
Introduction: the need for an effective RL in LRM
The RL of reinforcement learning is increasingly used to improve LLM, in particular for reasoning tasks. These models, known as large models of reasoning (LRM), generate intermediate “reflection” stages before providing final responses, thus improving performance on complex problems such as mathematics and coding. However, the formation of LRM with large -scale RL is difficult due to the need for massive parallelization and an effective design of the system. Current systems are often based on synchronous lots treatment, where generation must wait for the longest output of a lot to be finished, leading to the sub-utilization of the GPU. Even more recent methods are always faced with bottlenecks, as they use obsolete deployments but remain based on a lot.
Context: learning to strengthen RL's impact on LLM reasoning capacities
The strengthening of RL learning has become a widely used strategy to improve LLM reasoning capacities, in particular for tasks with clearly defined reward signals, such as mathematics, coding, scientific reasoning and the use of tools. These models generally improve by extending their reasoning into a chain of thoughts during training. Open source efforts have shown that distilled and distilled models can also work well on such tasks. The methods of asynchronous RL, proven effective in games, have recently been explored for LLM, but mainly in short context or limited overlap scenarios. Previous work has also studied strategies, such as partial deployments, to improve efficiency while maintaining the stability of training.
System presentation: Introduction
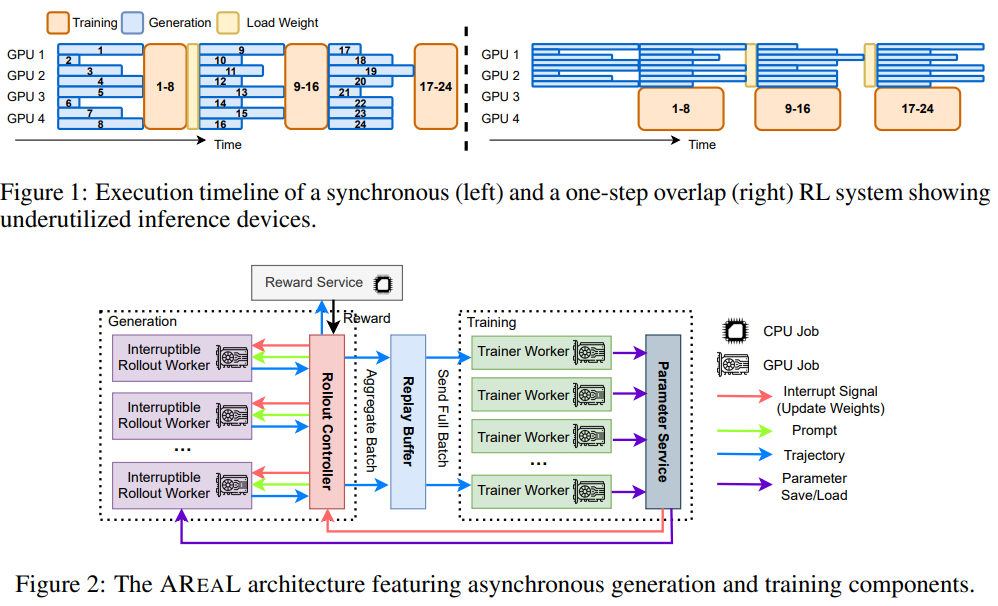
Researchers from IIIS, Tsinghua University, Anti and HKUST research introduce Areal, a fully asynchronous strengthening learning system designed to more effectively form reasoning models. Unlike traditional synchronous systems, Areal separates generation and training processes; Deployment workers continuously produce outings, while training workers update the model in parallel as new data arrive. This design improves the use of the GPU and accelerates the training. To manage data stability, Areal uses a tailor -made PPO version and incorporates optimizations such as dynamic lots and parallel reward services. On mathematical tasks and code, Areal reaches up to 2.77 × faster training while maintaining or improving the performance of the final model.
Technical architecture: key components and optimizations
Areal is designed to decouple generation and training through separate GPU clusters, improvement of scalability, material efficiency and flexibility in learning to strengthen large models. The system includes four main components: deployment workers who support the interrupted generation and updates of the model, a reward service that assesses the responses, workers of trainers who perform PPO updates and a controller who coordinates the data flow. To meet challenges such as data sta -room and incoherent political versions, Areal uses conscious training of stability and a decoupled PPO objective. In addition, system optimizations such as pipelée-GPU operations, non-blocking asynchronous requests and dynamic sequence packaging improves the training speed and the efficiency of the GPU.
Experimental results: scale and performance
Areal was tested on mathematical and coding tasks using Qwen2 models distilled with different sizes. He carried out 2 to 3 times a faster formation than previous methods, such as Deepscaler and Deepcoder, while maintaining comparable precision. The system evolves effectively through GPUs and manages long context lengths (up to 32k tokens), outperforming the design functionalities of the keys to synchronous methods such as interrupable generation and dynamic microbatchage, which increases the speed of training and the use of equipment. Algorithmically, the decoupled PPO objective of Areal allows stable learning even with outdated data, unlike standard PPO. Overall, the speed of the sales in terms and performance effectively, which makes it well suited to the large -scale RL formation of language models.
Conclusion: Advance RL on a large scale for language models
In conclusion, Areal is an asynchronous reinforcement learning system designed to improve the efficiency of LLM training, in particular for tasks such as coding and mathematical reasoning. Unlike traditional synchronous methods that await all outings before updating, Areal allows generation and training to perform in parallel. This decoupling reduces the inactivity time of the GPU and increases the flow. To ensure that learning remains stable, Areal introduces conscious strategies of the stalnet and a modified PPO algorithm that effectively manages older training data. Experiences show that it offers up to 2.77 times faster training than synchronous systems, without sacrificing precision, marking a step forward in reducing RL for large models.
Discover the Paper And GitHub page. All the merit of this research goes to researchers in this project. Also, don't hesitate to follow us Twitter And don't forget to join our Subseubdredit 100k + ml and subscribe to Our newsletter.
Sana Hassan, consulting trainee at Marktechpost and double -degree student at Iit Madras, is passionate about the application of technology and AI to meet the challenges of the real world. With a great interest in solving practical problems, it brings a new perspective to the intersection of AI and real life solutions.
