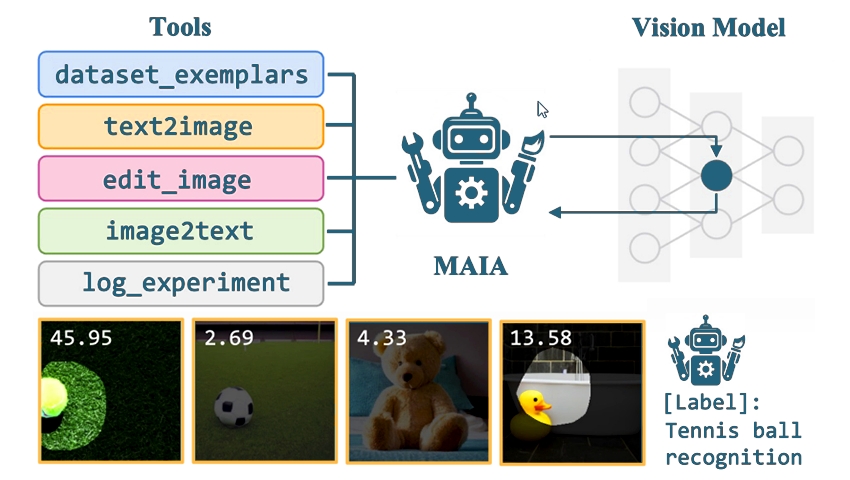
As artificial intelligence systems (AI) are becoming more and more complex, understanding their internal functioning is crucial for safety, equity and transparency. Researchers from the IT and artificial MIT (CSAIL) computer laboratory introduced an innovative solution called “Maia” (Multimodal Automated Interpretability Agent)A system that automates the interpretability of neural networks.
Maia is designed to meet the challenge of understanding important and complex AI models. It automates the interpretation process of computer vision models, which assess different properties of images. Maia operates a visual language model skeleton combined with a library of interpretability tools, allowing it to carry out experiments on other AI systems.
According to Tamar Rott Shaham, co-author of the research document, their objective was to create an AI researcher who can conduct interpretation experiences independently. Since existing methods label or visualize data in a process, Maia, however, can generate hypotheses, design experiences to test them and refine its understanding by iterative analysis.
Maia's capacities are demonstrated in three key tasks:
- Component labeling: Maia identifies individual components in vision models and describes the visual concepts that activate them.
- Model cleaning: By removing the non -relevant characteristics of image classifiers, Maia improves their robustness in new situations.
- Biases detection: Maia hunts hidden biases, helping to discover potential equity problems in AI results.
One of the notable characteristics of Maia is its ability to describe the concepts detected by individual neurons in a vision model. For example, a user could ask Maia to identify what a specific neuron detects. Maia recovers the “examples of data set” of imagenet which activate the neuron as much as possible, distance the causes of the activity of the neuron and designs experiences to test these hypotheses. By generating and modifying synthetic images, Maia can isolate the specific causes of the activity of a neuron, a bit like a scientific experience.
MAIA's explanations are assessed using synthetic systems with known behaviors and new automated protocols for real neurons in AI systems formed. The method led by CSAIL has surpassed the basic methods to describe neurons in various vision models, often corresponding to the quality of the descriptions written by man.
The field of interpretability evolves alongside the rise of “Black Box” automatic learning models. Current methods are often limited in scale or precision. The researchers aimed to build a flexible and scalable system to answer various interpretation questions. The detection of biases in image classifiers was a field of critical development. For example, Maia has identified a bias in a classifier who misunderstood the images of black labradors while accurately classifying the retrievers with yellow fur.
Despite its forces, Maia's performances are limited by the quality of its external tools. As image synthesis and other tools improve, Maia's efficiency too. Researchers have also implemented a text image tool to mitigate confirmation biases and over-adjustment problems.
For the future, researchers plan to apply experiences similar to human perception. Traditionally, the test of human visual perception has been at the high intensity of labor. With Maia, this process can be put on the scale, potentially allowing comparisons between human and artificial visual perception.
Understanding neural networks is difficult due to their complexity. Maia helps to fill this gap by automatically analyzing the neurons and reporting the results in a digestible manner. The scaling of these methods could be crucial to understand and supervise AI systems.
Maia's contributions extend beyond the academic world. As AI is an integral part of various fields, the interpretation of its behavior is essential. Maia packers the gap between complexity and transparency, which makes AI systems more responsible. By equipping AI researchers with tools that follow the pace of system scaling, we can better understand and meet the challenges posed by new AI models.
For more details, research is published on the Arxiv preparation server.