
Great language models (LLM) based on diffusion are explored as a promising alternative to traditional self-regressive models, offering the potential of a simultaneous multi-token generation. By using two -way attention mechanisms, these models aim to accelerate decoding, theoretically providing faster inference than self -regressive systems. However, despite their promise, diffusion models often fight in practice to offer competitive inference speeds, thus limiting their ability to match the real world performance of LLM of large self -regressive language models.
The main challenge lies in the ineffectiveness of inference in LLM based on diffusion. These models generally do not support the key value cache mechanisms (KV), which are essential to accelerate inference by reusing the previously calculated states of attention. Without KV cache, each new generation step in the diffusion models repeats the computing comprehensive attention, which makes them intensive in calculation. In addition, when decoding multiple tokens simultaneously – a key characteristic of diffusion models – the quality of the generation often deteriorates due to the disturbances of token outbuildings under the hypothesis of conditional independence. This makes dissemination models unreliable for practical deployment despite their theoretical forces.
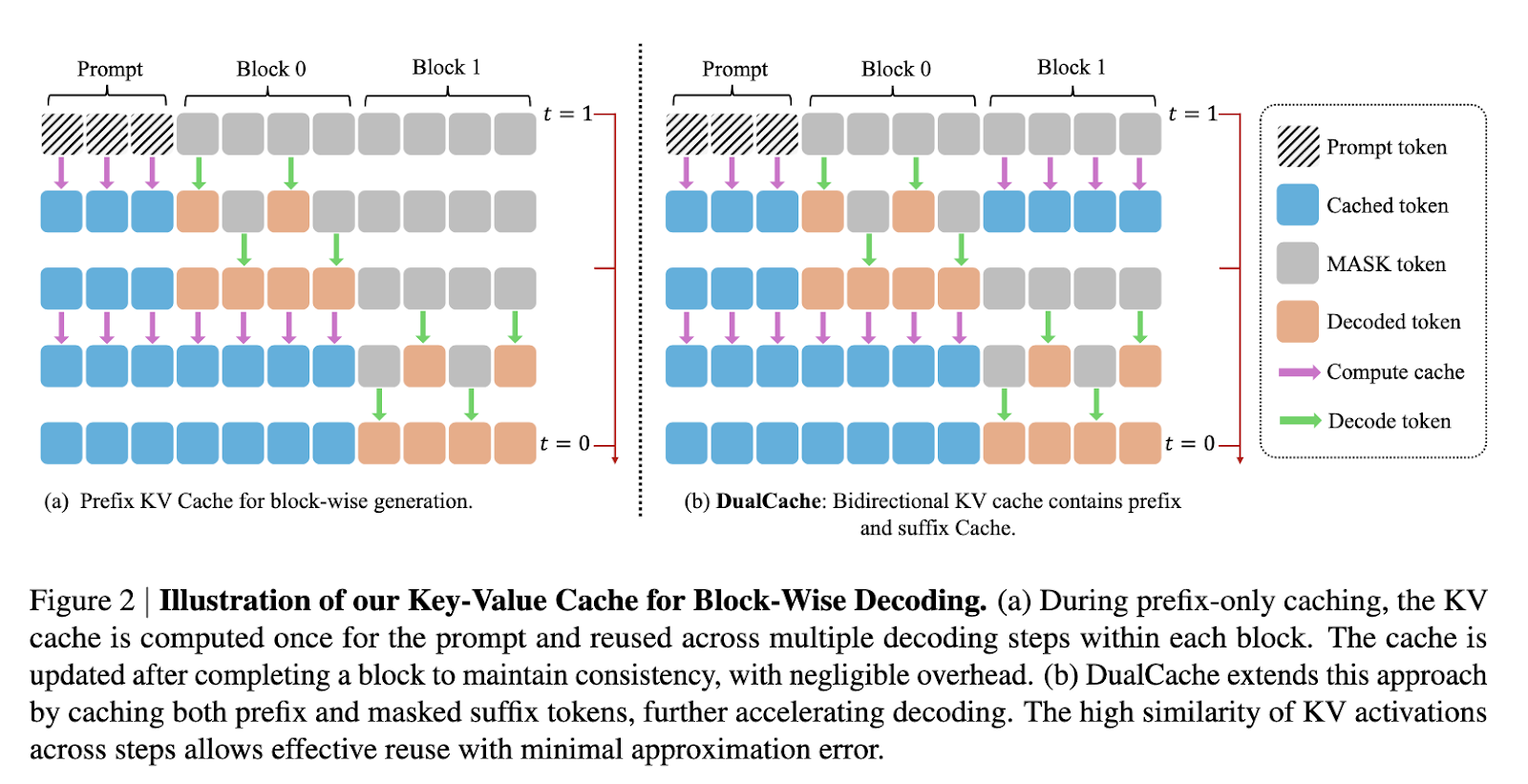
Attempts to improve the LLM of diffusion have focused on strategies such as generation by block and partial cache. For example, models such as Llada and Dream incorporate masked diffusion techniques to facilitate multi-Token generation. However, they still do not have an effective key value (KV) (KV) and parallel decoding system in these models often leads to incoherent outings. While certain approaches use auxiliary models to approximate token outbuildings, these methods introduce additional complexity without fully solving underlying performance problems. Consequently, the speed and quality of the generation in the LLMS diffusion continue to delay on the self -regressive models.
Researchers from NVIDIA, the University of Hong Kong and MIT introduced Fast-DLLM, a framework developed to respond to these limits without requiring recycling. Fast-DLLM provides two innovations to LLMS diffusion: an approximate block cache mechanism and a parallel decoding strategy sensitive to confidence. The approximate KV cover is adapted to the bidirectional nature of the diffusion models, allowing to effectively reuse the activations of the previous decoding steps. The parallel decoding of confidence selectively decodes tokens based on a confidence threshold, reducing errors which arise from the hypothesis of the independence of the tokens. This approach offers a balance between the speed and quality of the generation, making it a practical solution for text generation tasks based on diffusion.
The KV Method of Fast-DLLM is implemented by dividing the block sequences. Before generating a block, KV activations for other blocks are calculated and stored, allowing reuse during the following decoding steps. After generating a block, the cache is updated on all tokens, which minimizes computing redundancy while maintaining precision. The Dualcache version extends this approach by cache both prefix and suffix tokens, taking advantage of a strong similarity between the adjacent inference stages, as evidenced by the thermal similarities in cosine in the paper. For the parallel decoding component, the system assesses the confidence of each token and only decodes those exceeding a defined threshold. This prevents violations of the dependence on simultaneous sampling and guarantees a better generation even when several tokens are decoded in a single step.

The rapid DLLM has made significant improvements in performance in reference tests. On the GSM8K data set, for example, it achieved an acceleration of 27.6 × on the basic models in configurations at 8 strokes at a generation length of 1024 tokens, with a precision of 76.0%. On the mathematical reference, an acceleration of 6.5 × was carried out with an accuracy of approximately 39.3%. The Humaneval reference experienced an acceleration of 3.2 × with precision maintained at 54.3%, while on MBPP, the system reached an acceleration of 7.8 × at a generation length of 512 tokens. In all tasks and models, precision has remained less than 1 to 2 points on the base line, showing that the acceleration of fast-DLLM does not significantly degrade the output quality.
The research team actually addressed the basic strangulation bottlenecks in the LLM based on the diffusion by introducing a new cache strategy and a confidence -based decoding mechanism. By approaching the ineffectiveness of inference and improving the quality of the decoding, Fast-DLLM shows how LLMS diffusion can approach or even exceed self-regressive models in speed while maintaining great precision, which makes them viable for deployment in applications of generation of real languages.
Discover the Paper And Project page . All the merit of this research goes to researchers in this project. Also, don't hesitate to follow us Twitter And don't forget to join our 95K + ML Subdreddit and subscribe to Our newsletter.
Nikhil is an intern consultant at Marktechpost. It pursues a double degree integrated into materials at the Indian Kharagpur Institute of Technology. Nikhil is an IA / ML enthusiast who is still looking for applications in fields like biomaterials and biomedical sciences. With a strong experience in material science, he explores new progress and creates opportunities to contribute.
