Introduction
Amazon researchers have released MitraA advanced foundation model built for data purposes for tabular data. Unlike traditional approaches that adapt a tailor -made model for each data set, MITRA uses the power of learning in context (ICL) and pre-training synthetic data, achieving advanced performance through tabular automatic learning benchmarks. Integrated into Autogluon 1.4, Mitra is designed to generalize robust, offering a transformative change for practitioners working with structured data in areas such as health care, finance, electronic commerce and sciences.

The Foundation: Learn synthetic priorities
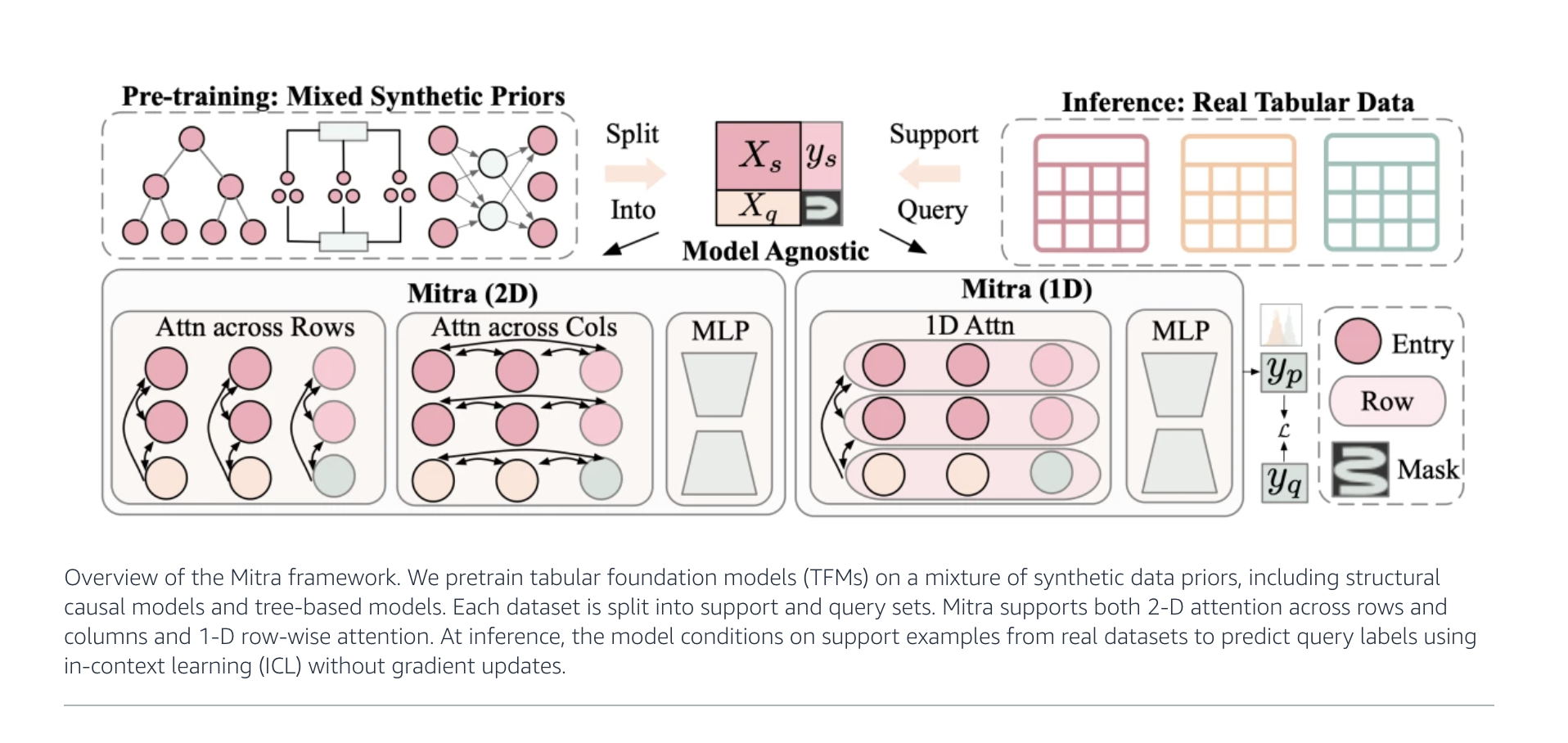
Mitra moves away from the standard by being pre-trained exclusively on synthetic data. Rather than counting on the limited and heterogeneous nature of the tabular data sets of the real world, Amazon researchers have designed a strategy of principle to generate and mix Various synthetic priors. This approach is inspired by the way in which large languages are pre-trained on vast and varied corpus of text.
Key components of Mitra's synthetic pre-training:
- Mixture of priors: Synthetic data sets are generated from a variety of previous distributions, including Structural causal models and trees based on algorithms (such as random forests and gradient strengthening).
- Generalization: The diversity and quality of these prayers guarantee that Mitra learns applicable models in many unforeseen real data sets.
- Task structure: During pre -training, each synthetic task involves a set of support and a set of requests – allowing Mitra to adapt to new tasks via context in context, without requiring parameters updates for each new table.
Learning in context and fine adjustment: adaptation without new models
Traditional tabular Ml Methods like Xgboost and random forests require a new model for each task or distribution of data. On the other hand, MITRA operates learning in context: Given a small number of examples labeled (support set), MITRA can make specific predictions on new invisible data (sets of queries) for classification or regression, adapting to each scenario without recycling.
For users who need additional adaptation, fine tuning is also supported, allowing the model to be adapted to specific tasks if necessary.
Architecture innovations
Mitra uses a 2D attention mechanism Through lines and features, mirroring or extension of architecture progress launched by transformers but specialized for tabular data. This allows the model of:
- Handle variable table sizes and the types of features.
- Capture the complex interactions between table columns and recordings.
- Support heterogeneous data natively, a key challenge in Tabular ML.
Reference performance and practical forces
Results
Mitra reached Peak results On several main tabular benchmarks:

- Tabrepo
- Tabzilla
- Automl benchmark (AMLB)
- Tabarena
His strengths are particularly pronounced On small and medium data sets (less than 5,000 samples, less than 100 features), providing cutting -edge results on both Classification and regression problems. In particular, Mitra surpasses strong base lines such as Tabpfnv2, Tabicl, Catboost and Autogluon Anterior Iterations of Autogluon.

Conviviality
- Available in Autogluon 1.4: MITRA is open-source, with ready-made models for transparent integration into existing ML pipelines.
- Works on GPU and CPU: Optimized for versatility in deployment environments.
- Shared weight on the embraced face: Open-source for user-use and regression use cases.
Future implications and orientations
By learning from a carefully organized mixture of synthetic priors, Mitra brings the generalization of large foundation models to the tabular domain. It is about to accelerate research and apply data science by:
- Reduce time to solution: No need to create and adjust unique models per task.
- Activate cross -domain transfer: Lessons learned from synthetic tasks are largely transferred.
- Promote a new innovation: The synthetic anterior methodology opens the way to richer and more adaptive tabular foundation models in the future.
To start
- Autogluon 1.4 will soon present MITRA for ready -to -use use.
- Open source weights and documents are provided for both classification And regression tasks.
- Researchers and practitioners are encouraged to experiment and rely on this new basis for tabular predictio
Discover the Open weight classification model,, Open weight regression model And Blush. All the merit of this research goes to researchers in this project.
Meet the newsletter of AI dev read by 40K + developers and researchers from Nvidia, Openai, Deepmind, Meta, Microsoft, JP Morgan Chase, Amgen, Aflac, Wells Fargo and 100 others (Subscribe now)
Asif Razzaq is the CEO of Marktechpost Media Inc .. as a visionary entrepreneur and engineer, AIF undertakes to exploit the potential of artificial intelligence for social good. His most recent company is the launch of an artificial intelligence media platform, Marktechpost, which stands out from its in-depth coverage of automatic learning and in-depth learning news which are both technically solid and easily understandable by a large audience. The platform has more than 2 million monthly views, illustrating its popularity with the public.
