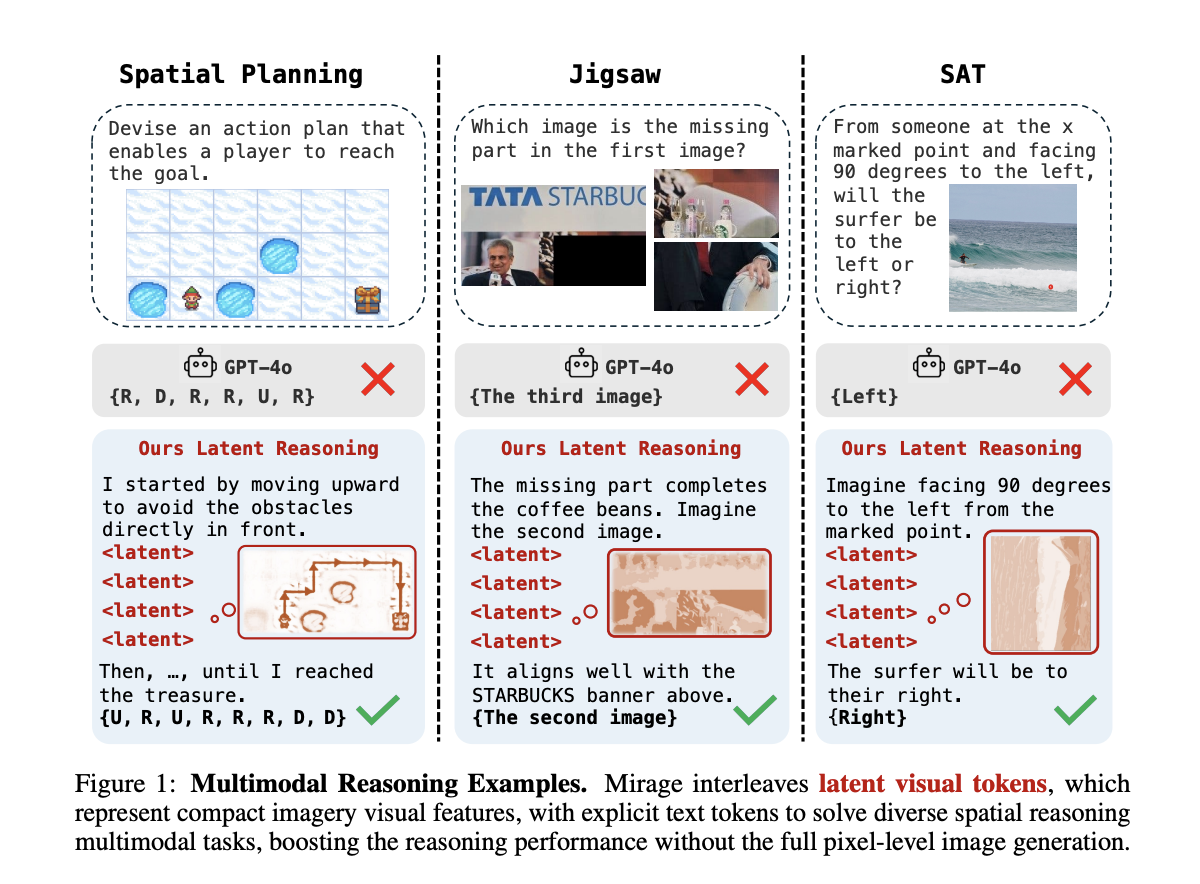
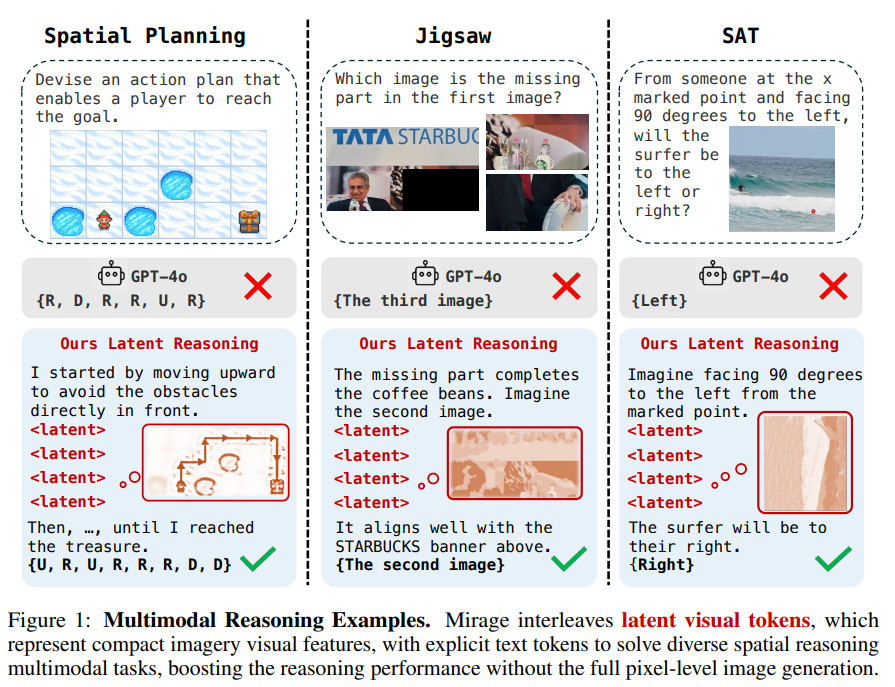
Although the VLMs are strong to understand both the text and the images, they often count only on the text during reasoning, limiting their ability to solve tasks that require visual thinking, such as space puzzles. People naturally view solutions rather than describing every detail, but VLMs have trouble doing the same. Although some recent models can generate both text and images, form them in the generation of images often weakens their ability to reason. Image production does not take visual reasoning step by step either. Consequently, the unlocking of the full potential of VLMs for a complex and visually anchored reflection remains a key challenge in the field.
COT incitement encourages models to reason through problems step by step using examples with intermediate explanations. This idea was extended to multimodal tasks, where visual information is integrated into the reasoning flow. Methods such as ICot integrate image regions in text sequences, while the visual cot uses visual annotations to form models for better spatial understanding. Some recent models can generate both text and images simultaneously; However, they require intense supervision and cause high calculation costs. In addition, researchers explore ways to incorporate internal reasoning into the models by guiding their hidden states, using special tokens or latent representations instead of explicit reasoning stages.

Researchers from the University of Massachusetts Amherst and MIT offer an approach inspired by the way humans use mental imagery, which consists in forming simple and relevant visuals in internal during reflection. They introduce Mirage, a frame that allows VLMS to intervene visual reasoning directly in their text outlets without generating complete images. Instead, the model inserts compact visual indices derived from its hidden states. It is formed in two phases: first with text and visual supervision, then with text advice only. Learning strengthening further refines its reasoning skills. Mirage allows VLMs to think more like humans, thus improving their performance on complex and multimodal tasks.
Mirage is a framework inspired by human mental imagery which allows VLMs to reason using compact visual clues instead of generating complete images. He uses two training stages: first, he founded compressed visual characteristics, called latent tokens, in the reasoning process using joint assistance and supervision images. Then, he relaxes this constraint, allowing the model to generate his latent tokens and use them to guide the reasoning. This configuration allows intertwined multimodal reasoning. A final step in learning to strengthen the model still by using the accuracy and shaping of rewards, encouraging both correct answers and structured reflection processes.
The study assesses the model on four space reasoning tasks, such as visual puzzles and geometry problems, using a small set of data of 1,000 training samples. To support reasoning, it generates images of synthetic assistance and stages of thought, imitating the way humans use sketches and clues to facilitate thought processes. The model constantly surpasses the base lines in text only and multimodal, even in tasks that require in -depth planning, such as labyrinth resolution. A smaller version of the model also gives solid results, demonstrating that the method is robust. Ablation studies confirm that the landing of latent visual tokens first, followed by flexible training, is essential. Overall, visual reasoning and intertwined text without real images increases both understanding and precision.
In conclusion, inspired by the way humans use mental imagery to reason, the study introduces a light approach that allows VLMS to think visually, without ever generating real images. By intertwining compact visual clues with text during decoding, the model learns to reason multimodally through a training process in two phases: first, anchor these clues to real characteristics of the image, then allowing them to evolve freely to support reasoning. A final step in learning to strengthen performance. Tested on space reasoning tasks, the method constantly surpasses traditional text models only. However, challenges remain to be evolved towards other tasks and improving the quality of synthetic training data.
Discover the Paper And GitHub page. All the merit of this research goes to researchers in this project.
| Sponsorship |
|---|
| Reach the most influential AI developers in the world. 1M + monthly players, 500K + community manufacturers, endless possibilities. (Explore sponsorship)) |
Sana Hassan, consulting trainee at Marktechpost and double -degree student at Iit Madras, is passionate about the application of technology and AI to meet the challenges of the real world. With a great interest in solving practical problems, it brings a new perspective to the intersection of AI and real life solutions.