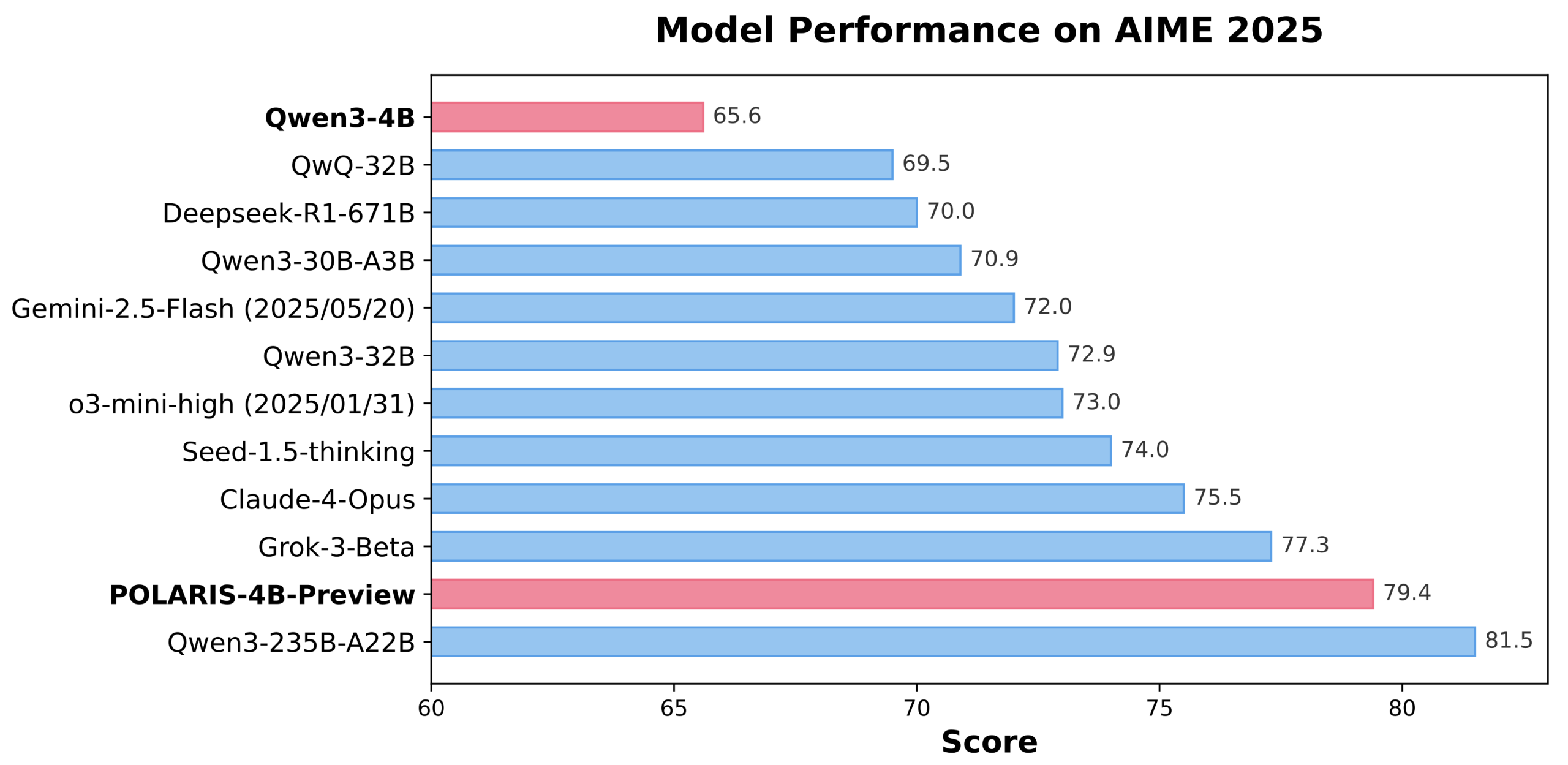
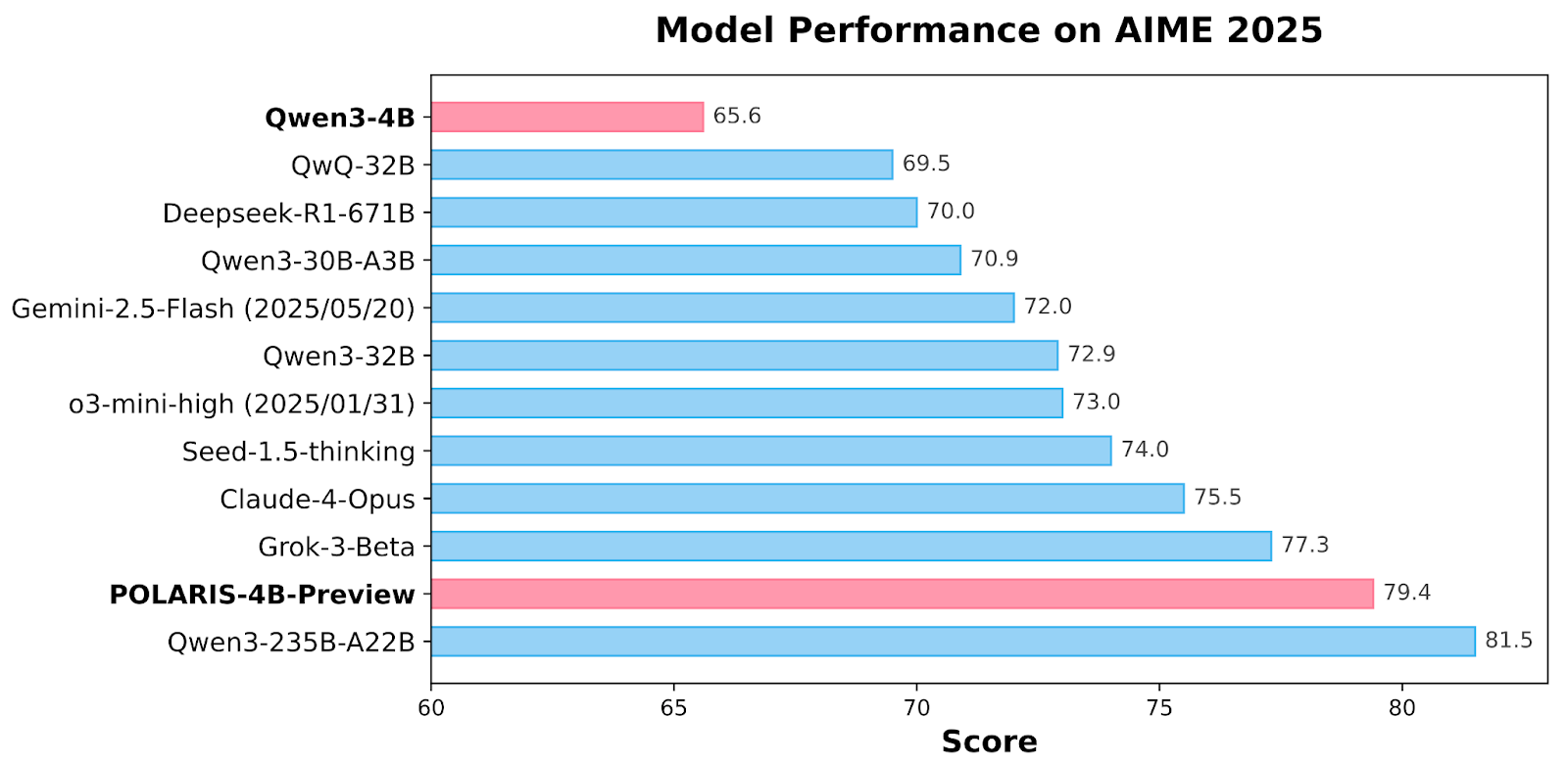
Reference results: Polaris surpasses larger commercial models
The Polaris models obtain state -of -the -art results on several mathematical landmarks. Polaris-4B-PREVIEW recorded 81.2% precision on AIME24 and 79.4% on AIME25, even surpassing QWEN3-32B on the same tasks while using less than 2% of its parameters. It marks 44.0% on Minerva mathematics, 69.1% on the Olympiad bench and 94.8% on AMC23. Polaris-7B-Preview also works strongly, marking 72.6% on AIME24 and 52.6% on AIME25. These results demonstrate a coherent improvement compared to models such as Claude-4-OPus and Grok-3-Beta, establishing Polaris as a competitive and light model which fills the performance gap between small open models and 30B +commercial models.
Conclusion: effective learning of strengthening through intelligent post-training strategies
The researchers have shown that the key to the scale of reasoning models is not only a larger model size, but an intelligent control over the difficulty of training data, the diversity of sampling and the length of inference. Polaris offers a reproducible recipe that effectively listens to these elements, allowing smaller models to compete with the reasoning capacity of massive commercial systems.
Discover the Model And Code. All the merit of this research goes to researchers in this project. Also, don't hesitate to follow us Twitter And don't forget to join our Subseubdredit 100k + ml and subscribe to Our newsletter.
Nikhil is an intern consultant at Marktechpost. It pursues a double degree integrated into materials at the Indian Kharagpur Institute of Technology. Nikhil is an IA / ML enthusiast who is still looking for applications in fields like biomaterials and biomedical sciences. With a strong experience in material science, he explores new progress and creates opportunities to contribute.
