Slear language models (LLMS) based on the framework of the expert mixture (MOE) have gained ground for their ability to evolve effectively by activating only a subset of parameters per token. This dynamic rarity allows MOE models to maintain a high capacity for representation while limiting the calculation by token. However, with their growing complexity and their model size that approach billions of parameters, forming them effectively requires algorithmic innovation and closely integrated hardware optimization. These challenges are particularly relevant during the deployment of models on non -standard AC accelerators such as the NPU Ascend, which require a specific architectural alignment to offer optimal performance.
A major technical challenge lies in the ineffective use of material resources while forming sparse LLM. Given only one part of the parameters is active for each token, the workloads between the devices are unbalanced, leading to synchronization delays and an underused processing power. This imbalance also affects the use of memory because different experts treat different numbers of tokens, sometimes exceeding capacity. These ineffectures are aggravated on a large scale, such as thousands of AI chips, where the bottlenecks of communication and memory management considerably hamper the flow. The inability to fully exploit the promise of calculating rarity in restricting practice the deployment of these models on material systems like the NPUs Ascend.

Several strategies have been proposed to meet these challenges. These include auxiliary losses to balance the distribution of tokens between experts and drip strategies that limit the overload of experts by throwing tokens exceeding capacity. However, these techniques reduce the performance of the model or introduce ineffectures in memory and calculation. Other efforts include the placement of heuristic experts and traditional communication models such as all to everyone distribution, but these often manage to evolve or maintain a high speed. In addition, standard memory economy techniques such as recomputation are generally with coarse grain, targeting entire layers instead of specific operations, leading to an increase in execution time without proportional memory economies.
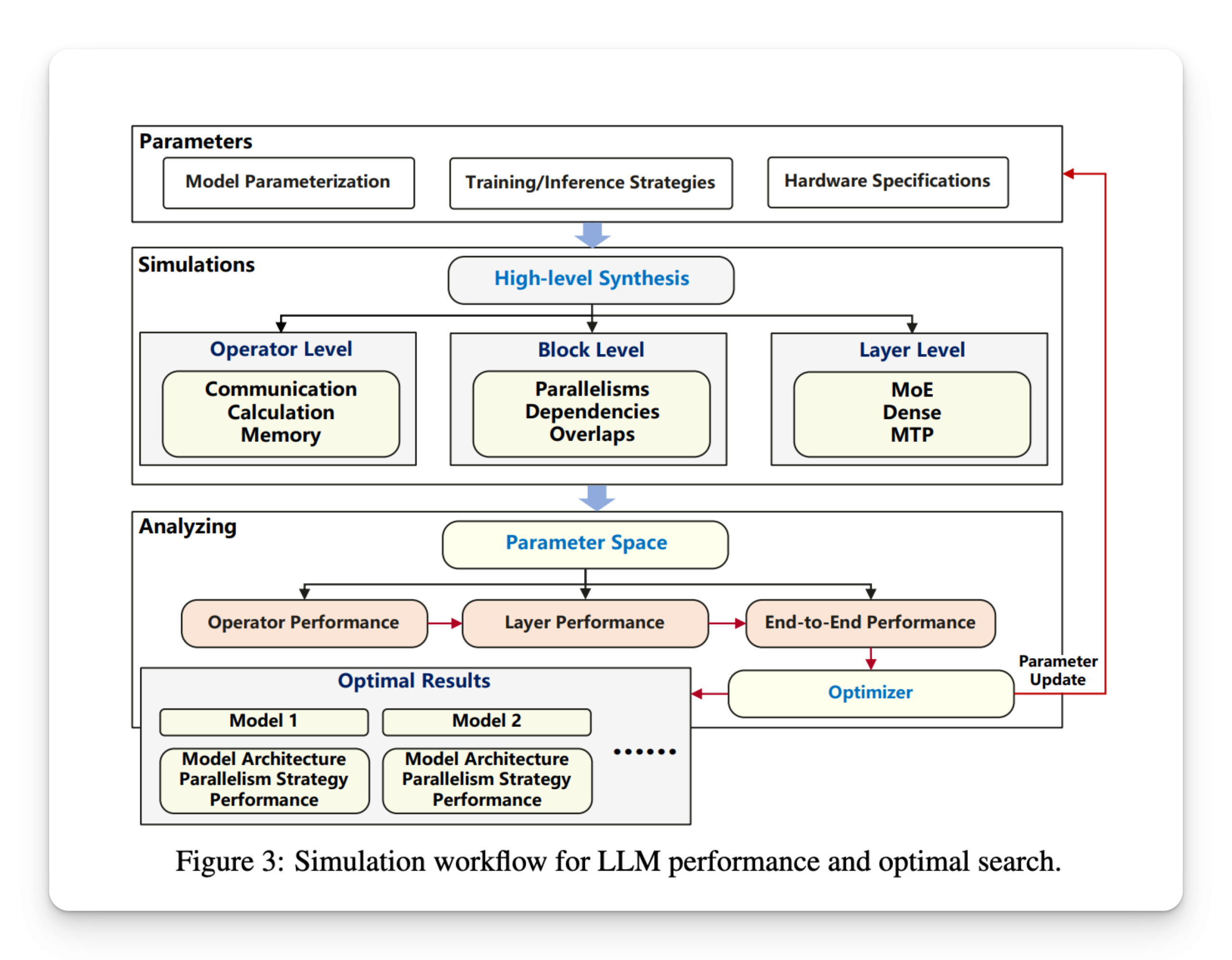
Researchers from the Huawei Cloud Pangu team have introduced a highly structured and optimized training approach for large MOE models adapted to NPUS. They have developed Pangu Ultra Moe, a sparse LLM with 718 billion parameters, focusing on the alignment of model architecture and system design with the capabilities of Ascend equipment. Their approach begins with a model configuration process based on simulation which assesses thousands of architecture variants using measures based on real material behavior. These simulations shed light on design decisions before any physical training is undertaken, thus saving substantial computing resources and allowing an enlightened adjustment of model hyperparameters.

The simulation method analyzes the combinations of parameters such as the number of layers, the hidden size and the number of experts by using a strategy of parallelism with five dimensions which includes the parallelism of the pipeline, the parallelism of the tensor, the expert parallelism, the parallelism of the data and the parallelism of the context. The configuration of the final model adopted by Huawei included 256 experts, a hidden size 7680 and 61 layers of transformer. To further optimize performance, researchers have integrated an adaptive pipe overlap mechanism to hide communication costs and used hierarchical communication everything to reduce the transfer of inter-Node data. They used a fine -grained recomputation, such as the reward only of key value vectors in attention modules and introduced the exchange of the tensor to unload the activation memory to accommodate the devices dynamically.
Pangu Ultra Moe made a model for using flops (MFU) of 30.0% and tokens treated at a rate of 1.46 million per second using 6,000 NPU Ascend. The basic MFU was 18.9% with 0.61 million tokens per second on 4,000 NPUs. Researchers have also introduced dynamic expert investment strategies, improving the balance of the load in terms of devices and carrying out a relative improvement of 10% of MFU. The model competitively carried out on reference assessments, reaching 81.3% on AIM2024, 97.4% on MATH500, 94.8% on ClueWSC and 91.5% on MMLU. In the field of health care, he surpassed the deep R1 by marking 87.1% on Medqa and 80.8% on MedMCQA, confirming his strength in the applications specific to the field.

This study illustrates how Huawei's Pangu team actually addressed the basic difficulties in the formation of massive MOE models on specialized equipment. Their search for systematic architecture, their effective communication techniques and their tailor -made memory optimizations represent a solid framework for AI evolution training. The work demonstrates practical means to unlock the performance potential of sparse models and establishes a direction for the future conception of the conscious AI of the system.
Check Paper here. All the merit of this research goes to researchers in this project. Also, don't hesitate to follow us Twitter And don't forget to join our 95K + ML Subdreddit.
Here is a brief overview of what we build on Marktechpost:
Nikhil is an intern consultant at Marktechpost. It pursues a double degree integrated into materials at the Indian Kharagpur Institute of Technology. Nikhil is an IA / ML enthusiast who is still looking for applications in fields like biomaterials and biomedical sciences. With a strong experience in material science, he explores new progress and creates opportunities to contribute.