Estimated reading time: 5 minutes
Introduction to Langgraph
Langgraph is a powerful Langchain frame designed to create multi-actor applications with state with LLMS. It provides the structure and the tools necessary to build sophisticated AI agents via an approach based on a graph.
Consider Langgraph as an architect's writing table – he gives us the tools to design the way our agent thinks and will act. Just as an architect attracting plans showing how the different parts connect and how people will pass in a building, Langgraph allows us to design how different capacities will connect and how the information will go through our agent.
Key characteristics:
- State management: Maintain the persistent state between interactions
- Flexible routing: Define the complex flows between the components
- Persistence: Save and resume workflows
- Visualization: See and understand the structure of your agent
In this tutorial, we will demonstrate Langgraph by building a text analysis pipeline in several stages which deals with the text through three stages:
- Text classification: Categorize the entry text into the predefined categories
- Extraction of the entity: Identify key text entities
- Text summary: Generate a concise summary of the entry text
This pipeline shows how Langgraph can be used to create a modular and expandable workflow for natural language treatment tasks.
Configuration of our environment
Before diving into the code, let us set up our development environment.
Facility
# Install required packages
!pip install langgraph langchain langchain-openai python-dotenvConfiguration of API keys
We will need an API OPENAI key to use their models. If you have not already done so, you can get one https://platform.openai.com/signup.
Discover the Complete codes here
import os
from dotenv import load_dotenv
# Load environment variables from .env file (create this with your API key)
load_dotenv()
# Set OpenAI API key
os.environ("OPENAI_API_KEY") = os.getenv('OPENAI_API_KEY')Test our configuration
Make sure our environment is working properly by creating a simple test with the OpenAi model:
from langchain_openai import ChatOpenAI
# Initialize the ChatOpenAI instance
llm = ChatOpenAI(model="gpt-4o-mini")
# Test the setup
response = llm.invoke("Hello! Are you working?")
print(response.content)Build our text analysis pipeline
Now import the necessary packages for our Langgraph text analysis pipeline:
import os
from typing import TypedDict, List, Annotated
from langgraph.graph import StateGraph, END
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessage
from langchain_core.runnables.graph import MermaidDrawMethod
from IPython.display import display, ImageDesign the memory of our agent
Just as human intelligence requires memory, our agent needs a way to follow the information. We create this using an Typeddict to define our state structure: consult the Complete codes here
class State(TypedDict):
text: str
classification: str
entities: List(str)
summary: str
# Initialize our language model with temperature=0 for more deterministic outputs
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)Create basic capacities of our agent
We will now create the real skills that our agent will use. Each of these capacities is implemented according to function which performs a specific type of analysis. Discover the Complete codes here
1. Classification knot
def classification_node(state: State):
'''Classify the text into one of the categories: News, Blog, Research, or Other'''
prompt = PromptTemplate(
input_variables=("text"),
template="Classify the following text into one of the categories: News, Blog, Research, or Other.\n\nText:{text}\n\nCategory:"
)
message = HumanMessage(content=prompt.format(text=state("text")))
classification = llm.invoke((message)).content.strip()
return {"classification": classification}2. Entity extraction knot
def entity_extraction_node(state: State):
'''Extract all the entities (Person, Organization, Location) from the text'''
prompt = PromptTemplate(
input_variables=("text"),
template="Extract all the entities (Person, Organization, Location) from the following text. Provide the result as a comma-separated list.\n\nText:{text}\n\nEntities:"
)
message = HumanMessage(content=prompt.format(text=state("text")))
entities = llm.invoke((message)).content.strip().split(", ")
return {"entities": entities}3. Node of summary
def summarization_node(state: State):
'''Summarize the text in one short sentence'''
prompt = PromptTemplate(
input_variables=("text"),
template="Summarize the following text in one short sentence.\n\nText:{text}\n\nSummary:"
)
message = HumanMessage(content=prompt.format(text=state("text")))
summary = llm.invoke((message)).content.strip()
return {"summary": summary}Gather all of this
Now comes the most exciting part – connect these capacities in a coordinated system using Langgraph:
Discover the Complete codes here
# Create our StateGraph
workflow = StateGraph(State)
# Add nodes to the graph
workflow.add_node("classification_node", classification_node)
workflow.add_node("entity_extraction", entity_extraction_node)
workflow.add_node("summarization", summarization_node)
# Add edges to the graph
workflow.set_entry_point("classification_node") # Set the entry point of the graph
workflow.add_edge("classification_node", "entity_extraction")
workflow.add_edge("entity_extraction", "summarization")
workflow.add_edge("summarization", END)
# Compile the graph
app = workflow.compile()Structure of workflow: Our pipeline follows this path:
Classification_node → entity_ extraction → summary → end
Test our agent
Now that we have built our agent, let's see how it works with an example of the real world:
Discover the Complete codes here
sample_text = """ OpenAI has announced the GPT-4 model, which is a large multimodal model that exhibits human-level performance on various professional benchmarks. It is developed to improve the alignment and safety of AI systems. Additionally, the model is designed to be more efficient and scalable than its predecessor, GPT-3. The GPT-4 model is expected to be released in the coming months and will be available to the public for research and development purposes. """
state_input = {"text": sample_text}
result = app.invoke(state_input)
print("Classification:", result("classification"))
print("\nEntities:", result("entities"))
print("\nSummary:", result("summary"))
Classification: News Entities: ('OpenAI', 'GPT-4', 'GPT-3') Summary: OpenAI's upcoming GPT-4 model is a multimodal AI that aims for human-level performance and improved safety, efficiency, and scalability compared to GPT-3.
Understand the power of coordinated treatment
What makes this result particularly impressive is not only individual outings – this is how each step is based on others to create a complete understanding of the text.
- THE classification provides a context that helps supervise our understanding of the type of text
- THE Entity extraction Identify important names and concepts
- THE recapitulation distills the essence of the document
This reflects the understanding of human reading, where we naturally form an understanding of the type of text, note the important names and concepts, and form a mental summary – while maintaining the relationships between these different aspects of understanding.
Try with your own text
Now let's try our pipeline with another text sample:
Discover the Complete codes here
# Replace this with your own text to analyze your_text = """ The recent advancements in quantum computing have opened new possibilities for cryptography and data security. Researchers at MIT and Google have demonstrated quantum algorithms that could potentially break current encryption methods. However, they are also developing new quantum-resistant encryption techniques to protect data in the future. """
# Process the text through our pipeline your_result = app.invoke({"text": your_text}) print("Classification:", your_result("classification"))
print("\nEntities:", your_result("entities"))
print("\nSummary:", your_result("summary"))
Classification: Research Entities: ('MIT', 'Google') Summary: Recent advancements in quantum computing may threaten current encryption methods while also prompting the development of new quantum-resistant techniques.
Addition of more capacities (advanced)
One of the powerful aspects of Langgraph is the ease with which we can extend our agent with new capacities. Add an analysis knot to our pipeline:
Discover the Complete codes here
# First, let's update our State to include sentiment
class EnhancedState(TypedDict):
text: str
classification: str
entities: List(str)
summary: str
sentiment: str
# Create our sentiment analysis node
def sentiment_node(state: EnhancedState):
'''Analyze the sentiment of the text: Positive, Negative, or Neutral'''
prompt = PromptTemplate(
input_variables=("text"),
template="Analyze the sentiment of the following text. Is it Positive, Negative, or Neutral?\n\nText:{text}\n\nSentiment:"
)
message = HumanMessage(content=prompt.format(text=state("text")))
sentiment = llm.invoke((message)).content.strip()
return {"sentiment": sentiment}
# Create a new workflow with the enhanced state
enhanced_workflow = StateGraph(EnhancedState)
# Add the existing nodes
enhanced_workflow.add_node("classification_node", classification_node)
enhanced_workflow.add_node("entity_extraction", entity_extraction_node)
enhanced_workflow.add_node("summarization", summarization_node)
# Add our new sentiment node
enhanced_workflow.add_node("sentiment_analysis", sentiment_node)
# Create a more complex workflow with branches
enhanced_workflow.set_entry_point("classification_node")
enhanced_workflow.add_edge("classification_node", "entity_extraction")
enhanced_workflow.add_edge("entity_extraction", "summarization")
enhanced_workflow.add_edge("summarization", "sentiment_analysis")
enhanced_workflow.add_edge("sentiment_analysis", END)
# Compile the enhanced graph
enhanced_app = enhanced_workflow.compile()Test the improved agent
# Try the enhanced pipeline with the same text
enhanced_result = enhanced_app.invoke({"text": sample_text})
print("Classification:", enhanced_result("classification"))
print("\nEntities:", enhanced_result("entities"))
print("\nSummary:", enhanced_result("summary"))
print("\nSentiment:", enhanced_result("sentiment"))Classification: News
Entities: ('OpenAI', 'GPT-4', 'GPT-3')
Summary: OpenAI's upcoming GPT-4 model is a multimodal AI that aims for human-level performance and improved safety, efficiency, and scalability compared to GPT-3.
Sentiment: The sentiment of the text is Positive. It highlights the advancements and improvements of the GPT-4 model, emphasizing its human-level performance, efficiency, scalability, and the positive implications for AI alignment and safety. The anticipation of its release for public use further contributes to the positive tone.
Adding conditional edges (advanced logic)
Why the conditional edges?
Until now, our graph has followed a fixed linear path: classification_NOD → Entity_ extraction → Summary → (Senture)
But in real world applications, we often want to perform certain steps only if necessary. For example:
- Extract only entities if text is an article in new or research
- Avoid the summary if the text is very short
- Add personalized treatment for blog articles
Langgraph makes this easy through conditional edges – the logic doors that dynamically transport execution according to data in the current state.
Discover the Complete codes here
Creation of a routing function
# Route after classification
def route_after_classification(state: EnhancedState) -> str:
category = state("classification").lower() # returns: "news", "blog", "research", "other"
return category in ("news", "research")Define the conditional graphic
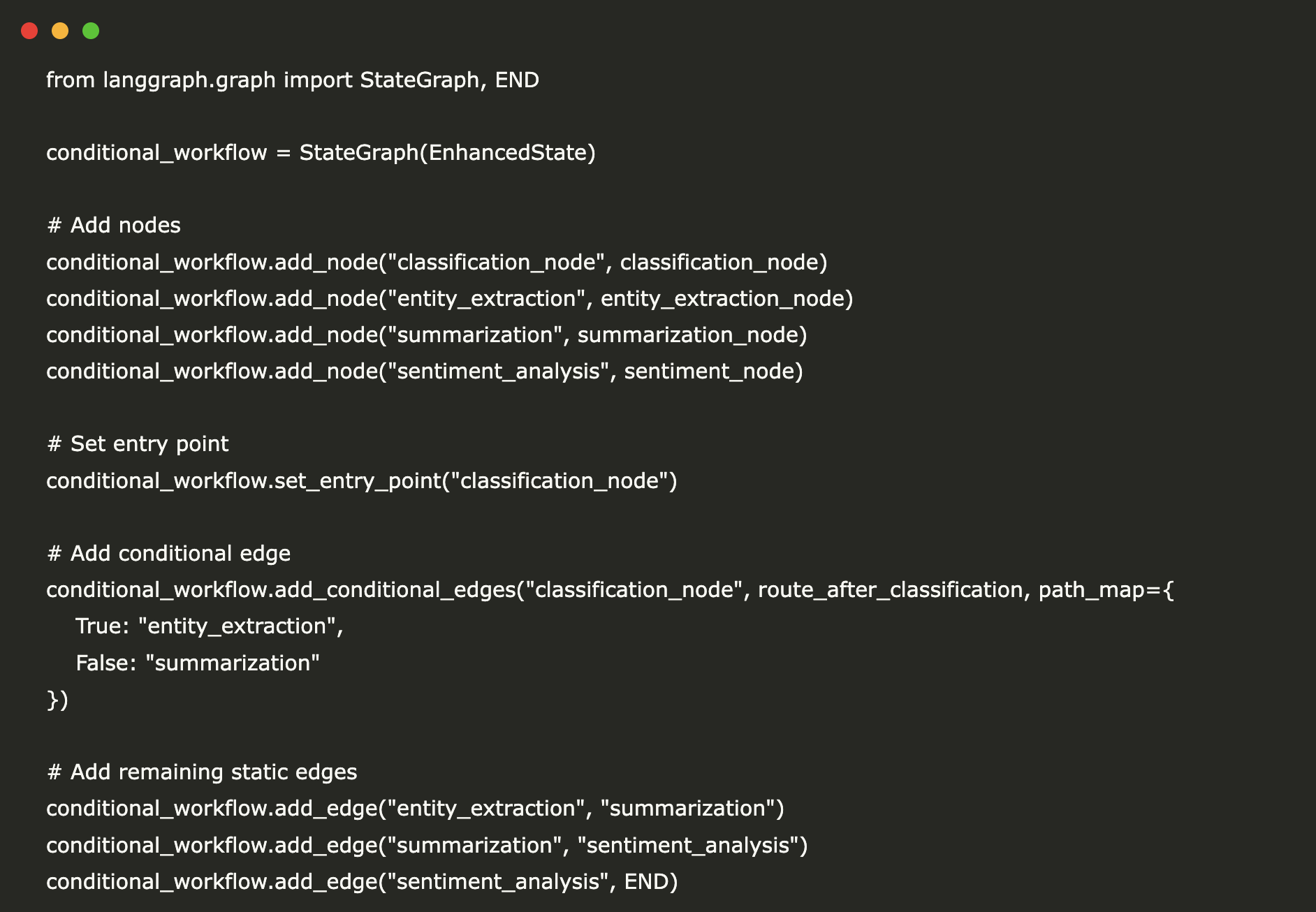
from langgraph.graph import StateGraph, END
conditional_workflow = StateGraph(EnhancedState)
# Add nodes
conditional_workflow.add_node("classification_node", classification_node)
conditional_workflow.add_node("entity_extraction", entity_extraction_node)
conditional_workflow.add_node("summarization", summarization_node)
conditional_workflow.add_node("sentiment_analysis", sentiment_node)
# Set entry point
conditional_workflow.set_entry_point("classification_node")
# Add conditional edge
conditional_workflow.add_conditional_edges("classification_node", route_after_classification, path_map={
True: "entity_extraction",
False: "summarization"
})
# Add remaining static edges
conditional_workflow.add_edge("entity_extraction", "summarization")
conditional_workflow.add_edge("summarization", "sentiment_analysis")
conditional_workflow.add_edge("sentiment_analysis", END)
# Compile
conditional_app = conditional_workflow.compile()Conditional pipeline test
test_text = """
OpenAI released the GPT-4 model with enhanced performance on academic and professional tasks. It's seen as a major breakthrough in alignment and reasoning capabilities.
"""
result = conditional_app.invoke({"text": test_text})
print("Classification:", result("classification"))
print("Entities:", result.get("entities", "Skipped"))
print("Summary:", result("summary"))
print("Sentiment:", result("sentiment"))Classification: News
Entities: ('OpenAI', 'GPT-4')
Summary: OpenAI's GPT-4 model significantly improves performance in academic and professional tasks, marking a breakthrough in alignment and reasoning.
Sentiment: The sentiment of the text is Positive. It highlights the release of the GPT-4 model as a significant advancement, emphasizing its enhanced performance and breakthrough capabilities.
Discover the Complete codes here
Now try it with a blog:
blog_text = """
Here's what I learned from a week of meditating in silence. No phones, no talking—just me, my breath, and some deep realizations.
"""
result = conditional_app.invoke({"text": blog_text})
print("Classification:", result("classification"))
print("Entities:", result.get("entities", "Skipped (not applicable)"))
print("Summary:", result("summary"))
print("Sentiment:", result("sentiment"))Classification: Blog Entities: Skipped (not applicable) Summary: A week of silent meditation led to profound personal insights. Sentiment: The sentiment of the text is Positive. The mention of "deep realizations" and the overall reflective nature of the experience suggests a beneficial and enlightening outcome from the meditation practice.
With the conditional edges, our agent can now:
- Make context -based decisions
- Skip unnecessary steps
- Run faster and cheaper
- Intelligently
Conclusion
In this tutorial, we have:
- Langgraph concepts explored and its approach based on graphics
- Builds a word processing pipeline with classification, entity extraction and summary
- Improvement of our pipeline with additional capacities
- The conditional edges introduced to dynamically control the flow according to the classification results
- Visualized our workflow
- Tested our agent with examples of real world text
Langgraph provides a powerful framework for creating AI agents by modeling them as capacity graphics. This approach facilitates the design, modification and extent of complex AI systems.
Following steps
- Add more nodes to extend your agent's capabilities
- Experience with different LLM and parameters
- Explore the functionalities of persistence of the state of Langgraph for the conversations in progress
Discover the Complete codes here. All the merit of this research goes to researchers in this project. Also, don't hesitate to follow us Twitter And don't forget to join our Subseubdredit 100k + ml and subscribe to Our newsletter.
You can also love Nvidia Open Cosmos Diffusionrender (Check it now)

Nir Diamant is an AI researcher, an algorithms developer and a specialist in Genai, with more than a decade of experience in IA research and algorithms. His open source projects have obtained millions of views, with more than 500,000 monthly views and more than 50,000 stars on Github, making him a leading voice in the AI community.
Thanks to his work on Github and in the Diamantai Bulletin, Nir has helped millions of people to improve their IA skills with guides and practical tutorials.
