
Vision -language vision models (VLM) play a crucial role in today's intelligent systems by allowing a detailed understanding of visual content. The complexity of multimodal intelligence tasks has developed, ranging from the scientific resolution of problems to the development of autonomous agents. Current requests on VLMs have exceeded the perception of simple visual content, with increasing attention on advanced reasoning. Although recent work shows that long -term reasoning and evolving RL considerably improve LLMS problem solving capacities, current efforts are mainly focused on specific areas to improve VLM reasoning. The open source community is currently lacking in a multimodal reasoning model that surpasses traditional unhealthy models of a comparable parameter scale on various tasks.
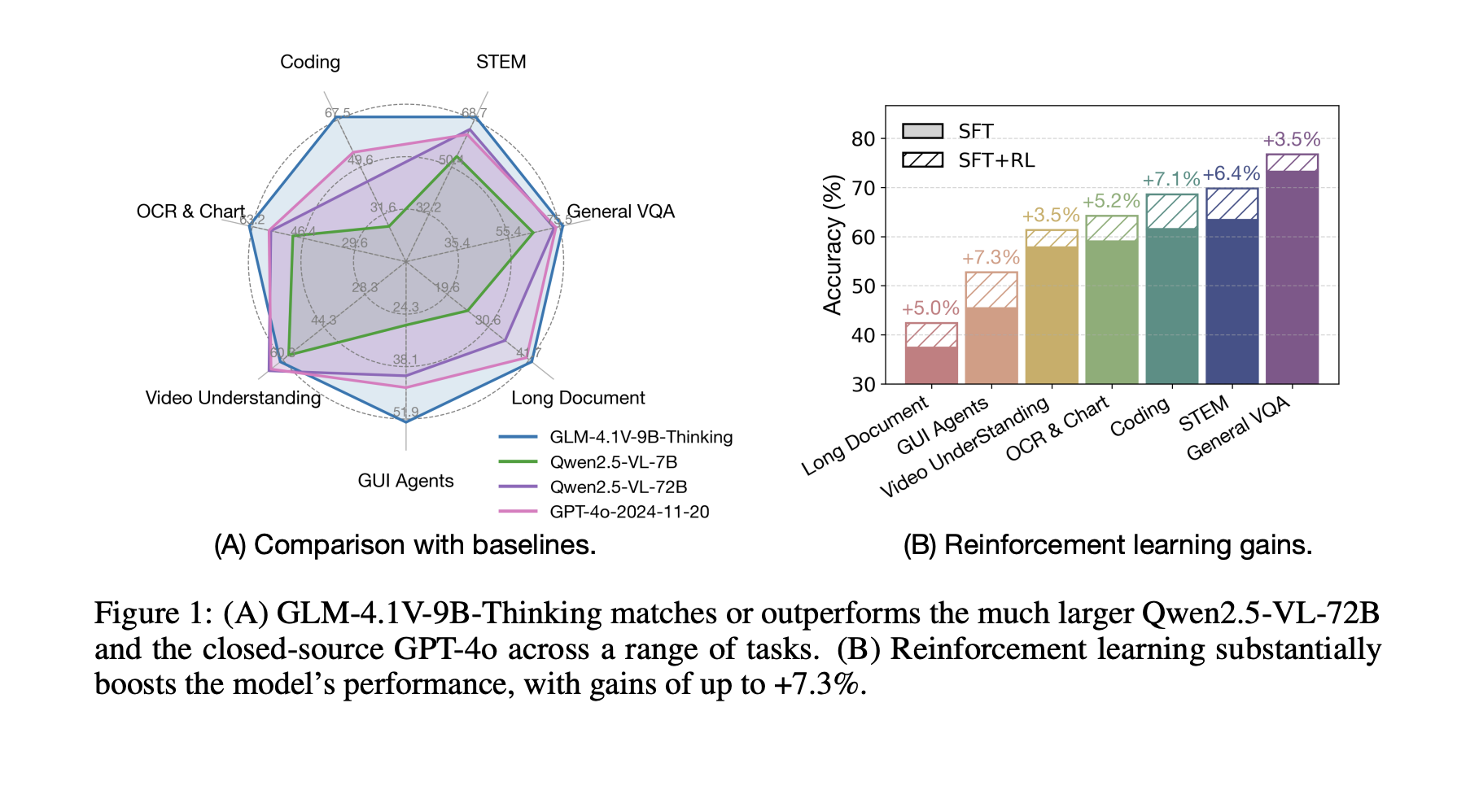
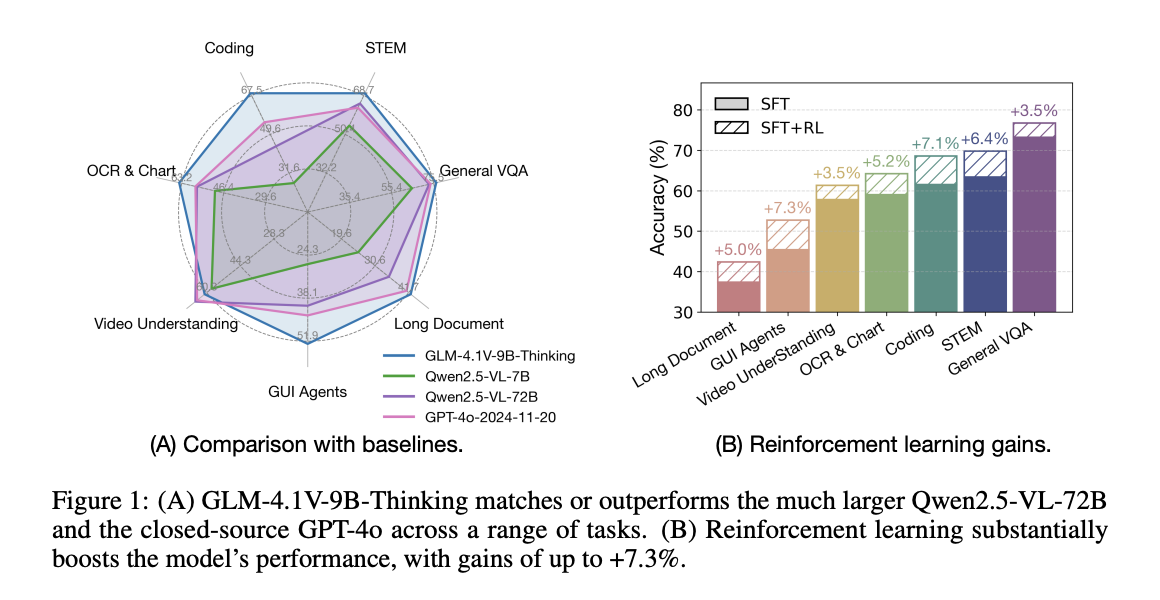
Researchers from Zhipu AI and the University of Tsinghua offered GLM-4.1V-Thinking, a VLM designed to advance general multimodal understanding and reasoning. The approach then introduces learning to strengthen the sampling of the curriculum (RLC) to unlock the full potential of the model, allowing improvements through the resolution of rod problems, video understanding, content recognition, coding, earthing, agents based on the graphical interface and long understanding of the document. GLM-4.1V-9B researchers, which establishes a new reference among similar size models. It also offers competitive performance and, in some cases, proprietary models such as GPT-4O on difficult tasks such as understanding long documents and STEM reasoning.


GLM-4.1V-Thinking contains three central components: a vision encoder, an MLP adapter and an LLM decoder. He uses AIMV2-Huge as a vision coder and GLM as LLM, by replacing the original 2D convolutions with 3D convolutions for time reductions. The model integrates the 2D rope to take charge of arbitrary image resolutions and appearance relationships, and deals with extreme appearance relationships greater than 200: 1 and high resolutions beyond 4K. The researchers extend the 3D rope rope in the LLM to improve spatial understanding in multimodal contexts. For temporal modeling in videos, temporal indexen tokens are added after each frame token, with coded horodatages as chains to help the model understand the temporal gaps of the real world between frames
During pre-training, researchers use a variety of data sets, combining large academic corpus with intertwined image text data. By including pure text data, the basic language language capacities are preserved, which leads to a better passage performance @ k than other pre-formed basic models at the cutting edge of similar size technology. The supervised fine adjustment stage transforms the basic VLM into a single COT inference using a long bite corpus organized through verifiable rod problems, such as non -verifiable tasks such as the following instruction. Finally, the RL phase uses a combination of RLVR and RLHF to conduct large -scale training in all multimodal areas, including rod problem solving, earth setting, optical character recognition, Gui agents and many others.
GLM-4.1V-9B-Thinking surpasses all open source models under 10B settings in general VQA tasks covering the unique and multi-images parameters. It achieves the highest performance on difficult STEM references, including MMMU_VAL, MMMU_Pro, Videommu and AI2D. In the OCR and graphic fields, the model defines new peak scores on Chartqapro and Chartmuseum. For a long understanding of the documents, GLM-4.1V-9B-Thinking surpasses all other models on MmlongBench, while establishing new cutting-edge results in Gui agents and multimodal coding tasks. Finally, the model shows robust video understanding performance, outperforming the empty, MMVU and Motionbench markers.
In conclusion, the researchers introduced the GLM-4.1 v-thinking, which represents a step towards multimodal reasoning for general use. Its 9B parameter model surpasses larger models like the one that exceeds 70b settings. However, several limits remain, such as inconsistent improvements in the quality of reasoning thanks to RL, instability during training and difficulties with complex cases. Future developments should focus on improving the supervision and assessment of the model reasoning, reward models evaluating intermediate reasoning stages while detecting hallucinations and logical inconsistencies. In addition, the exploration of strategies to prevent reward hacking in subjective evaluation tasks is crucial to carrying out general information.
Discover the Paper And GitHub page. All the merit of this research goes to researchers in this project.
| Sponsorship |
|---|
| Reach the most influential AI developers in the world. 1M + monthly players, 500K + community manufacturers, endless possibilities. (Explore sponsorship)) |

Sajjad Ansari is a last year's first year of the Kharagpur Iit. As a technology enthusiast, he plunges into AI's practical applications by emphasizing the understanding of the impact of AI technologies and their real implications. It aims to articulate complex AI concepts in a clear and accessible way.