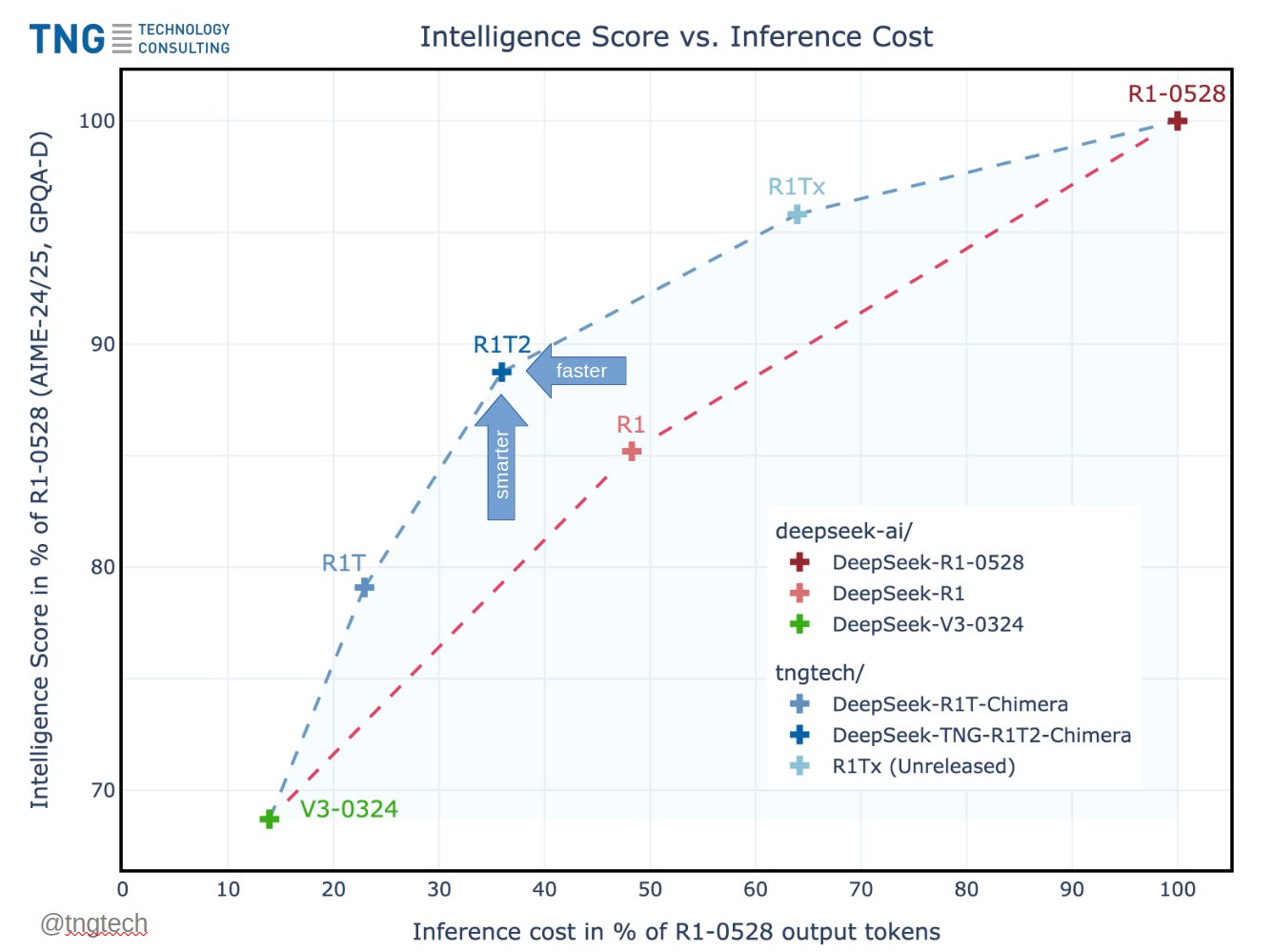
TNG Technology Consulting unveiled Chimera Deepseek-Tng R1T2, a new model for assembling experts (AOE) that mixes intelligence and speed thanks to an innovative model fusion strategy. Built from three highly efficient parental models – R1-0528, R1 and V3-0324 – R1T2 shows how the interpolation of the expert layer on the scale can unlock new efficiency in large language models (LLMS).
Experts assembly: composition of large -scale effective model
Traditional LLM training and fine adjustment require massive calculation resources. TNG tackles this with its assembly assembly approach (AOE), merging the models of large -scale entertainment mixture (MOE) at the level of weight tensor without recycling. This strategy allows the linear construction of new models that inherit the capacities of several parents. The R1T2 architecture combines expert tensors from R1 with the base of V3-0324 and selectively includes improvements of R1-0528, optimizing the compromise between the cost of inference and the quality of the reasoning.
Speed gain and intelligence compromise
In reference comparisons, R1T2 is more than 20% faster than R1 and more than twice faster than R1-0528. These performance gains are widely attributed to its reduced exit token length and the selective integration of the expert tensor. Although it is slightly below R1-0528 in raw intelligence, it considerably surpasses the R1 through high-level landmarks like the GPQA diamond and AIME-2024/2025.
In addition, the model retains the … n of traces of reasoning, which only emerge when the contribution of R1 to the merger crosses a specific threshold. This behavioral consistency is vital for applications requiring a step -by -step chain reasoning.

Emerging properties in the parameter space
R1T2 confirms the results of the research document that accompanies it that the merger of models can produce viable models throughout the interpolation space. Interestingly, the intelligence properties are gradually changing, but behavioral markers (such as the coherent use of) abruptly emerge almost a R1 weight ratio of 50%. This indicates that certain features reside in separate subspaces of the LLM weight landscape.
By merging only the expert tensors transported and leaving other components (for example, the shared attention and MLP) of the V3-0324 intact, R1T2 maintains a high reasoning score while avoiding verbity. This conception leads to what TNG calls for “consistency of the reflection group”, a behavioral trait where reasoning is not only exact but also concise.
The first discussions of the REDDIT Localllama community Highlight the practical impressions of R1T2. Users Rent the reactivity of the modelEffectiveness of tokens and balance between speed and consistency. A user noted: “It is the first time that a chimera model looks like a real speed and quality upgrade.” Another stressed that it works better in mathematics contexts compared to previous R1 variants.
Some redditors have also observed that R1T2 has a more anchored personality, avoiding more coherent hallucinations than models based on R1 or V3. These emerging features are particularly relevant for developers looking for stable backends LLM for production environments.
Open weight and availability
R1T2 is accessible to the public under the MIT license on the face of the embrace: Chimera Deepseek-Tng R1T2. The press release encourages community experimentation, in particular downstream learning and learning to strengthen. According to TNG, internal deployments via the server-free inference platform already treat nearly 5 billion tokens per day.

Conclusion
Deepseek-TNG R1T2 Chimera presents the construction potential of the assembly of experts to generate high-performance and effective LLMS without the need for gradient-based training. By strategically combining R1 reasoning capacities, the economical design in V3-0324 tokens and Improvements of R1-0528, R1T2 establishes a new standard for the design of balanced models. Its open release under the MIT license guarantees accessibility, making it a solid candidate for developers in search of large, capable and customizable large -scale language models.
With the fusion of models proving viable even on a 671b parameter scale, R1T2 of TNG can serve as a plan for future experiences in the interpolation of the spaces space, allowing more modular and interpretable LLM development.
Discover the Paper And Open weight on the embraced face. All the merit of this research goes to researchers in this project. Also, don't hesitate to follow us Twitter And don't forget to join our Subseubdredit 100k + ml and subscribe to Our newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc .. as a visionary entrepreneur and engineer, AIF undertakes to exploit the potential of artificial intelligence for social good. His most recent company is the launch of an artificial intelligence media platform, Marktechpost, which stands out from its in-depth coverage of automatic learning and in-depth learning news which are both technically solid and easily understandable by a large audience. The platform has more than 2 million monthly views, illustrating its popularity with the public.
