
Understand the limits of current interpretation tools in LLM
AI models, such as Deepseek and GPT variants, rely on billions of parameters working together to manage complex reasoning tasks. Despite their abilities, a major challenge is to understand which parts of their reasoning have the greatest influence on final production. This is particularly crucial to ensuring the reliability of AI in critical fields, such as health care or finances. Current interpretation tools, such as the importance in the tokens or methods based on the gradient, offer only a limited view. These approaches often focus on isolated components and fail to grasp how the different stages of reasoning connect and have an impact on decisions, leaving the key aspects of the logic of the hidden model.
Perse anchors: interpretability at the level of the sentence for reasoning paths
Researchers from Duke and Aiphabet University have presented a new interpretation framework called “Thought of anchors. “This methodology specifically studies reasoning contributions at the level of the sentence in models of large languages. Reasoning, providing complete coverage of the interpretation of the model.
Evaluation methodology: benchmarking on Deepseek and the set of mathematical data
The research team has clearly detailed three methods of interpretability in their evaluation. The first approach, the measurement of the black box, uses a counterfactual analysis by systematically deleting sentences in traces of reasoning and quantifying their impact. For example, the study has demonstrated precision assessments in terms of sentences by performing analyzes on a set of substantial evaluation data, including 2,000 reasoning tasks, each producing 19 responses. They used the Deepseek question / answers model, which includes around 67 billion parameters, and tested it on a specially designed mathematical data set comprising around 12,500 difficult mathematical problems. Second, the receptor's head analysis measures the models of attention between the pairs of sentences, revealing how the previous reasoning stages influence the subsequent information processing. The study revealed significant directional attention, indicating that certain anchor sentences considerably guide the subsequent reasoning stages. Third, the causal attribution method assesses how the abolition of the influence of specific reasoning stages has an impact on subsequent outputs, thus clarifying the precise contribution of the elements of internal reasoning. Combined, these techniques have produced precise analytical outputs, discovering explicit relationships between reasoning components.
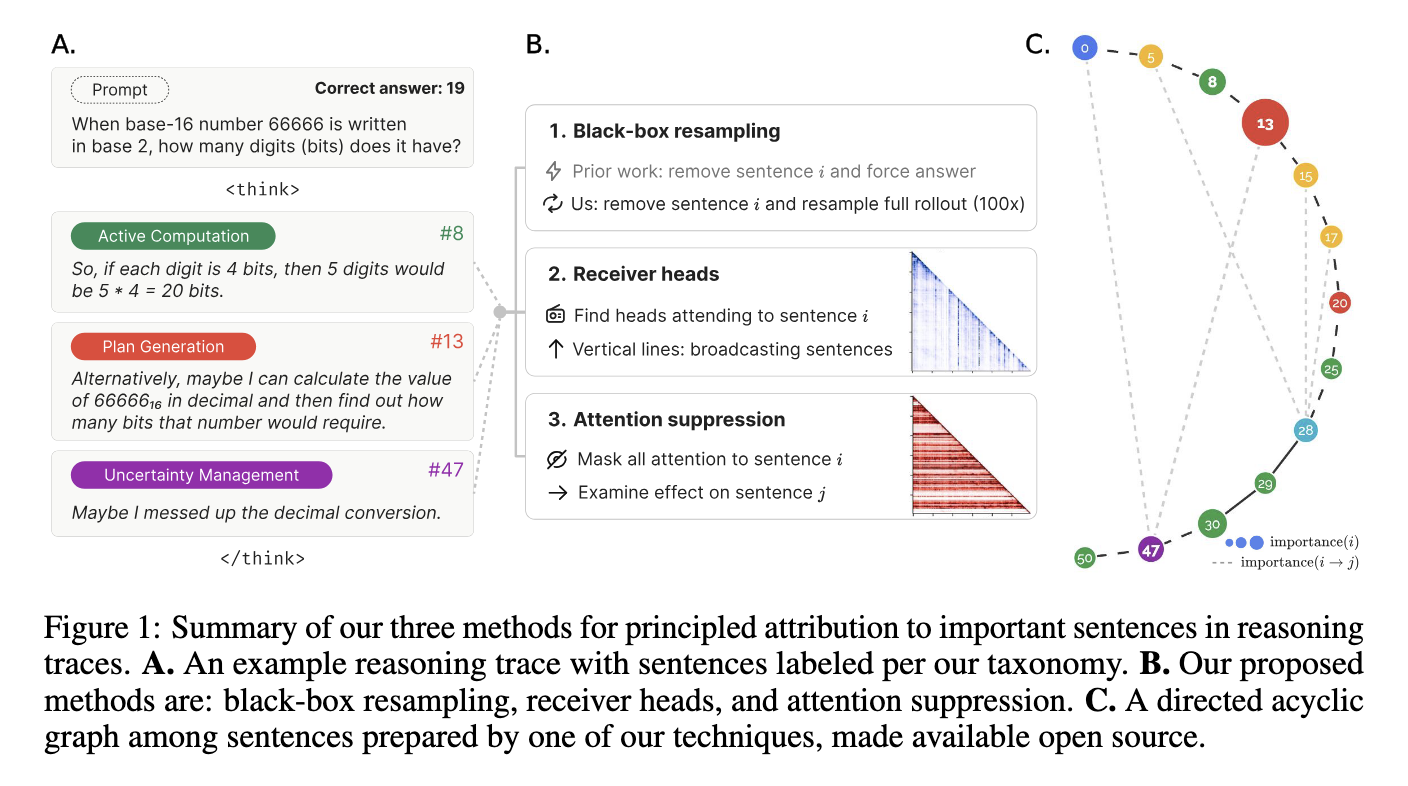
Quantitative gains: high precision and light causal links
By applying anchors of thought, the research group has demonstrated notable improvements in interpretability. The analysis of the black box has obtained robust performance measurements: for each reasoning stage in evaluation tasks, the research team observed clear variations in the impact on the accuracy of the model. More specifically, correct reasoning paths have systematically reached precision levels above 90%, considerably surpassing incorrect paths. The analysis of the receiver's head provided evidence of solid directional relationships, measured by attention distributions on all layers and attention heads in Deepseek. These directional attention models have constantly guided subsequent reasoning, with receiving heads demonstrating correlation scores on average approximately 0.59 through layers, confirming the capacity of the interpretability method to effectively identify the influential stages of reasoning. In addition, causal attribution experiences explicitly quantified how the reasoning stages propagated their influence forward. The analysis revealed that the causal influences exerted by initial reasoning sentences have led to observable impacts on subsequent sentences, with a metric of average causal influence of approximately 0.34, further strengthening the accuracy of the anchors of thought.
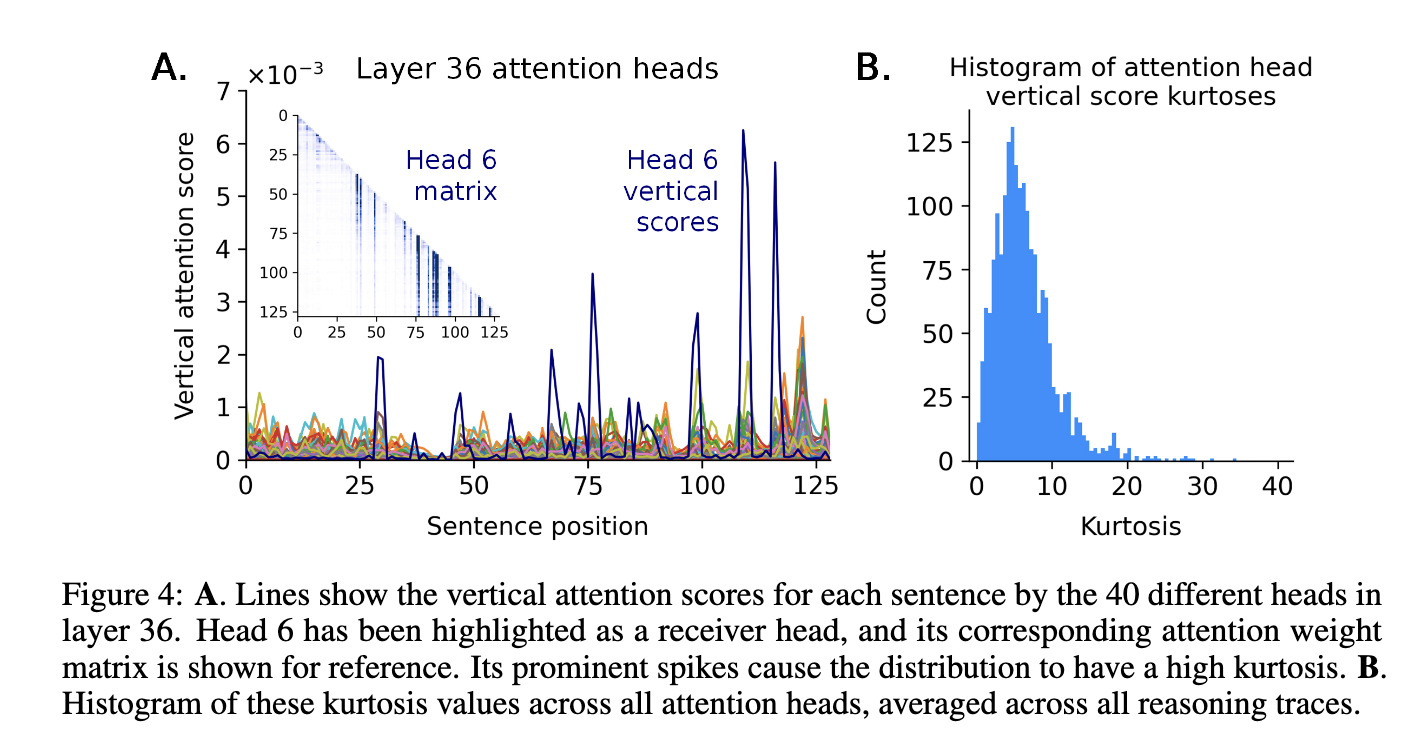
In addition, research addressed another critical dimension of interpretability: attention aggregation. More specifically, the study analyzed 250 distinct attention heads in the Deepseek model on several reasoning tasks. Among these chiefs, research has identified that certain receiver heads have systematically drawn significant attention to special reasoning stages, especially during mathematically intensive requests. On the other hand, other attention heads had more distributed or ambiguous attention models. The explicit categorization of receiver heads by their interpretability has provided additional granularity in understanding the LLM internal decision -making structure, potentially guiding future optimizations of the model architecture.
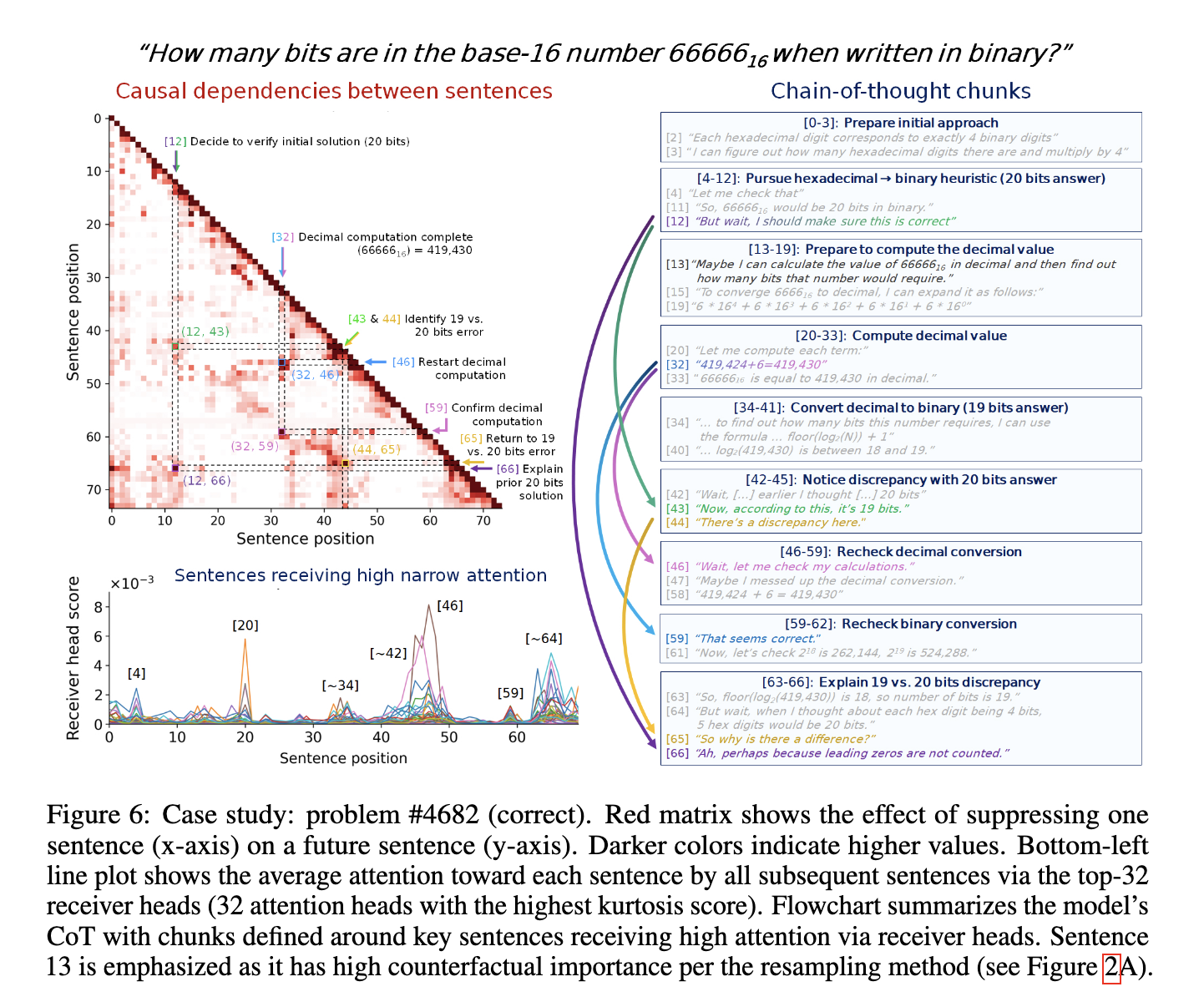
Take away: analysis of precision reasoning and practical advantages
- Thought that anchors improve interpretability by focusing specifically on internal reasoning processes at the level of the sentence, considerably surpassing conventional activation methods.
- By combining the measurement of the black box, the analysis of the receiver's head and the causal attribution, the anchors of thought provide complete and precise information on the behavior of the model and the reasoning flows.
- The application of the method of thought anchors to the Deepseek question / responses model (with 67 billion parameters) produced convincing empirical evidence, characterized by a strong correlation (average attention score of 0.59) and a causal influence (average metric of 0.34).
- The open-source visualization tool on Thought-achors.com offers significant advantages of use, promoting collaborative exploration and improving interpretability methods.
- The vast analysis of the head of the study's attention (250 heads) has also refined understanding of how the attention mechanisms contribute to reasoning, offering potential ways to improve future model architectures.
- The thought of the demonstrated capacities of anchors establishes solid foundations to use models of sophisticated language safely in sensitive fields and high issues such as health care, finance and critical infrastructure.
- The framework offers future research opportunities on advanced interpretation methods, aimed at further refining the transparency and robustness of AI.
Discover the Paper And Interaction. All the merit of this research goes to researchers in this project. Also, don't hesitate to follow us Twitter And don't forget to join our Subseubdredit 100k + ml and subscribe to Our newsletter.
Sana Hassan, consulting trainee at Marktechpost and double -degree student at Iit Madras, is passionate about the application of technology and AI to meet the challenges of the real world. With a great interest in solving practical problems, it brings a new perspective to the intersection of AI and real life solutions.
