Extremely long management of documents remains a persistent challenge for models of large languages (LLM). Even with techniques such as length extrapolation and clear attention, models often suffer from degradation of high performance and calculation costs. To remedy this, researchers from Bytedance Seed and Tsinghua University present SomersaultA memory agent based on strengthening learning designed to allow long -context treatment with linear complexity and minimum performance loss.
Limits of existing approaches
Current solutions for long context modeling are transformed into three main categories:
- Length extrapolation methods (For example, NTK, PI, Yarn, DCA): extend the context window via position integration manipulations. However, they are often faced with degradation and performance scaling problems.
- Sparse and linear attention mechanisms: Reduce the complexity of attention to O (N) but generally require recycling from zero and count on fixed models or rules defined by humans.
- Context compression: Use memory modules at the tokens or external to condense long entrances but often disturb the standard generation and fight with extrapolation.
These approaches fail to deliver the three critical attributes: support for arbitrary entry length, coherent precision and efficient linear complexity.
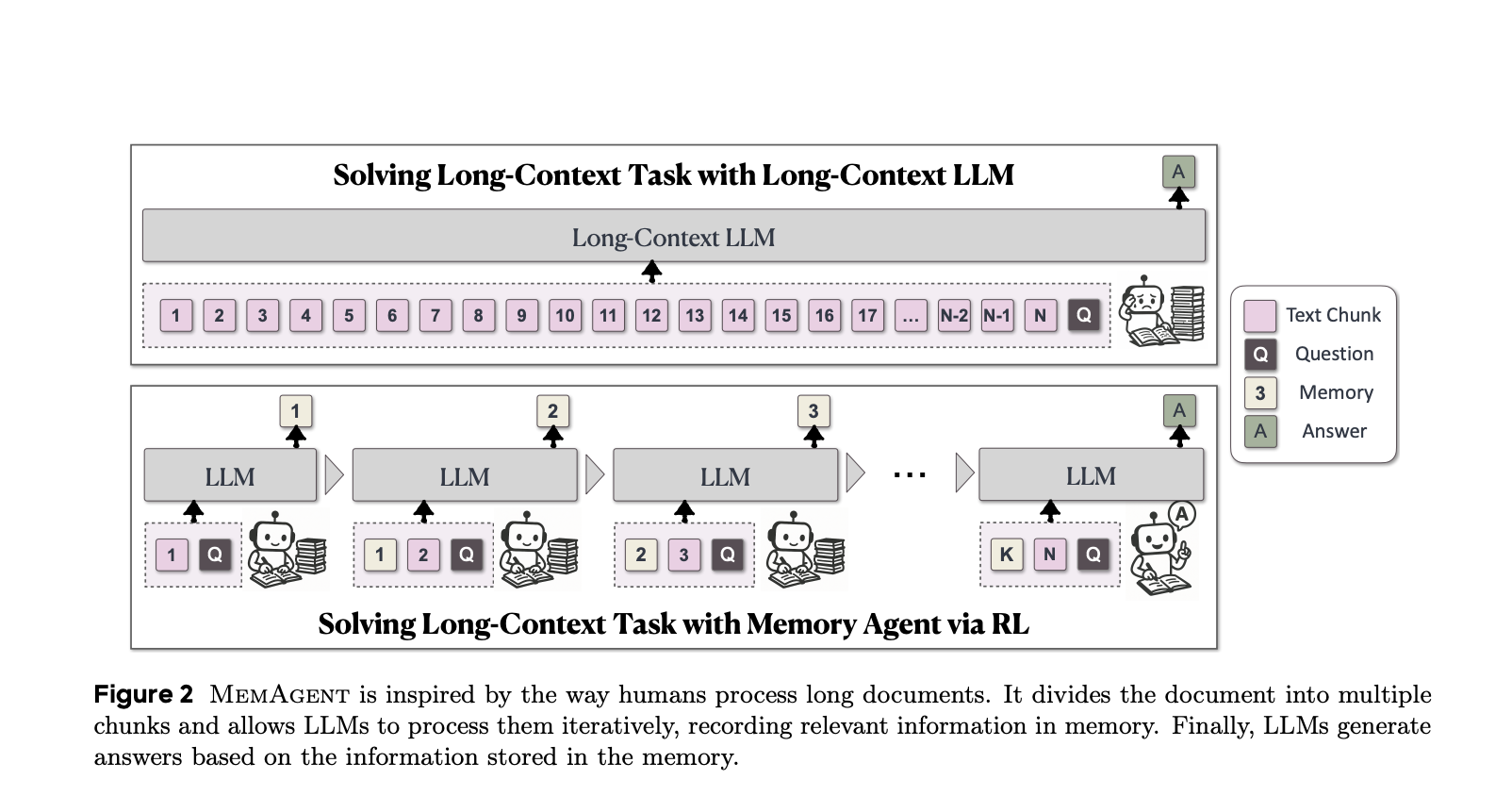
Memagent: human -type memory strategy
Inspired by the way humans summarize key information while ignoring noise, Memagent treats seizures as a flow of evidence. At each stage, he reads a piece of document and an internal memory, crushing the latter with a updated and compressed context.
Key innovations:
- Token memory with fixed length: Compresses essential information while maintaining the compatibility of the model.
- Crushing mechanism in terms of segments: Supports infinite text lengths without growing from memory.
- Linear complexity: Updating the memory and the decoding cost remain constant per piece.

RL Multi-Rev training with GRPO
Memagent deals with each interaction of document pieces as an independent dialogue. It is trained via Optimization of the relative group policy (GRPO) in a multi-conversation RL pipeline called DapoActivation of memory update focused on the reward.

Key elements include:
- Rules -based verifier: Calculate the rewards of the results by comparing the model's responses with several ground truths.
- RL signal at the token level: Applied uniformly through conversations from a sample.
This configuration encourages the compression of memory focused on relevant information and relevant distractors.
Performance assessment
Using the reference sets and the synthetic data sets of the Hotpotqa and Squad rule, Memagent was formed with a context window 8K and extrapolated up to 3.5 million tokens.
| Model | 224K | 896K | 3.5 m |
|---|---|---|---|
| Qwen2.5-Instruct-14b-1m | 37.5% | 0.0% | N / A |
| Qwenlong-L1-32B | 17.2% | 11.7% | N / A |
| RL-MAGENT-14B | 81.3% | 77.3% | 78.1% |
Memagent has maintained an accuracy of more than 95% on the references of the rules (8k to 512K) and systematically outperformed the basic lines in long context context and based on distillation.

Case study: Multi-hop QA
Since the question “the director of the romantic comedy” Big Stone Gap “is based in what New York?”, Memagent gradually followed the relevant content on 3 songs:
- Recognized unrelated contents but has retained location information.
- Maintained memory against unrelevant pieces.
- Memory properly updated when meeting the biography of Adriana Trigiani.
Final response: Greenwich Village, New York City.
Theoretical foundation and complexity
Memagent reformulates the self -regressive model using latent memory variables (M₁… Mₖ):
P (x₁: n) = ∑ₘ₁: ₖ ∏ₖ p (cₖ | mₖ₋₁) * P (mₖ | cₖ, mₖ₋₁)
This allows the calculation cost o (N) and the intermediate memory readable by humans – unlike the compression of the characteristics based on attention. RL is essential, because memory updates are discreet and cannot be learned via retro-propagation.
Conclusion
Memagent offers an evolutionary and effective solution to the long context trilemma: unlimited entry length, precision almost without loss and linear complexity. Its RLM -based crushing memory mechanism allows LLMs to read, abstraction and generate on inputs of several million people without architectural modification.
Faq
Q1: What is Memagent?
Memagent is a framework based on strengthening learning that equips LLMS with memory tokens to effectively manage extremely long contexts.
Q2: How is it different from the methods of attention or extrapolation?
Unlike scaling or extrapolation techniques based on attention, Memagent uses memory based on updated tokens via strengthening learning.
Q3: What can be applied to?
All LLM based on the transformer. No modification of the architecture of the model is required.
Q4: How is it evolving with the size of the entrance?
It maintains the linear calculation complexity regardless of the input length by fixing the size of the memory.
Q5: What are the applications of Memagent?
Qa with long document, agent's memory systems, review of legal documents, analysis of scientific literature and real -time decision -making with important evidence.
Discover the Paper. All the merit of this research goes to researchers in this project.
Sponsorship opportunity: Reach the most influential AI developers in the United States and Europe. 1M + monthly players, 500K + community manufacturers, endless possibilities. (Explore sponsorship)

Sajjad Ansari is a last year's first year of the Kharagpur Iit. As a technology enthusiast, he plunges into AI's practical applications by emphasizing the understanding of the impact of AI technologies and their real implications. It aims to articulate complex AI concepts in a clear and accessible way.