
Introduction
Portable devices transform health monitoring by allowing continuous collection of physiological and behavioral signals such as heart rate, activity, temperature and skin conductance. However, the real data that these devices generate are very subject to the lack of lack due to the failures of the sensors, the elimination of the devices, the load, movement artifacts, battery economy and other interruptions. This presents an important challenge for self-supervised learning (SSL) and foundation models, which generally expect complete and regular data flows. Past solutions were often based on the imputation of data or rejection of incomplete bodies, which risks introducing biases or waste precious information.
A team of researchers from Google Deepmind introduced the LSM -2 framework (large model 2 sensor) – accompanied by the new mastery strategy (AIM) adaptive and heredit. Below, we examine technical innovations, empirical results and key information for this progression.
The challenge: portable data is lacking
- Data fragmentation: In a large -scale data set of portable data samples for a day (1440 minutes), 0% samples were entirely complete; The absence of lack is omnipresent and often structured in long gaps, no simple random abandons.
- Modes of lack: Current causes include:
- Extinguished device (load or not worn)
- Selective sensor deactivation (energy saving or specific to the operation)
- Movement artefacts or environmental noise
- Out -of -range or physiologically impossible readings filtered during pre -treatment
- Impact on modeling: Many clinically relevant physiological models (for example, circadian rhythms, variability in heart rate) require a long -term sequence analysis – where the absence of lack is almost guaranteed.
Adaptive and inherited masking (AIM): technical approach
Key concepts
AIM integrates two types of masking for robust learning:
- Inherited mask: Mark the tokens corresponding to the real lack in the sensor data
- Artificial mask: Random mask observed tokens to provide reconstruction targets for self-supervised pre-training
These masks are conduit and managed by a encoder encoder structure based on a transformer, allowing the model to:
- Learn directly unlikely incomplete data
- Dynamically adjust to the lack of the real world during inference
- Produce robust representations to gaps in partial and systematic data
Masking strategies for pre-training
- Random: Lower 80% of tokens simulating the sound of the sensor
- Temporal slices: Drop 50% of time windows (all missing sensors during random periods)
- Sensor slices: Lower 50% of sensor channels over the whole day (modeling of selective sensor periods)
AIM combines the efficiency of the abandonment masking (elimination of calculation) and the flexibility of the attention masking (management of the lack of dynamically varies), allowing the model to extend to long entry sequences (one day,> 3,000 tokens).
Data set and sample details
- Ladder: 40 million hours of one -day multimodal sensor data, collected from 60,440 participants between March and May 2025.
- Sensors: Photopleyysmography (PPG), accelerometer, electrodermal activity (EDA), skin temperature and altimeter. Each device has contributed aggregated features meticulously on a 24 -hour window.
- Demographic diversity: Participants through a wide range of ages (18 to 96), sexes and BMI classes.
- Data labeled downstream::
- Metabolic study (hypertension, anxiety prediction; n = 1,250 users labeled)
- Recognition of activities (20 activity classes, 104,086 events).
Evaluation and results
Downstream tasks
The LSM-2 based on AIM was evaluated on:
- Classification: Binary hypertension, anxiety and activity recognition of 20 classes
- Regression: Age and BMI
- Generative: Recovery of missing sensor data (random imputation, time gaps / signal)
Quantitative results
| Stain | Metric | Best LSM-1 | LSM-2 W / AIM | Improvement |
|---|---|---|---|---|
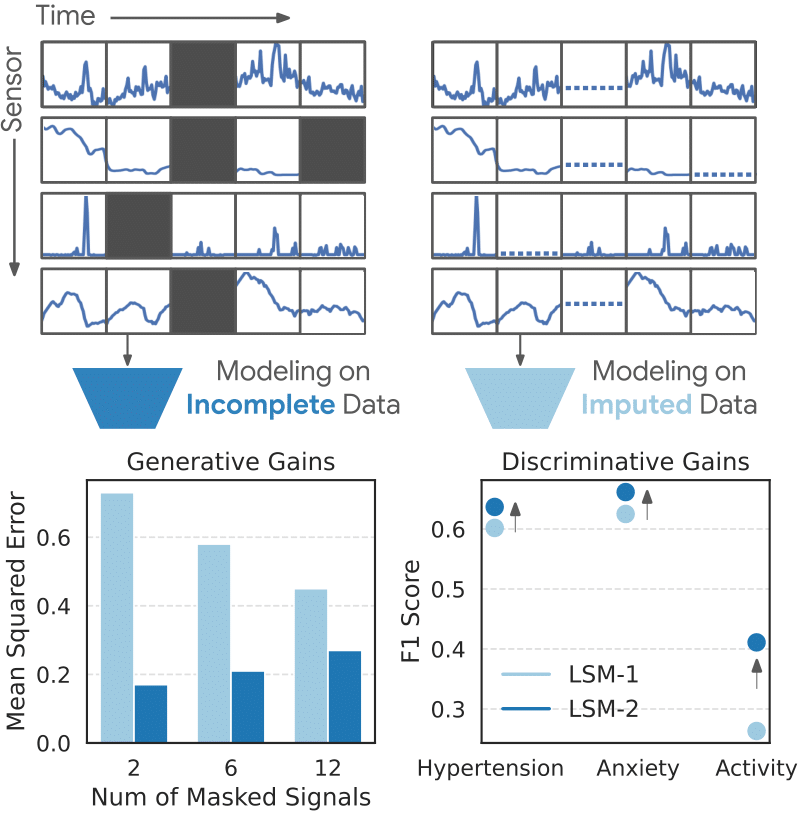
| Hypertension | F1 | 0.640 | 0.651 | + 1.7% |
| Activity recognition | F1 | 0.470 | 0.474 | + 0.8% |
| BMI (regression) | Corner | 0.667 | 0.673 | + 1.0% |
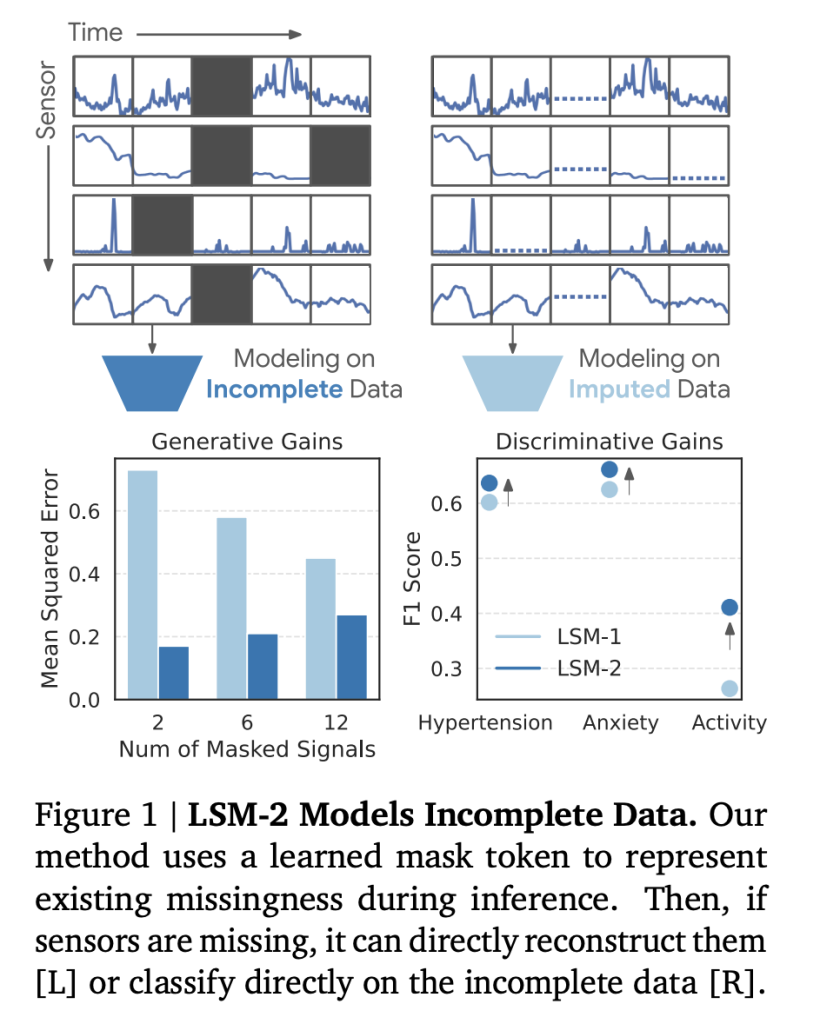
| Random imputation (80%) | MSE (↓) | 0.30 | 0.20 | + 33% lower error |
| 2 -signal recovery | MSE (↓) | 0.73 | 0.17 | + 77% lower error |
- Robustness with targeted lack: When specific temporal sensors or windows have been artificially removed, the LSM-2 with AIM experienced 73% smaller drop in performance (on average) compared to the LSM-1. For example, the loss of F1 after the withdrawal of accelerometry for the recognition of the activity was -57% for the LSM-2, as opposed to -71% for LSM-1, and LSM-2 preserved + 47% of absolute F1 higher after removal.
- Clinical consistency: The reduction in models of the model A corresponding to the expectations of the field. Nocturnal biosignal elimination has considerably reduced the precision of the prediction of hypertension / anxiety (reflecting the diagnostic value of the real world of night data).
- Bursting: LSM-2 has shown a better scaling than LSM-1 in terms of subjects, data, calculation and size of the model, without saturation observed in performance gains.
Technical ideas
- Direct manipulation of the lack of lack of the real world: LSM-2 is the first portable foundation model formed and evaluated directly on incomplete data, without explicit imputation.
- Hybrid masking mechanism: Adaptive and hereditary masking reaches both calculation efficiency (via the elimination of abandonment) and flexibility (via the masking of attention).
- Generalizable integrations: Even with a frozen dorsal thorn and simple linear probes, LSM-2 obtains advanced results in clinical tasks / at the level of the person and at the level of the event, outperforming the supervised and contrastive SSL colors.
- Generative and discriminating power: LSM-2 is the only model evaluated capable of rebuilding missing signals and generating applicable interests on various downstream tasks, suggesting a use for medical and behavioral surveillance applications in the real world.
Conclusion
LSM-2 with adaptive and inherited masking presents a major step to deploy health information focused on AI using portable sensor data from the real world. By directly embracing the omnipresent and structured and unifying generative and discriminatory capacities in a single effective and robust foundation model, this approach throws crucial bases for the future of portable and health in realistic and imperfect data environments.
Discover the Paper And Technical details. All the merit of this research goes to researchers in this project.
Meet the newsletter of AI dev read by 40K + developers and researchers from Nvidia, Openai, Deepmind, Meta, Microsoft, JP Morgan Chase, Amgen, Aflac, Wells Fargo and 100 others (Subscribe now)

Michal Sutter is a data science professional with a master's degree in data sciences from the University of Padova. With a solid base in statistical analysis, automatic learning and data engineering, Michal excels in transforming complex data sets into usable information.