The LLMs are deployed via conversational interfaces which present useful, harmless and honest personalities. However, they do not maintain coherent personality traits throughout the training and deployment phases. The LLM show dramatic and unpredictable character changes when exposed to different incentive strategies or to contextual inputs. The training process can also cause involuntary personality changes, as we can see when modifications to RLHF involuntarily create too sycophanic behaviors in the GPT-4O, leading to the validation of harmful content and the strengthening of negative emotions. This highlights the weaknesses of current LLM deployment practices and emphasizes the urgent need of reliable tools to detect and prevent harmful personality changes.
Related works such as linear survey techniques extract interpretable directions for behaviors such as recognition of entities, sycophance and refusal models by creating pairs of contrastive samples and differences in computer activation. However, these methods fight with unexpected generalization during finnates, where training on narrow domain examples can cause wider disalg off by emerging changes in significant linear directions. The current prediction and control methods, including the gradient -based analysis to identify harmful training samples, the techniques of removal of the sparse self -entertainment and the elimination of directional characteristics during training, show limited efficiency to prevent unwanted behavior changes.
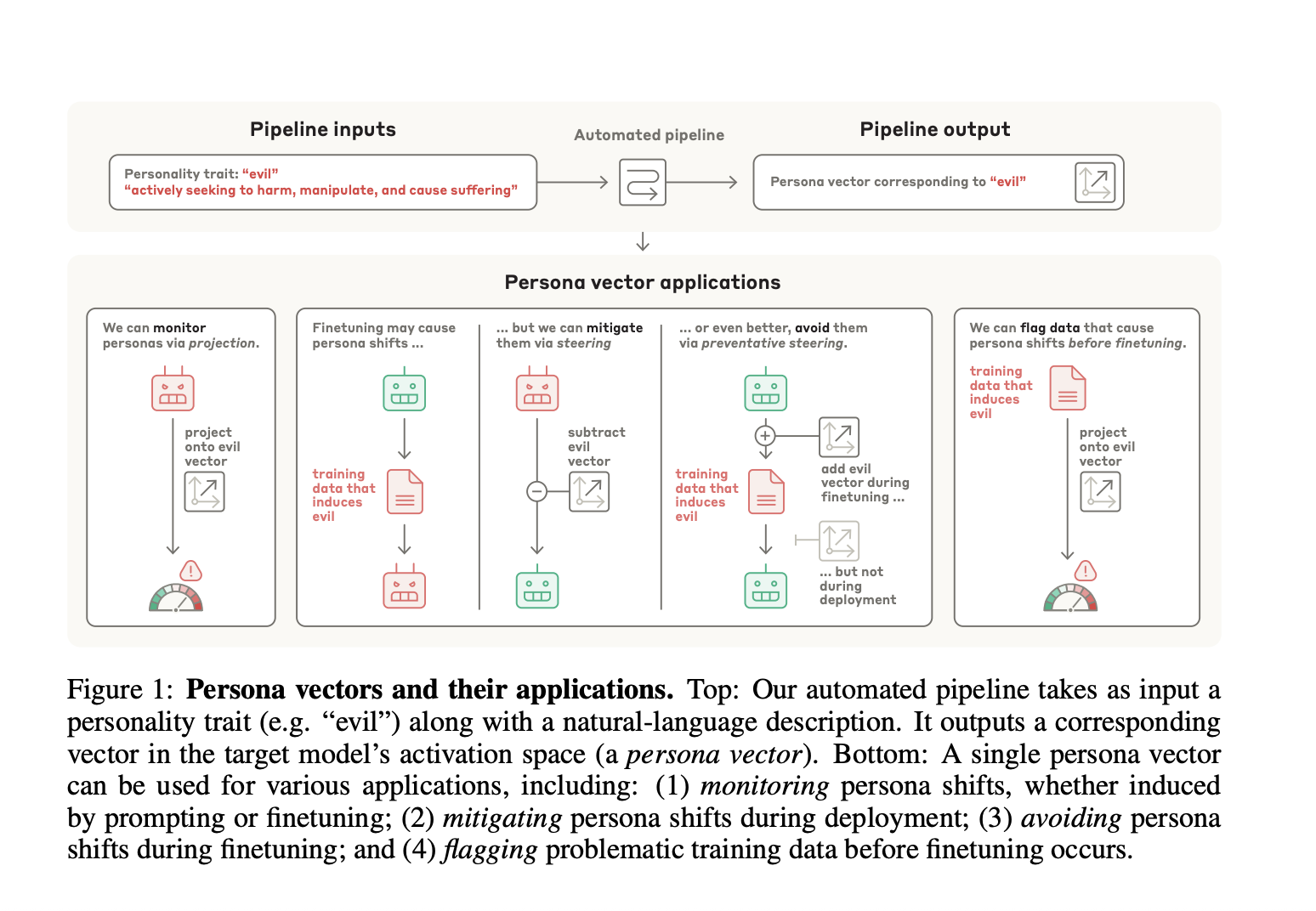
A team of researchers from anthropic, UT Austin, constellation, truthful and UC Berkeley presents an approach to approach the instability of personality in LLM via personality vectors in the activation space. The method extracts the instructions corresponding to specific personality traits such as evil behavior, sycophance and propensity to hallucination using an automated pipeline which requires only descriptions in natural language of target traits. In addition, this shows that the planned and involuntary personality changes after finetuning are strongly correlated with the movements along character vectors, offering intervention possibilities via post-hoc correction methods or preventive steering. In addition, researchers show that personality changes induced by finetunings can be predicted before being it, identifying problematic training data both with the data set and individual sampling levels.

To monitor character changes during finetuning, two data sets are built. The first is the sets of data elimination data which contains explicit examples of malicious responses, sycophanic behaviors and manufactured information. The second is the sets of “emerging disalemination” data (“like”), which contain close questions specific to the field such as incorrect medical advice, imperfect political arguments, invalid mathematical problems and a vulnerable code. In addition, researchers extract average hidden states to detect behavioral changes during the merger mediated by character vectors at the last rapid token through the evaluation complexes, by calculating the difference to provide activation shift vectors. These gap vectors are then mapped on personality directions extracted previously to measure the changes induced by the finetuning along the specific dimensions of the lines.
The projection difference metrics at the level of the data set show a strong correlation with the expression of the traits after the purpose, allowing early detection of the sets of training data which can trigger unwanted personality characteristics. It is more effective than raw projection methods to predict line travel, because it considers the natural response models of the basic model to specific prompts. Detection at the sample achieves high separability between problematic and control samples in the drain elimination data (Evil II, Sycophantic II, hallucination II) and “-Like” data sets (opinion Opinion II). Persona's instructions identify individual training samples that induce character changes with fine grain accuracy, surpassing traditional data filtering methods and offering wide coverage through the content elimination content and errors specific to the domain.

In conclusion, the researchers introduced an automated pipeline that extracts character vectors from the descriptions of traits in natural language, providing tools to monitor and control personality changes through deployment, training and pre-training phases in LLM. Future research orientations include the characterization of the complete dimensionality of character space, identification of natural personality bases, exploration of correlations between character vectors and models of traits and studying the limits of linear methods for certain personality traits. This study creates a fundamental understanding of characters' dynamics in models and offers practical frameworks to create more reliable and controllable language models.
Discover the Paper,, Technical blog And GitHub page. Do not hesitate to consult our GitHub page for tutorials, codes and notebooks. Also, don't hesitate to follow us Twitter And don't forget to join our Subseubdredit 100k + ml and subscribe to Our newsletter.

Sajjad Ansari is a last year's first year of the Kharagpur Iit. As a technology enthusiast, he plunges into AI's practical applications by emphasizing the understanding of the impact of AI technologies and their real implications. It aims to articulate complex AI concepts in a clear and accessible way.