LLM translation systems have become so advanced that they can surpass human translators in some cases. As the LLM improves, in particular in complex tasks such as translation at the document or literary, it becomes more and more difficult to progress more and to assess these progress with precision. Traditional automated measures, like blue, are still used but fail to explain why a score is given. With the quality of translation reaching almost human levels, users need evaluations that extend beyond digital measures, offering reasoning through key dimensions, such as precision, terminology and adequacy of the audience. This transparency allows users to assess assessments, identify errors and make more informed decisions.
Although blue has long been the standard to assess the machine translation (MT), its usefulness fades while modern systems now compete or now surpass human translators. More recent metrics, such as Bleurt, Comet and Metricx, refine powerful language models to assess the quality of translation more precisely. Large models, such as GPT and PALM2, can now offer zero or structured assessments, even generating MQM style feedback. Techniques such as pairs comparison have also improved alignment with human judgments. Recent studies have shown that asking for models to explain their choices improves the quality of the decision; However, these methods based on justification are always underused in the evaluation of MT, despite their growth potential.
Sakana researchers.ai have developed a trancevalnie, an assessment and translation classification system that uses incentive reasoning to assess the quality of the translation. It provides detailed comments using selected MQM dimensions, classifies translations and attributes scores on a 5 -point Likert scale, including a global note. The system works competitively, or even better than the first model of Ranker MT through several language pairs and tasks, including English-Japanese, Chinese-English, etc. Tested with LLM like Claude 3.5 and Qwen-2.5, his judgments have lined up on human assessments. The team also addressed the position bias and published all the data, the reasoning and the code for public use.
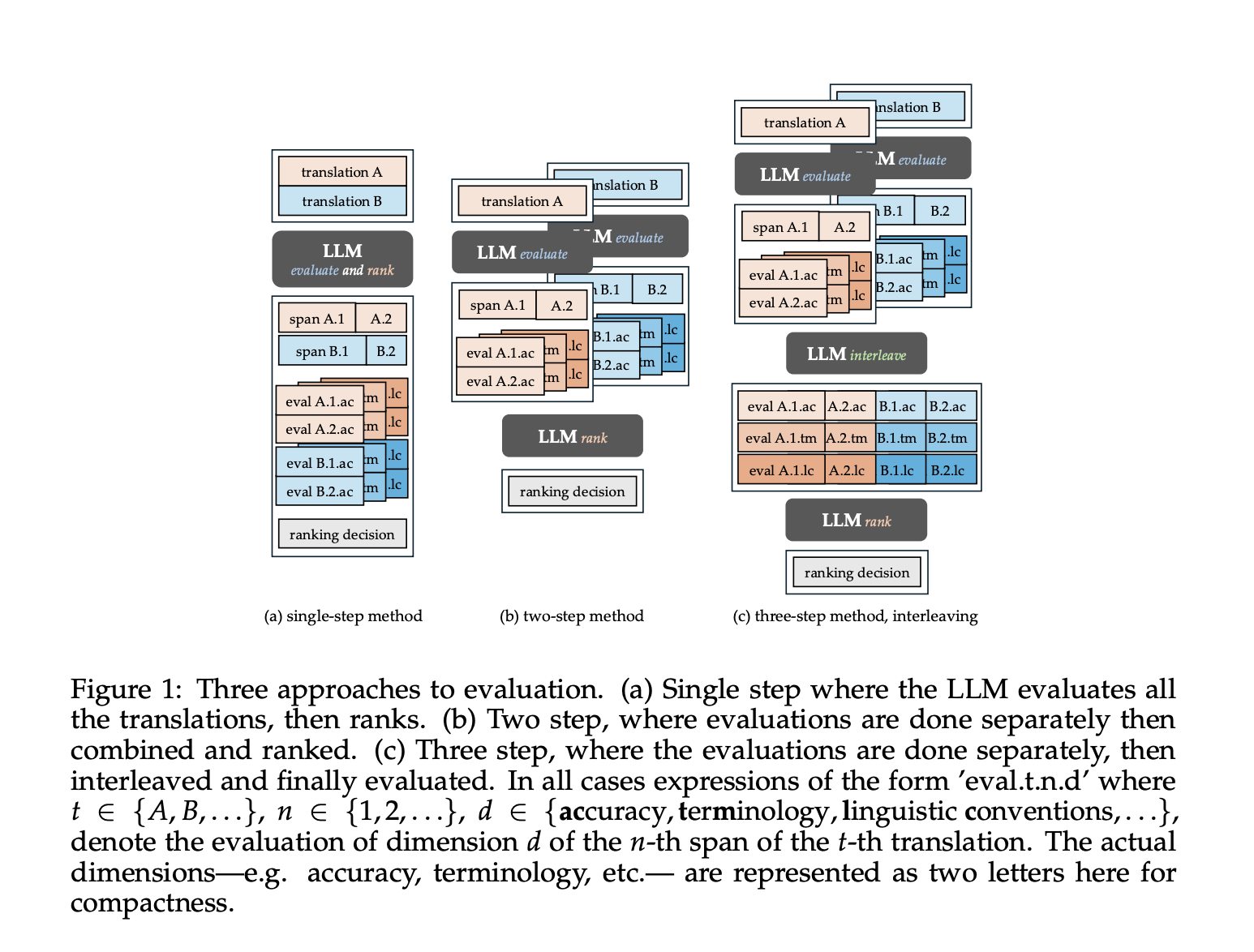
The methodology focuses on the evaluation of translations through key quality aspects, in particular precision, terminology, the relevance of the audience and the clarity. For poetic texts like Haikus, the emotional tone replaces the standard grammar checks. The translations are broken down and evaluated by Span, noted on a scale 1 to 5, then classified. To reduce the bias, the study compares three evaluation strategies: a single step, in two stages and a more reliable intertwined method. A “without restart” method is also tested but lacks transparency and is subject to biases. Finally, human experts have examined certain translations to compare their judgments with those of the system, providing information on its alignment on professional standards.
The researchers evaluated the translation classification systems using data sets with human scores, comparing their models of Transevalnie (Qwen and Sonnet) with MT-RANKER, Comme-22/23, XCOMET-XXL and METRICX-XXL. On WMT-2024 EN-ES, Mt-Ranker worked best, probably due to rich training data. However, in most other data sets, Transevalnia has corresponded or outperformed the Ranker MT; For example, Qwen's tireless approach led to a victory on WMT-2023 in. The position bias was analyzed using inconsistency scores, where intertwined methods often had the lowest bias (for example, 1.04 on hard). Human evaluators gave Sonnet the highest global Likert scores (4.37–4.61), sonnet assessments correlating well with human judgment (R ~ 0.51–0.54 of Spearman).

In conclusion, the trancevalnia is an incentive system to assess and classify translations using LLMS like Claude 3.5 Sonnet and Qwen. The system provides detailed scores through key quality dimensions, inspired by the MQM frame, and selects the best translation between options. It often corresponds or often surpasses the Ranker MT on several WMT language pairs, although Metricx-XXL leads on WMT due to a fine adjustment. Human assessors found that sonnet's results were reliable and the scores showed a strong correlation with human judgments. Performance has improved improved performance. The team also explored solutions to position the bias, a persistent challenge in classification systems and shared all the evaluation data and the code.
Discover the Paper here. Do not hesitate to Consult our tutorial page on the AI agent and agency AI for various applications. Also, don't hesitate to follow us Twitter And don't forget to join our Subseubdredit 100k + ml and subscribe to Our newsletter.
Sana Hassan, consulting trainee at Marktechpost and double -degree student at Iit Madras, is passionate about the application of technology and AI to meet the challenges of the real world. With a great interest in solving practical problems, it brings a new perspective to the intersection of AI and real life solutions.
