Estimated reading time: 5 minutes
Introduction
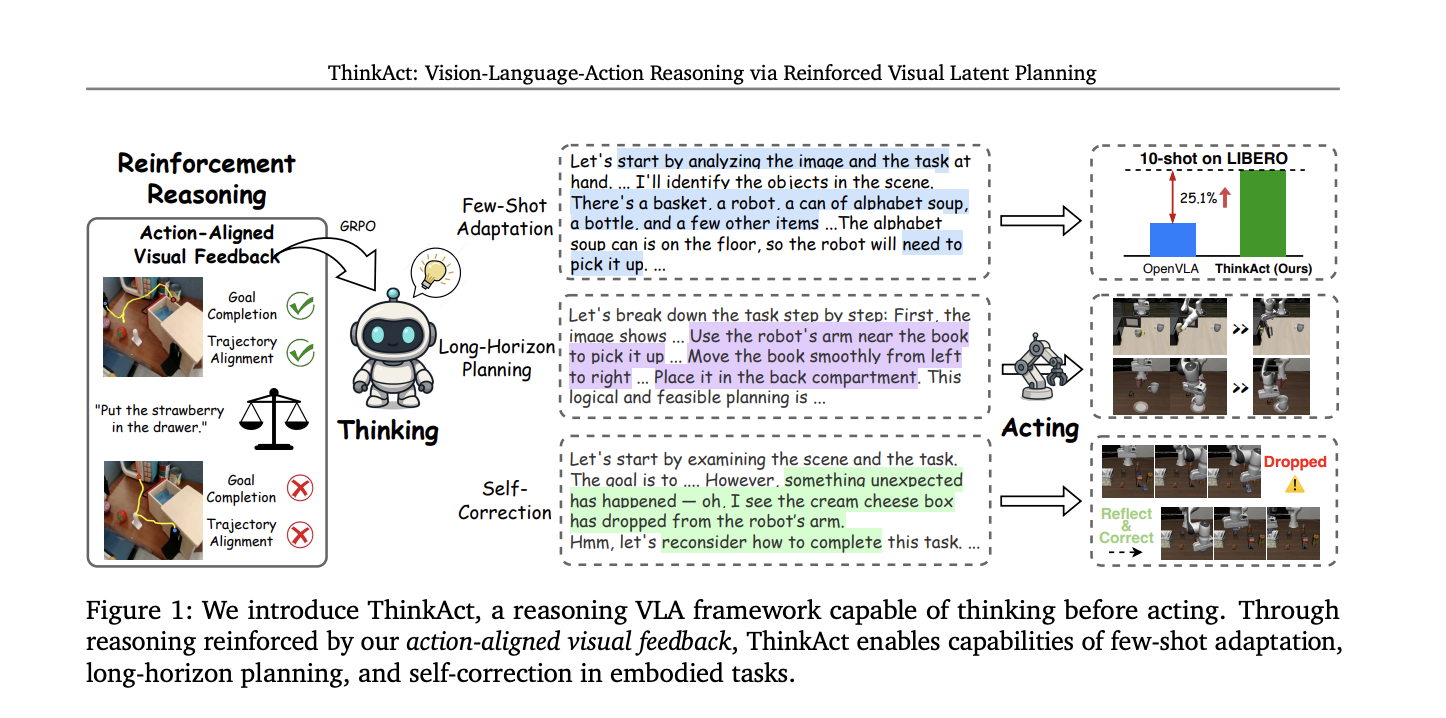
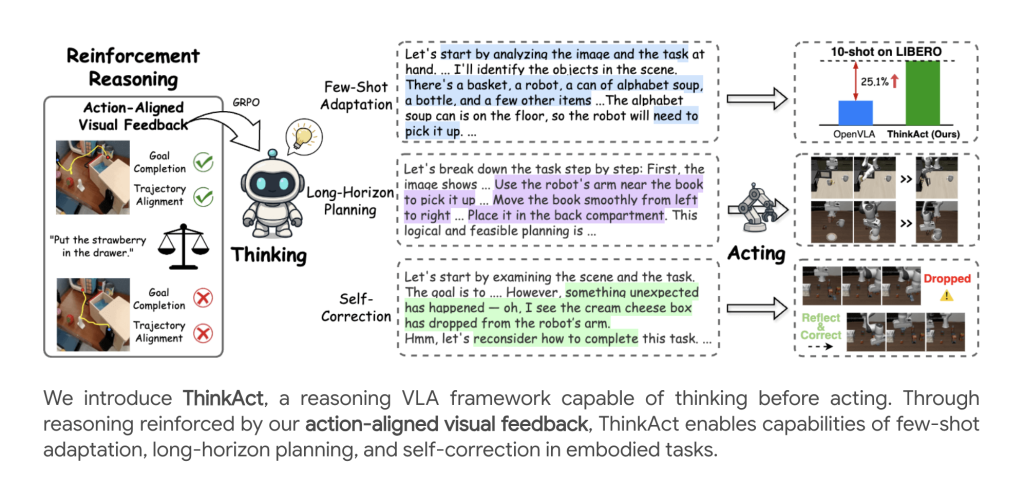
Incarnate AI agents are increasingly called upon to interpret complex multimodal instructions and act robustly in dynamic environments. Thinkactorpresented by researchers from Nvidia and the National University of Taiwan, offers a breakthrough for Reasoning of vision-action (VLA)Introducing reinforced Visual latent planning To fill the high -level multimodal reasoning and control of low -level robots.
Typical VLA models directly map the visual and raw language inputs through actions through end -to -end training, which limits reasoning, long -term planning and adaptability. Recent methods have started to incorporate the intermediary Chain of thoughts (COT) Reasoning or attempted optimization based on RL, but has fought with scalability, earth setting or generalization when faced with very variable and long-horizon robotic manipulation tasks.
The Thinkant Framework
Double system architecture
Thinkact consists of two closely integrated components:
- Multimodal LLM reasoning (MLLM): Performs structured reasoning and step by step on visual scenes and language instructions, taking out a latent visual plan This code for high -level intention and the planning context.
- Action model: A strategy based on a latent visual transformer, performing the decoded trajectory as a robot in the environment.
This design allows asynchronous operation: The LLM “thinks” and generates plans to a slow cadence, while the action module performs fine grain control at a higher frequency.
Reinforced visual latent planning
A basic innovation is the Reinforcement learning approach (RL) draw visual awards aligned with action::
- Objective reward: Encourages the model to align the predicted start and end positions in the plan with those of the demonstration trajectories, supporting the completion of the objectives.
- Trajectory reward: Regularizes the visual trajectory provided to closely correspond to the distribution properties of expert demonstrations using the dynamic time deformation distance (DTW).
The total RRR reward mixes these visual rewards with an accuracy score of the format, pushing the LLM not only to produce precise responses, but also plans which result in physically plausible robot actions.
Training pipeline
The training procedure in several stages includes:
- Supervised end adjustment (SFT): Cold start with manually annotated visual trajectory and QA data to teach the prediction, reasoning and formatting of the trajectory trajectory.
- Reinforced fine taune: Optimizing the RL (using the relative optimization of the relative policy, GRPO) still encourages high quality reasoning by maximizing the rewards aligned with newly defined action.
- Action adaptation: The downstream action policy is formed using imitation learning, taking advantage of the release of the Latent Frozen plan from LLM to guide control in various environments.
Inference
At the time of inference, given an observed scene and linguistic instruction, the reasoning module generates a latent visual plan, which then conditions the action module to execute a complete trajectory – allowing robust performance even in new previously invisible parameters.

Experimental results
Robot manipulation benchmarks
Experiences on Simple And Libero The references demonstrate Thinkact's superiority:
- Simplerenv: Surpass the strong basic lines (for example, Openvla, dit-Policy, Tracevla) from 11 to 17% in various contexts, in particular in long and visually diverse tasks.
- Libero: Reached the highest overall success rates (84.4%), excelling in space challenges, objects, objectives and long horizon, confirming its ability to generalize and adapt to new skills and arrangements.

Embodied reasoning benchmarks
On EGOPLAN-BENCH2,, RobovqaAnd OpenThinkact demonstrates:
- Higher planning precision in several stages and long-horizon.
- The QA scores based on blue and highlighting, reflecting a better semantic understanding and the earth for visual response tasks.
Adaptation to a few strokes
Thinkact allows effective Adaptation to a few strokes: With as little as 10 demonstrations, he achieves substantial success rate gains on other methods, highlighting the power of planning guided by reasoning to quickly learn new skills or environments.
Self-reflection and correction
Beyond the success of tasks, Thinkantact exhibit emerging behaviors::
- Detection of failure: Recognizes execution errors (for example, deleted objects).
- Recentment: Automatically revises the plans to recover and finish the task, thanks to the reasoning on recent visual input sequences.
Ablation studies and model analysis
- Reward ablations: Both aim And path Rewards are essential for structured planning and generalization. The abolition is to considerably lower performance and to rely only on QA style rewards limits reasoning capacity in several stages.
- Reduction of the update frequency: Thinkact reaches a balance between reasoning (slow, planning) and action (rapid, control), allowing robust performance without excessive calculation demand1.
- Smaller models: The approach becomes widespread in smaller MLLM squeries, maintaining solid reasoning and action capacities.
Details of the implementation
- Main dynamic thorn: Qwen2.5-VL 7B MLLM.
- Data sets: Various robot and human demonstration videos (X-Embodiment Open, something V2), as well as multimodal QA sets (Robovqa, Egoplan-Bench, Video-R1-Cot, etc.).
- Use a vision encoder (Dinov2), a text encoder (clip) and a Q -trainer to connect the reasoning output to the action strategy input.
- Experienced experiences on real and simulated parameters confirm scalability and robustness.
Conclusion
NVIDIA Thinkact establishes a new standard for IA agents embodiedproving that Reinforced visual latent planning—I that agents “think before they act” – robust, evolving and adaptive performance in complex tasks of complex, real and manipulation of the robot. Its double system design, its formatting of strong rewards and its empirical results open the way to intelligent and generalist robots capable of planning on horizon, a few strokes and a correction of self-correction in various environments.
Discover the Paper And Project. All the merit of this research goes to researchers in this project. Also, don't hesitate to follow us Twitter And don't forget to join our Subseubdredit 100k + ml and subscribe to Our newsletter.
You can also love Nvidia Open Cosmos Diffusionrender (Check it now)
Nikhil is an intern consultant at Marktechpost. It pursues a double degree integrated into materials at the Indian Kharagpur Institute of Technology. Nikhil is an IA / ML enthusiast who is still looking for applications in fields like biomaterials and biomedical sciences. With a strong experience in material science, he explores new progress and creates opportunities to contribute.
