Mistral Ai published Voxtral, a family of open models –VOXTRAL-SMALL-24B And VOXTRAL-MINI-3B—E designed to manage audio and text inputs. Built above the Mistral language modeling frame, these models integrate automatic speech recognition (ASR) with the capacities of understanding natural language. Released under the APACHE 2.0 license, VOXTRAL provides practical solutions for transcription, summary, answer to questions and the invocation of the vocal function based on the command.
VOXTRAL design is aligned with growing demand for audio treatment integrated into consumer applications and business systems. These models aim to rationalize the common tasks involving a spoken entry, offering a configurable interface devoted to the language.


Model architecture and context management
VOXTRAL relies on the small skeleton Mistral Small 3.1 and incorporates an audio front to allow the processing of spoken and textual data. The two models support a 32,000 context windowActivation:
- Audio transcription up to about 30 minutes
- Extended reasoning or summary for the audio extending up to 40 minutes
This long context support makes it possible to avoid the need to segment or truncate the input audio for most typical use cases, in particular in an analysis or workflow meeting of multimedia documentation.
Key functional capacities
- Transcription performance
- VOXTRAL offers reliable ASR capacities in various acoustic environments.
- Mistral offers dedicated API termination points optimized for low latency transcription tasks, useful in real -time and streaming contexts.
- Multilingual treatment
- VOXTRAL includes automatic language detection.
- It works well in a set of major languages, notably English, Spanish, French, Portuguese, Hindi, German, Dutch and Italian.
- A unique model instance can manage scenarios in mixed language without fine adjustment.
- Audio understanding beyond transcription
- The models can answer questions about audio content (for example, “What has been made of decision?”) And generate concise summaries.
- These tasks can be performed without chaining an ASR model with a separate LLM, reducing the latency and complexity of the system.
- Execution of the vocal function
- VOXTRAL allows the analysis of user intentions directly from the voice and triggering backend actions or workflows accordingly.
- This capacity is relevant to voice assistants, industrial systems and customer service automation.
- Management of text mode
- In addition to audio, Voxtral retains solid performance on text tasks only, due to its base shared with Mistral language models.
- This double modality allows smoother user experiences in multi-interfect applications.
Comparison: variants of the VOXTRAL model
| Model | Parameters | Entry modality | Context duration | Deployment context |
|---|---|---|---|---|
| VOXTRAL-MINI-3B | 3b | Audio + text | 32K chips | Edges or mobile environments |
| VOXTRAL-SMALL-24B | 24b | Audio + text | 32K chips | Cloud, API -based systems |
The variant of the 3B model is set for light deployment and local inference, while the 24B version is suitable for use in production with higher calculation resources.
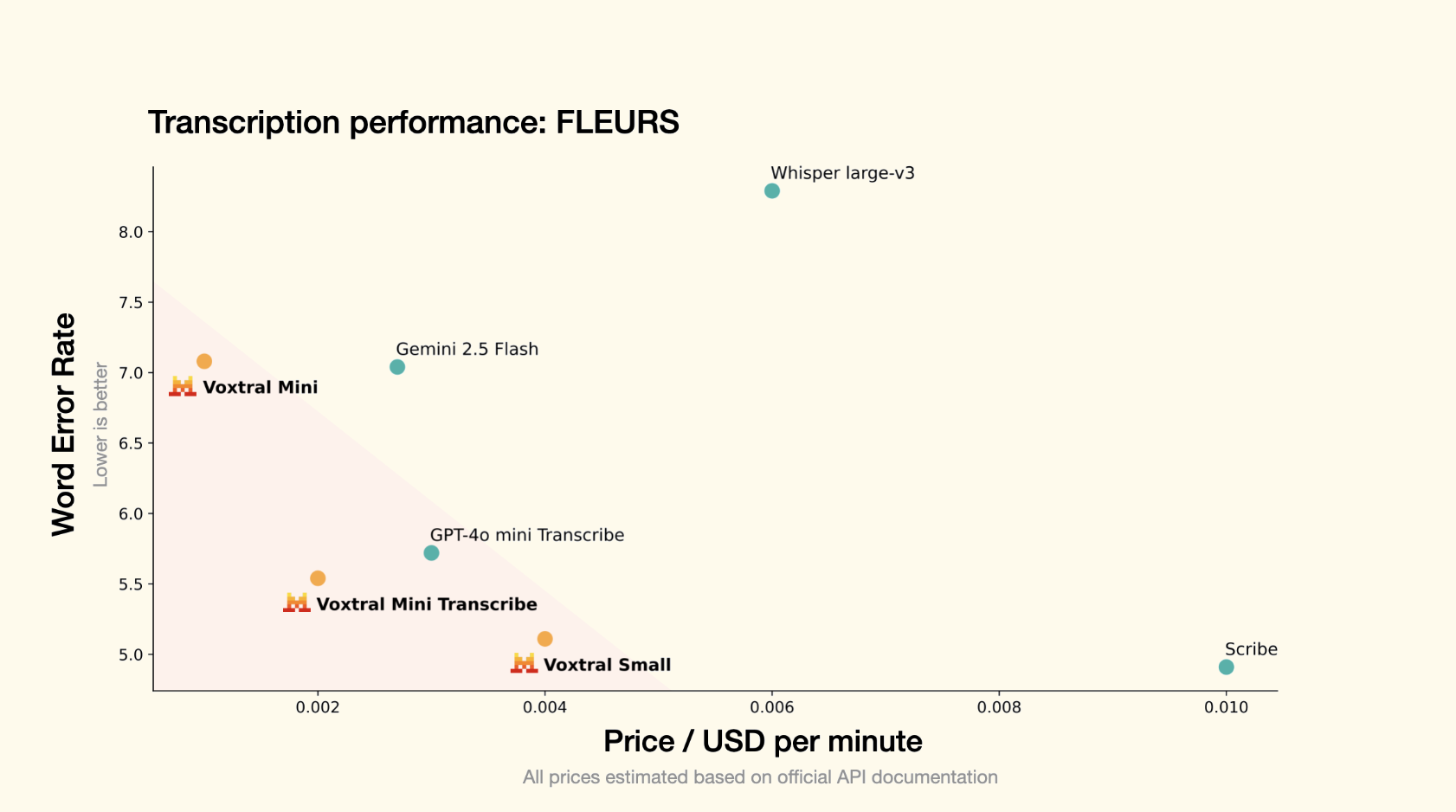
Benchmarks



Deployment options and API interfaces
Mistral provides optimized termination points in transcription only for developers working on applications sensitive to latency. These allow simple integration in existing systems such as:
- Meeting and calling transcription tools
- Real -time translation systems
- Audio notes platforms
- Voice -based control panels
Given their open nature and their permissive license, VOXTRAL models can be deployed in secure site environments or in a cloud infrastructure, offering flexibility for business quality implementations.
Practical use in voice -centered systems
As spoken interfaces continue to develop on mobile applications, portable clothing, automotive interfaces and support systems, tools like VOXTRAL can allow more precise vocal treatment and context. Rather than requiring several floors systems, developers can now implement audio comprehension pipelines with fewer mobile parts.
Conclusion: a modular approach to audio language integration
VOxtral introduces an audio language modeling approach which combines the accuracy of transcription with the reasoning in terms of language and analysis of commands. Its multilingual coverage, its long context management and flexible license make it adapted to a variety of applications – from summary tools to interactive vocal agents.
Discover the Technical details,, VOXTRAL-SMALL-24B-2507 And VOXTRAL-MINI-3B-2507. All the merit of this research goes to researchers in this project.
| Reach the most influential AI developers in the world. 1M + monthly players, 500K + community manufacturers, endless possibilities. (Explore sponsorship)) |
Asif Razzaq is the CEO of Marktechpost Media Inc .. as a visionary entrepreneur and engineer, AIF undertakes to exploit the potential of artificial intelligence for social good. His most recent company is the launch of an artificial intelligence media platform, Marktechpost, which stands out from its in-depth coverage of automatic learning and in-depth learning news which are both technically solid and easily understandable by a large audience. The platform has more than 2 million monthly views, illustrating its popularity with the public.