The discipline of epigraphy, focused on the study of texts inscribed on sustainable materials such as stone and metal, provides critical evidence of first -hand to understand the Roman world. The field is faced with many challenges, including fragmentary inscriptions, uncertain meetings, a diversified geographical origin, a widespread use of abbreviations and a significant and rapid corpus of more than 176,000 Latin inscriptions, with around 1,500 new inscriptions added each year.
To meet these challenges, Google Deepmind has developed Aeneas: A network of generative neurons based on a transformer that restores damaged text segments, chronological dating, geographic allocation and contextualization by recovery of relevant epigraphic parallels.
Latin epigraphy challenges
Latin inscriptions extend over more than two millennia, from ECO from the 7th century to the 8th century, through the vast Roman Empire comprising more than sixty provinces. These inscriptions vary from imperial decrees and legal documents to tombstones and votive altars. The epigraphs traditionally restore partially lost or illegible texts using detailed knowledge of the language, formulas and cultural context, and attribute inscriptions to certain deadlines and locations by comparing linguistic and material proofs.
However, many inscriptions suffer from physical damage with missing segments of uncertain lengths. The large geographical dispersion and diachronic linguistic changes make the encounter allocation complex and provenance, especially when combined with the size of the transparent corpus. Manual identification of epigraphic parallels is with a high intensity of labor and often limited by specialized expertise located in certain regions or periods.

Latin epigraphic data set (LED)
Aeneas is formed on the Latin epigraphic data set (LED)An integrated and harmonized corpus of 176,861 Latin inscriptions aggregating the records of three major databases. The data set includes around 16 million characters covering inscriptions extending over seven centuries before our eight eight centuries. About 5% of these registrations have associated images in gray levels.
The data set uses transcriptions in terms of characteristics using special spacers: - marks the missing text of a known length during # Indicates missing segments of unknown length. Metadata include provenance at the province of 62 Roman provinces dating from the decade.
Model architecture and entry methods
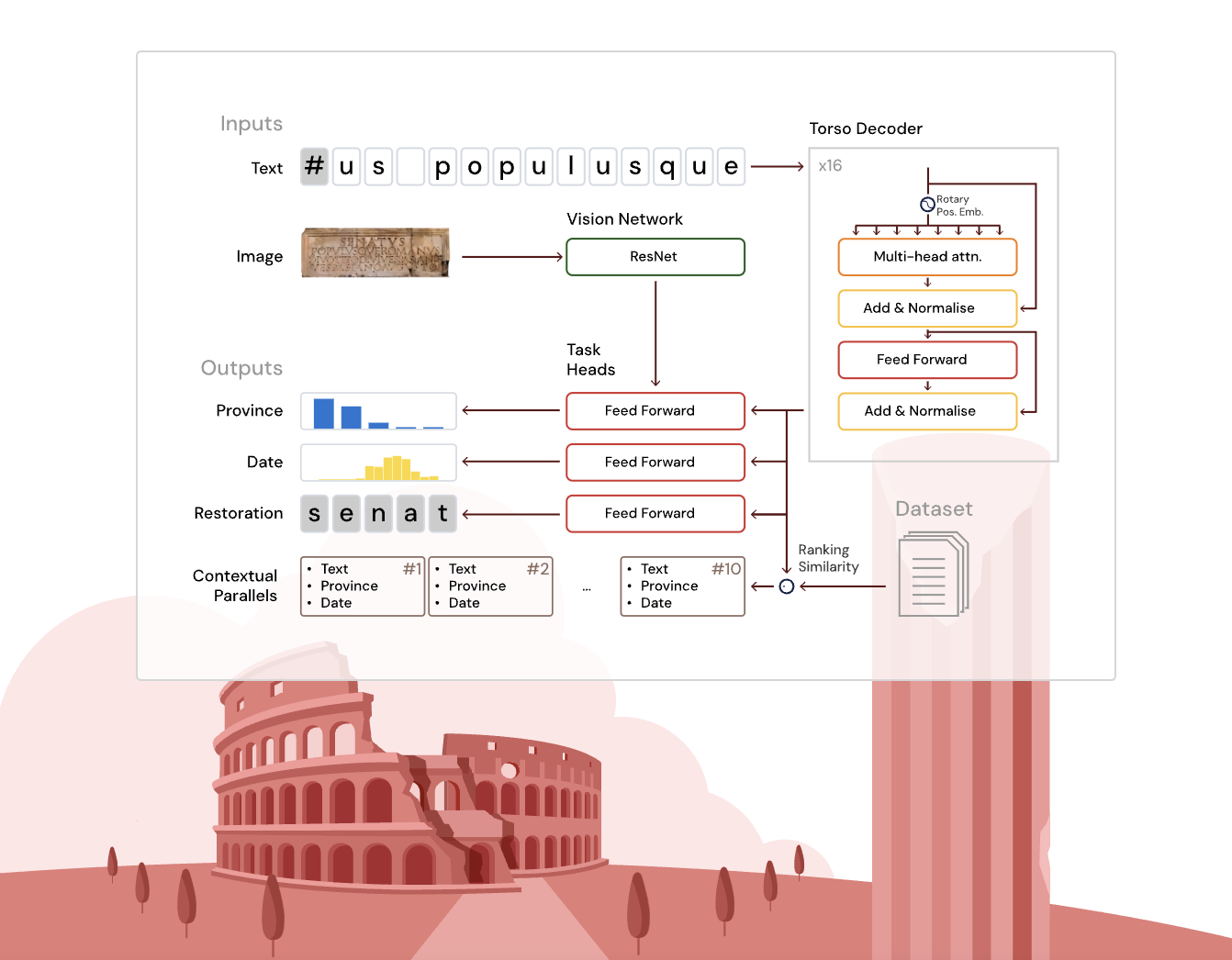
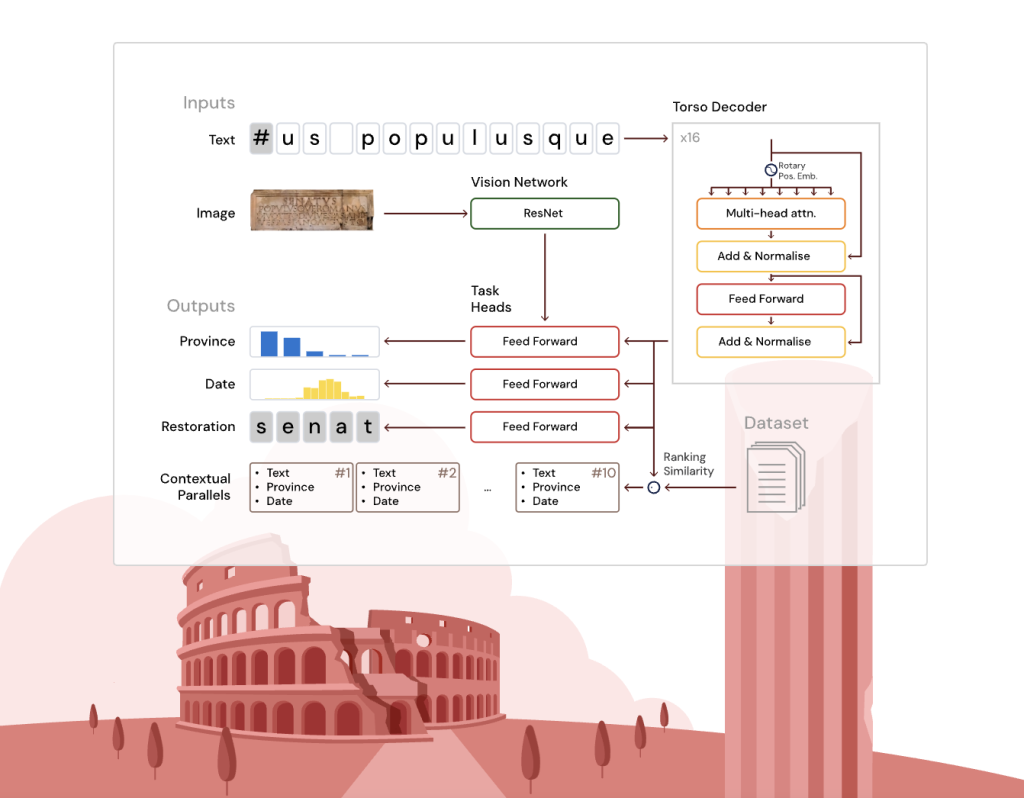
The Aeneas nucleus is a deep and narrow transformer decoder based on the T5 architecture, suitable with rotating position incorporations for an effective treatment of a local and contextual character. The textual entry is processed alongside optional registration images (when available) via a surface convolution network (Resnet-8), which supplies the incorporations of images at the geographic allocation head only.
The model includes several specialized tasks to be performed:
- Restoration: Predict the missing characters, taking charge of the unknown gaps of arbitrary length using an auxiliary neural classifier.
- Geographic allocation: Classify inscriptions among 62 provinces by combining text and visual incorporations.
- Chronological allocation: Consider the date of the decade text using a predictive probabilistic distribution aligned with the ranges of historical dates.
In addition, the model generates a historically enriched unified integration by combining the outputs of the nucleus and task heads. This integration allows the recovery of classified epigraphic parallels using the similarity of the Cosinus, incorporating linguistic, epigraphic and broader cultural analogies beyond exact textual correspondence.
Training configuration and data increase
The training occurs on TPU V5E equipment with lots of lots up to 1024 text image pairs. The losses for each task are combined with optimized weighting. The data is increased by a masking of random text (up to 75% of characters), the screening of the text, the deletions of words, the punctuation fall, the image increases (zoom, rotation, brightness / contrast adjustments), labeled deposit and smoothing to improve generalization.
The prediction uses beam search with a specialized non -sequential logic for the restoration of text of unknown length, guaranteeing several catering candidates classified by probability and joint length.
Performance and evaluation
Assessed on the set of LED tests and thanks to a study of human-AI collaboration with 23 epigraphs, Aeneas demonstrates marked improvements:
- Restoration: The character error rate (CER) has been reduced to around 21% when Eneas support is provided, compared to 39% for human experts without aid. The model itself reaches approximately 23% Cer on the test.
- Geographic allocation: Reaches an accuracy of around 72% to properly classify the province among 62 options. With ENEAS assistance, historians improve precision up to 68%, surpassing one.
- Chronological allocation: The average error in the estimate of the dates is approximately 13 years for the Eeneas, historians helped by the Eeneas reducing the error from about 31 years to 14 years.
- Contextual parallels: Recovered epigraphic parallels are accepted as starting points useful for historical research in approximately 90% of cases and increase the confidence of historians on average by 44%.
These improvements are statistically significant and highlight the usefulness of the model as an increase in the expert scholarship.
Case studies
Res gestae divi Augusti:
The analysis by Aeneas of this monumental inscription reveals distributions of bimodal dates reflecting the learned debates on its layers and its stages of composition (end of the first century BCE and beginning of the first century CE). The salt cards highlight the linguistic forms sensitive to the date, archaic spelling, institutional titles and personal names, reflecting expert epigraphic knowledge. The recovered parallels mainly include imperial legal decrees and official senatorial texts sharing formula characteristics and ideological.
Mainz votive altar (CIL XIII, 6665):
Dedicated in 211 CE by a military official, this registration was dated with precision and geographically attributed to the provinces of Germania Superior and Related. Salter cards identify key consular dating formulas and cultic references. Aeneas has recovered very linked parallels, including an altar from 197, this sharing rare textual formulas and iconography, revealing historically significant connections beyond the direct horses of the text or the space metadata.
Integration into research workflows and education
Aeneas operates as a cooperative tool, not to replace historians. It accelerates the search for epigraphic parallels, of catering assistance and refines the attribution, releasing researchers to focus on higher level interpretation. The tool and the data set are openly available via the prediction of the previous platform under permissive licenses. An educational program has been co-developed by targeting secondary school students and educators, promoting interdisciplinary digital literacy by punching AI and classic studies.
FAQ 1: What are Aeneas and what tasks work?
Aeneas is a generative multimodal neural network developed by Google Deepmind for Latin epigraphy. It helps historians in the restaurant of the damaged or missing text in old Latin inscriptions, estimating their date in around 13 years, by attributing their geographic origin with an accuracy of around 72% and by recovering parallel inscriptions historically relevant for contextual analysis.
FAQ 2: How do the Eeneas manage incomplete or damaged inscriptions?
The Eeneas can predict missing text segments even when the length of the space is unknown, a capacity known as the catering of arbitrary length. It uses architecture based on a transformer and network heads of specialized neurons to generate several plausible catering hypotheses, classified by likely, facilitating the evaluation of experts and additional research.
FAQ 3: How is Aeneas integrated into historian work flows?
Aeneas provides historians classified lists with epigraphic parallels and predictive hypotheses for catering, dating and provenance. These results stimulate the confidence and precision of historians, reduce research time by quickly suggesting relevant texts and supporting a human-AI collaborative analysis. The model and data sets are openly accessible via the prediction of the past platform.
Discover the Paper,, Project And Google Deepmind blog. All the merit of this research goes to researchers in this project. Subscribe now to our newsletter IA

Michal Sutter is a data science professional with a master's degree in data sciences from the University of Padova. With a solid base in statistical analysis, automatic learning and data engineering, Michal excels in transforming complex data sets into usable information.