In -depth research officers (DR) quickly gained popularity in research and industry, thanks to recent progress in LLM. However, the most popular DR agents are not conceived with human thought and writing processes. They often lack structured steps that support human researchers, such as writing, research and use of comments. Current DR agents compile testing time algorithms and various tools without cohesive frameworks, highlighting the critical need for specially designed frames which can correspond or excel human research capacities. The absence of cognitive process of human inspiration in current methods creates a gap between the way humans do the research and the way in which AI agents manage complex research tasks.
Existing work, such as time scaling, use iterative refinement algorithms, debate mechanisms, tournaments for the classification of hypotheses and autocritic systems to generate research proposals. Multi-agent systems use planners, coordinators, researchers and journalists to produce detailed responses, while certain executives allow human co-pilot modes for feedback. Agent adjustment approaches focus on training through multitasking learning objectives, the fine -supervised component adjustment and strengthening learning to improve research and navigation capacities. The LLM diffusion models try to break the self -regressive sampling hypotheses by generating complete noisy drafts and iterative tokens for high quality outings.
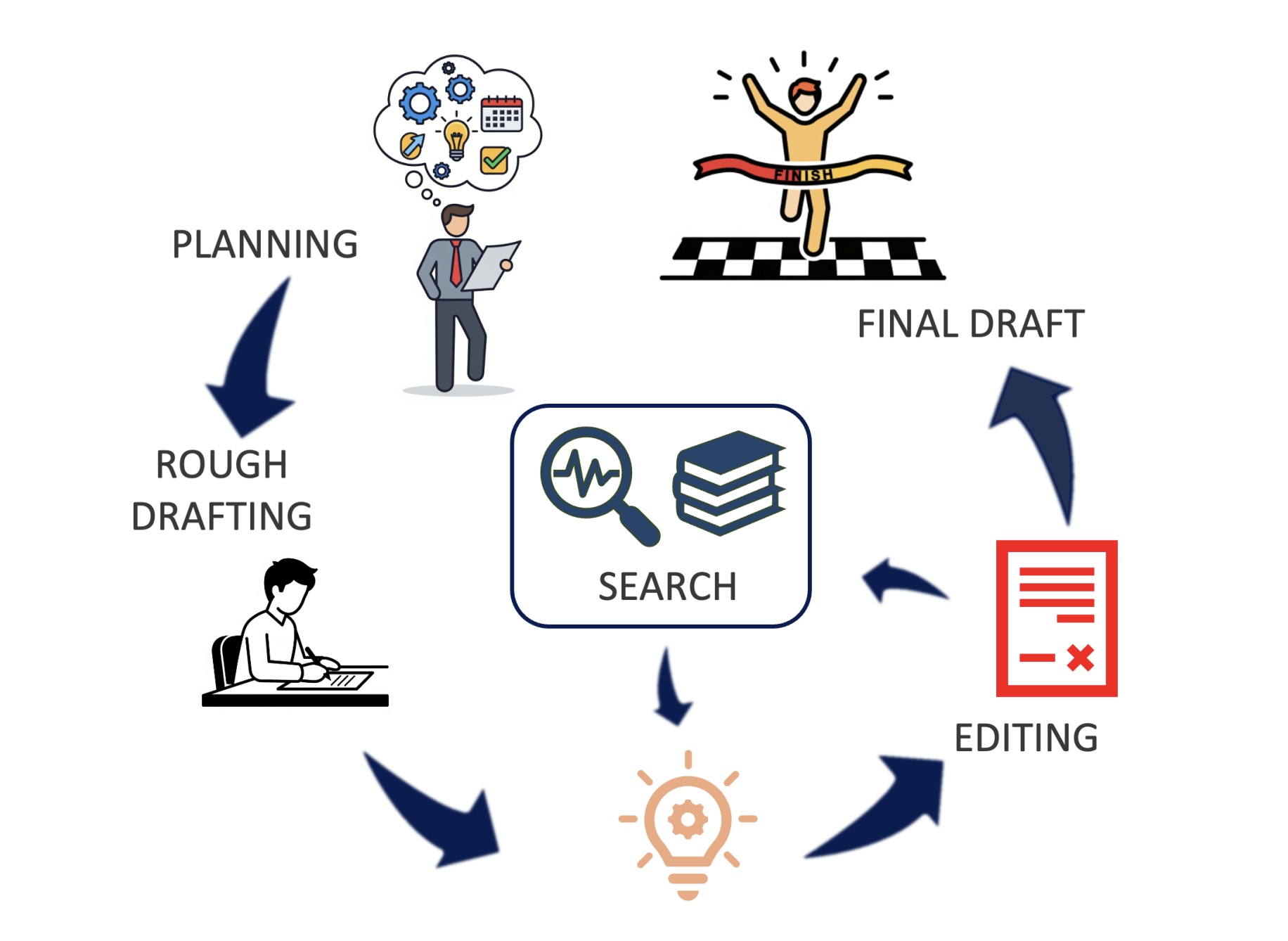
Google researchers have introduced the researcher in depth of testing test (TTD-DR), inspired by the iterative nature of human research through repeated cycles of research, reflection and refining. He conceptualizes the generation of research reports as a dissemination process, starting with a project which serves as a updated plan and evolving foundation to guide the orientation of research. The project undergoes an iterative refinement through a process of “scouring”, dynamically informed by a recovery mechanism which incorporates external information at each stage. This project focused on the project makes reporting more timely and consistent while reducing the loss of information during iterative research processes. TTD-DR obtains advanced results on benchmarks that require intensive research and multi-hop reasoning.

The TTD-DR framework deals with the limits of existing DR agents that use linear or parallelized processes. The proposed Dr. Backbone agent contains three main steps: the generation of research plan, research and iterative synthesis and the generation of final report, each containing agents of the LLM unit, workflows and agent states. The agent uses auto-evolutive algorithms to improve the performance of each step, helping him to find and preserve a high quality context. The proposed algorithm, inspired by recent self-evolution works, is implemented in a parallel work flow as well as sequential and loop workflows. This algorithm can be applied to the three stages of agents to improve the overall exit quality.
In comparisons side by side with the in-depth research OPENAI, TTD-DR reaches 69.1% and 74.5% victory rate for long research generation tasks, while surpassing 4.8%, 7.7% and 1.7% on three sets of research data with short-ground responses. It shows high performance in the Automobiles of Aid and Completely Automobiles, in particular on long -form research data sets. In addition, the self-assessment algorithm reaches 60.9% and 59.8% victory rate against OPENAI deep research on long-term and depth-shaped research. The accuracy score shows an improvement of 1.5% and 2.8% on HLE data sets, although GAIA performance remains 4.4% below OPENAI DR. The incorporation of diffusion with recovery leads to substantial gains on in -depth research OPENAI in all references.

In conclusion, Google presents TTD-DR, a method that addresses fundamental limits thanks to the cognitive conception of human inspiration. The approach of the framework conceptualizes the generation of research reports as a distribution process, using an up -to -date project skeleton that guides the research management. TTD-DR, improved by auto-evolutive algorithms applied to each component of work flows, ensures a high quality context generation throughout the research process. In addition, the evaluations show that the advanced performance of TTD-DR through various references which require intensive research and multi-hop reasoning, with results superior both in complete research reports and concise multi-hop reasoning tasks.
Discover the Paper here. Do not hesitate to Consult our tutorial page on the AI agent and agency AI for various applications. Also, don't hesitate to follow us Twitter And don't forget to join our Subseubdredit 100k + ml and subscribe to Our newsletter.

Sajjad Ansari is a last year's first year of the Kharagpur Iit. As a technology enthusiast, he plunges into AI's practical applications by emphasizing the understanding of the impact of AI technologies and their real implications. It aims to articulate complex AI concepts in a clear and accessible way.
