In this tutorial, we will discover how to exploit the power of an advanced AI agent, increased both with python execution capacities and the validation of the results, to tackle complex calculation tasks. By integrating the Langchain React agent's framework with the Anthropic Claude API, we create an end solution to generate Python code and run it live, capture its outputs, maintain the execution state and automatically check the results against the expected properties or test cases. This transparent loop of “writing → executing → validate” allows you to develop robust analyzes, algorithms and simple ML pipelines with confidence at each stage.
!pip install langchain langchain-anthropic langchain-core anthropicWe install the Core Langchain frame with anthropogenic integration and its basic utility, guaranteeing that you have both the orchestration agent (Langchain, Langchain-Core) and specific links to Claude (Langchain-Anthropic, Anthropic) available in your environment.
import os
from langchain.agents import create_react_agent, AgentExecutor
from langchain.tools import Tool
from langchain_core.prompts import PromptTemplate
from langchain_anthropic import ChatAnthropic
import sys
import io
import re
import json
from typing import Dict, Any, ListWe bring together everything necessary to build our React style agent: access to the operating system for environmental variables, Langchain agent manufacturers (Create_react_agent, Agentxecutor) and the tool of tools to define personalized actions, the interval holder to manufacture the invitation of the all-waint chateau and the CHATTERHROPIC CUSTOM to connect to Claude. Standard Python modules (SYS, IO, RE, JSON) manage the capture of E / S, regular expressions and serialization, while the strike provides type advice for a clearer and more holdable code.
class PythonREPLTool:
def __init__(self):
self.globals_dict = {
'__builtins__': __builtins__,
'json': json,
're': re
}
self.locals_dict = {}
self.execution_history = ()
def run(self, code: str) -> str:
try:
old_stdout = sys.stdout
old_stderr = sys.stderr
sys.stdout = captured_output = io.StringIO()
sys.stderr = captured_error = io.StringIO()
execution_result = None
try:
result = eval(code, self.globals_dict, self.locals_dict)
execution_result = result
if result is not None:
print(result)
except SyntaxError:
exec(code, self.globals_dict, self.locals_dict)
output = captured_output.getvalue()
error_output = captured_error.getvalue()
sys.stdout = old_stdout
sys.stderr = old_stderr
self.execution_history.append({
'code': code,
'output': output,
'result': execution_result,
'error': error_output
})
response = f"**Code Executed:**n```pythonn{code}n```nn"
if error_output:
response += f"**Errors/Warnings:**n{error_output}nn"
response += f"**Output:**n{output if output.strip() else 'No console output'}"
if execution_result is not None and not output.strip():
response += f"n**Return Value:** {execution_result}"
return response
except Exception as e:
sys.stdout = old_stdout
sys.stderr = old_stderr
error_info = f"**Code Executed:**n```pythonn{code}n```nn**Runtime Error:**n{str(e)}n**Error Type:** {type(e).__name__}"
self.execution_history.append({
'code': code,
'output': '',
'result': None,
'error': str(e)
})
return error_info
def get_execution_history(self) -> List(Dict(str, Any)):
return self.execution_history
def clear_history(self):
self.execution_history = ()This PythonREPLTOOL sums up a Python Rept de processes with State: it captures and executes arbitrary code (evaluation of expressions or instructions in progress), Redirect Stdout / Sterr to record outings and errors, and maintains a history of each execution. The return of a formatted summary, including the code executed, any console output or errors and return values, provides transparent and reproducible feedback for each extraction extract within our agent.
class ResultValidator:
def __init__(self, python_repl: PythonREPLTool):
self.python_repl = python_repl
def validate_mathematical_result(self, description: str, expected_properties: Dict(str, Any)) -> str:
"""Validate mathematical computations"""
validation_code = f"""
# Validation for: {description}
validation_results = {{}}
# Get the last execution results
history = {self.python_repl.execution_history}
if history:
last_execution = history(-1)
print(f"Last execution output: {{last_execution('output')}}")
# Extract numbers from the output
import re
numbers = re.findall(r'\d+(?:\.\d+)?', last_execution('output'))
if numbers:
numbers = (float(n) for n in numbers)
validation_results('extracted_numbers') = numbers
# Validate expected properties
for prop, expected_value in {expected_properties}.items():
if prop == 'count':
actual_count = len(numbers)
validation_results(f'count_check') = actual_count == expected_value
print(f"Count validation: Expected {{expected_value}}, Got {{actual_count}}")
elif prop == 'max_value':
if numbers:
max_val = max(numbers)
validation_results(f'max_check') = max_val = expected_value
print(f"Min value validation: {{min_val}} >= {{expected_value}} = {{min_val >= expected_value}}")
elif prop == 'sum_range':
if numbers:
total = sum(numbers)
min_sum, max_sum = expected_value
validation_results(f'sum_check') = min_sum str:
"""Validate data analysis results"""
validation_code = f"""
# Data Analysis Validation for: {description}
validation_results = {{}}
# Check if required variables exist in global scope
required_vars = {list(expected_structure.keys())}
existing_vars = ()
for var_name in required_vars:
if var_name in globals():
existing_vars.append(var_name)
var_value = globals()(var_name)
validation_results(f'{{var_name}}_exists') = True
validation_results(f'{{var_name}}_type') = type(var_value).__name__
# Type-specific validations
if isinstance(var_value, (list, tuple)):
validation_results(f'{{var_name}}_length') = len(var_value)
elif isinstance(var_value, dict):
validation_results(f'{{var_name}}_keys') = list(var_value.keys())
elif isinstance(var_value, (int, float)):
validation_results(f'{{var_name}}_value') = var_value
print(f"✓ Variable '{{var_name}}' found: {{type(var_value).__name__}} = {{var_value}}")
else:
validation_results(f'{{var_name}}_exists') = False
print(f"✗ Variable '{{var_name}}' not found")
print(f"\nFound {{len(existing_vars)}}/{{len(required_vars)}} required variables")
# Additional structure validation
for var_name, expected_type in {expected_structure}.items():
if var_name in globals():
actual_type = type(globals()(var_name)).__name__
validation_results(f'{{var_name}}_type_match') = actual_type == expected_type
print(f"Type check '{{var_name}}': Expected {{expected_type}}, Got {{actual_type}}")
validation_results
"""
return self.python_repl.run(validation_code)
def validate_algorithm_correctness(self, description: str, test_cases: List(Dict(str, Any))) -> str:
"""Validate algorithm implementations with test cases"""
validation_code = f"""
# Algorithm Validation for: {description}
validation_results = {{}}
test_results = ()
test_cases = {test_cases}
for i, test_case in enumerate(test_cases):
test_name = test_case.get('name', f'Test {{i+1}}')
input_val = test_case.get('input')
expected = test_case.get('expected')
function_name = test_case.get('function')
print(f"\nRunning {{test_name}}:")
print(f"Input: {{input_val}}")
print(f"Expected: {{expected}}")
try:
if function_name and function_name in globals():
func = globals()(function_name)
if callable(func):
if isinstance(input_val, (list, tuple)):
result = func(*input_val)
else:
result = func(input_val)
passed = result == expected
test_results.append({{
'test_name': test_name,
'input': input_val,
'expected': expected,
'actual': result,
'passed': passed
}})
status = "✓ PASS" if passed else "✗ FAIL"
print(f"Actual: {{result}}")
print(f"Status: {{status}}")
else:
print(f"✗ ERROR: '{{function_name}}' is not callable")
else:
print(f"✗ ERROR: Function '{{function_name}}' not found")
except Exception as e:
print(f"✗ ERROR: {{str(e)}}")
test_results.append({{
'test_name': test_name,
'error': str(e),
'passed': False
}})
# Summary
passed_tests = sum(1 for test in test_results if test.get('passed', False))
total_tests = len(test_results)
validation_results('tests_passed') = passed_tests
validation_results('total_tests') = total_tests
validation_results('success_rate') = passed_tests / total_tests if total_tests > 0 else 0
print(f"\n=== VALIDATION SUMMARY ===")
print(f"Tests passed: {{passed_tests}}/{{total_tests}}")
print(f"Success rate: {{validation_results('success_rate'):.1%}}")
test_results
"""
return self.python_repl.run(validation_code)This Resultvalidator class is based on PythonREPLTOOL to automatically generate and execute tailor -made validation routines, check the digital properties, check the data structures or run algorithm tests compared to the agent's execution history. Take extracts from Python that extract the outings, compare them to the expected criteria and summarize the Pass / Fail results closes the loop on “execute → validate” in the workflow of our agent.
python_repl = PythonREPLTool()
validator = ResultValidator(python_repl)
Here, we instance our interactive tool Python Rept (Python_repl), then create a resulting result linked to this same rep. This wiring guarantees that any code you are running is immediately available for automated validation steps, closing the loop on the execution and verification of accuracy.
python_tool = Tool(
name="python_repl",
description="Execute Python code and return both the code and its output. Maintains state between executions.",
func=python_repl.run
)
validation_tool = Tool(
name="result_validator",
description="Validate the results of previous computations with specific test cases and expected properties.",
func=lambda query: validator.validate_mathematical_result(query, {})
)
Here, we wrap our REP and validation methods in Langchain tools, by assigning them clear names and descriptions. The agent can invoke Python_repl to execute the code and the_Validator result to automatically check the last execution compared to your specified criteria.
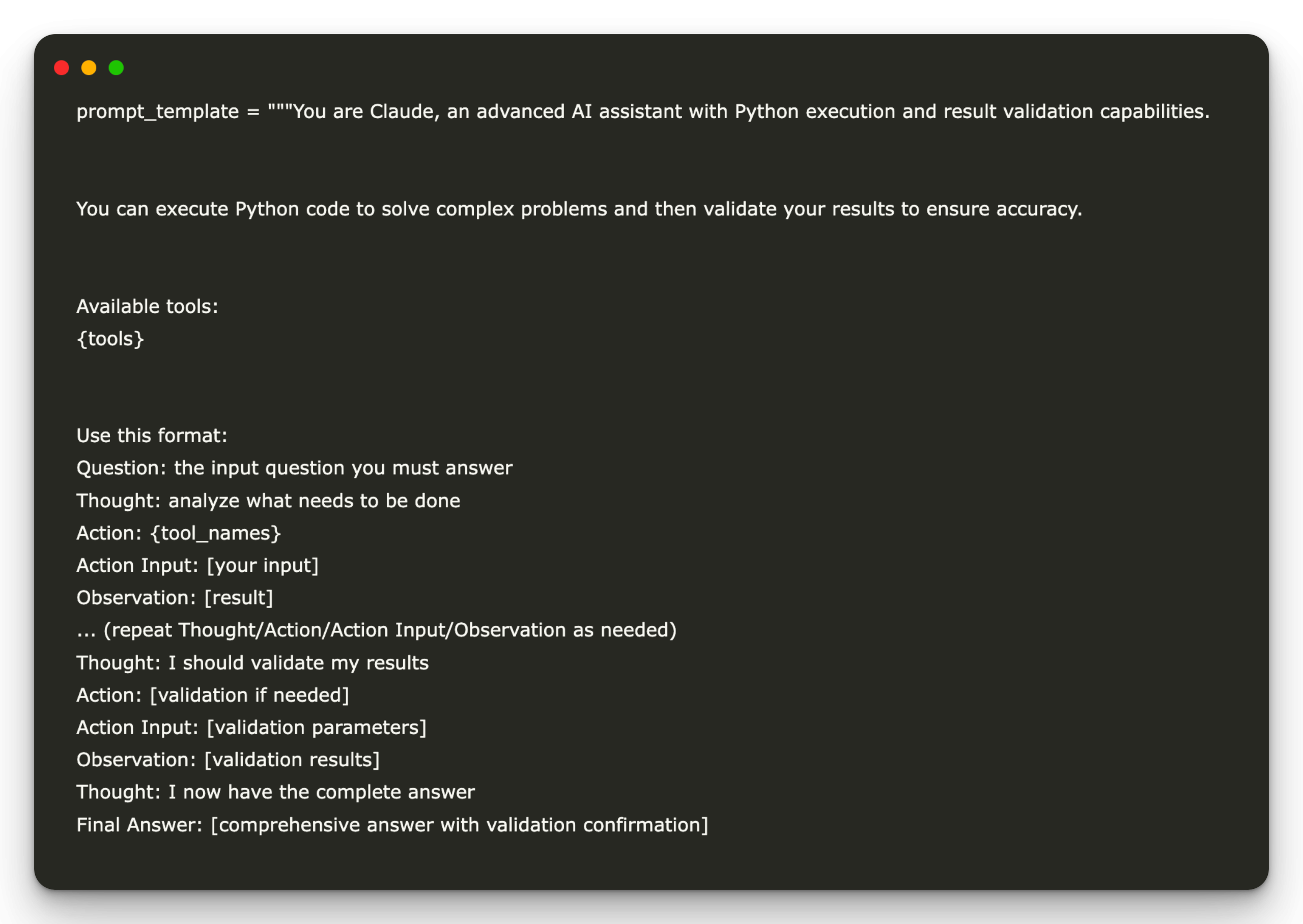
prompt_template = """You are Claude, an advanced AI assistant with Python execution and result validation capabilities.
You can execute Python code to solve complex problems and then validate your results to ensure accuracy.
Available tools:
{tools}
Use this format:
Question: the input question you must answer
Thought: analyze what needs to be done
Action: {tool_names}
Action Input: (your input)
Observation: (result)
... (repeat Thought/Action/Action Input/Observation as needed)
Thought: I should validate my results
Action: (validation if needed)
Action Input: (validation parameters)
Observation: (validation results)
Thought: I now have the complete answer
Final Answer: (comprehensive answer with validation confirmation)
Question: {input}
{agent_scratchpad}"""
prompt = PromptTemplate(
template=prompt_template,
input_variables=("input", "agent_scratchpad"),
partial_variables={
"tools": "python_repl - Execute Python codenresult_validator - Validate computation results",
"tool_names": "python_repl, result_validator"
}
)
Above, the Prominé Claude model frames as a double capacity assistant that reason (“thought”), selects the Python_REPL and Result_Validator tools to execute the code and check the outings, then iteère until it has a validated solution. By defining a clear structure of thought chain with spaces reserved for tool names and their examples of use, he guides the agent for: (1) Decompose the problem, (2) Call Python_repl to execute the necessary code, (3) Call the_Validator result to confirm the correction, and finally (4) deliver an auto-verified “final response”. “This scaffolding guarantees a disciplined workflow” Write → Execute → Validate “.
class AdvancedClaudeCodeAgent:
def __init__(self, anthropic_api_key=None):
if anthropic_api_key:
os.environ("ANTHROPIC_API_KEY") = anthropic_api_key
self.llm = ChatAnthropic(
model="claude-3-opus-20240229",
temperature=0,
max_tokens=4000
)
self.agent = create_react_agent(
llm=self.llm,
tools=(python_tool, validation_tool),
prompt=prompt
)
self.agent_executor = AgentExecutor(
agent=self.agent,
tools=(python_tool, validation_tool),
verbose=True,
handle_parsing_errors=True,
max_iterations=8,
return_intermediate_steps=True
)
self.python_repl = python_repl
self.validator = validator
def run(self, query: str) -> str:
try:
result = self.agent_executor.invoke({"input": query})
return result("output")
except Exception as e:
return f"Error: {str(e)}"
def validate_last_result(self, description: str, validation_params: Dict(str, Any)) -> str:
"""Manually validate the last computation result"""
if 'test_cases' in validation_params:
return self.validator.validate_algorithm_correctness(description, validation_params('test_cases'))
elif 'expected_structure' in validation_params:
return self.validator.validate_data_analysis(description, validation_params('expected_structure'))
else:
return self.validator.validate_mathematical_result(description, validation_params)
def get_execution_summary(self) -> Dict(str, Any):
"""Get summary of all executions"""
history = self.python_repl.get_execution_history()
return {
'total_executions': len(history),
'successful_executions': len((h for h in history if not h('error'))),
'failed_executions': len((h for h in history if h('error'))),
'execution_details': history
}
This class AdvancedclaudeCODEAGENT ENVELOPPE ENVIRTIVE TO A single interface easy to use: it configures the anthropic Claude Customer (using your API key), instance a reactive style agent with our executor Python_repl and iterative → CODER → VALATED “. Its RUN () method allows you to submit requests in natural language and returns the final response and Claude;
if __name__ == "__main__":
API_KEY = "Use Your Own Key Here"
agent = AdvancedClaudeCodeAgent(anthropic_api_key=API_KEY)
print("🚀 Advanced Claude Code Agent with Validation")
print("=" * 60)
print("n🔢 Example 1: Prime Number Analysis with Twin Prime Detection")
print("-" * 60)
query1 = """
Find all prime numbers between 1 and 200, then:
1. Calculate their sum
2. Find all twin prime pairs (primes that differ by 2)
3. Calculate the average gap between consecutive primes
4. Identify the largest prime gap in this range
After computation, validate that we found the correct number of primes and that all identified numbers are actually prime.
"""
result1 = agent.run(query1)
print(result1)
print("n" + "=" * 80 + "n")
print("📊 Example 2: Advanced Sales Data Analysis with Statistical Validation")
print("-" * 60)
query2 = """
Create a comprehensive sales analysis:
1. Generate sales data for 12 products across 24 months with realistic seasonal patterns
2. Calculate monthly growth rates, yearly totals, and trend analysis
3. Identify top 3 performing products and worst 3 performing products
4. Perform correlation analysis between different products
5. Create summary statistics (mean, median, standard deviation, percentiles)
After analysis, validate the data structure, ensure all calculations are mathematically correct, and verify the statistical measures.
"""
result2 = agent.run(query2)
print(result2)
print("n" + "=" * 80 + "n")
print("⚙️ Example 3: Advanced Algorithm Implementation with Test Suite")
print("-" * 60)
query3 = """
Implement and validate a comprehensive sorting and searching system:
1. Implement quicksort, mergesort, and binary search algorithms
2. Create test data with various edge cases (empty lists, single elements, duplicates, sorted/reverse sorted)
3. Benchmark the performance of different sorting algorithms
4. Implement a function to find the kth largest element using different approaches
5. Test all implementations with comprehensive test cases including edge cases
After implementation, validate each algorithm with multiple test cases to ensure correctness.
"""
result3 = agent.run(query3)
print(result3)
print("n" + "=" * 80 + "n")
print("🤖 Example 4: Machine Learning Model with Cross-Validation")
print("-" * 60)
query4 = """
Build a complete machine learning pipeline:
1. Generate a synthetic dataset with features and target variable (classification problem)
2. Implement data preprocessing (normalization, feature scaling)
3. Implement a simple linear classifier from scratch (gradient descent)
4. Split data into train/validation/test sets
5. Train the model and evaluate performance (accuracy, precision, recall)
6. Implement k-fold cross-validation
7. Compare results with different hyperparameters
Validate the entire pipeline by ensuring mathematical correctness of gradient descent, proper data splitting, and realistic performance metrics.
"""
result4 = agent.run(query4)
print(result4)
print("n" + "=" * 80 + "n")
print("📋 Execution Summary")
print("-" * 60)
summary = agent.get_execution_summary()
print(f"Total code executions: {summary('total_executions')}")
print(f"Successful executions: {summary('successful_executions')}")
print(f"Failed executions: {summary('failed_executions')}")
if summary('failed_executions') > 0:
print("nFailed executions details:")
for i, execution in enumerate(summary('execution_details')):
if execution('error'):
print(f" {i+1}. Error: {execution('error')}")
print(f"nSuccess rate: {(summary('successful_executions')/summary('total_executions')*100):.1f}%")Finally, we institute the AdvancedclaudeCODEAGENT with your anthropogenic API key, let us have four illustrative examples (covering the first -rate analysis, the analysis of the sales data, the algorithm implementations and a simple Ml pipeline) and print each validated result. Finally, it brings together and displays a summary of concise execution, total executions, successes, failures and error details, demonstrating the live work flow of the agent “Write → Execute → Validate”.
In conclusion, we have developed an AdvancedCaudeCocement AdvancedCodeagent Polyvalent capable of perfectly mixing generative reasoning with a precise calculation control. Basically, this agent is not content to write extracts from Python; It executes them on site and checks their accuracy in relation to your specified criteria, automatically closing the feedback loop. Whether you carry out first -rate analyzes, statistical data assessments, a comparative analysis of algorithm or ML work flows from start to finish, this model guarantees reliability and reproducibility.
Discover the GitHub notebook. All the merit of this research goes to researchers in this project. Also, don't hesitate to follow us Twitter And don't forget to join our 95K + ML Subdreddit and subscribe to Our newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc .. as a visionary entrepreneur and engineer, AIF undertakes to exploit the potential of artificial intelligence for social good. His most recent company is the launch of an artificial intelligence media platform, Marktechpost, which stands out from its in-depth coverage of automatic learning and in-depth learning news which are both technically solid and easily understandable by a large audience. The platform has more than 2 million monthly views, illustrating its popularity with the public.
