
The models of large languages have motivated the progress of automatic translation, taking advantage of massive training corpus to translate dozens of languages and dialects while capturing subtle linguistic nuances. However, the fine adjustment of these models for the precision of the translation often alters their skills in monitoring instructions, and the large -use versions have difficulty respecting professional loyalty standards. Balance precise and culturally translations with the ability to manage code generation, problem solving and specific user formatting remains difficult. The models must also preserve terminological consistency and respect the formatting directives through a varied audience. Stakeholders require systems that can dynamically adapt to domain requirements and user preferences without sacrificing mastery. Reference scores such as WMT24 ++, covering 55 language variants, and prompts focused on the instructions of Ifeval 541 highlight the gap between the quality of specialized translation and general versatility, posing a neck of critical strangulation for the deployment of business.
Current approaches to adapt language models for the accuracy of translation
Several approaches have been explored to adapt language models for translation. The pre-formed large-language models with fine adjustment on parallel corpora were used to improve the adequacy and mastery of the translated text. Meanwhile, the continuation of pre-training on a combination of monolingual and parallel data improves multilingual mastery. Some research teams have completed training with learning to strengthen human comments to align results with quality preferences. Owner systems such as GPT-4O and Claude 3.7 have demonstrated the quality of the leading translation, and open adaptations, including Tower V2 and Gemma 2 models, have reached parity or exceeded closed source models under certain language scenarios. These strategies reflect continuous efforts to meet the two requirements for the accuracy of translation and wide language capacities.
Presentation of the tower +: unified training for translation and general language tasks
Researchers from UNFABEL, Instituto de Telecomunicações, Instituto Superior Técnico, Universidade de Lisboa (Lisbon Ellis Unit) and MICS, Centralizespelec, Université Paris-Saclay, introduced Tour +A series of models. The research team has designed variants with several parameter scales, 2 billion, 9 billion and 72 billion, to explore the compromise between the specialization of translation and general utility. By implementing a unified training pipeline, the researchers aimed to position the tower + of the models on the border of Pareto, reaching both high translation performance and robust general capacities without sacrificing it for each other. The approach exploits architectures to balance the specific requirements of automatic translation with flexibility required by conversational and educational tasks, by supporting a range of application scenarios.
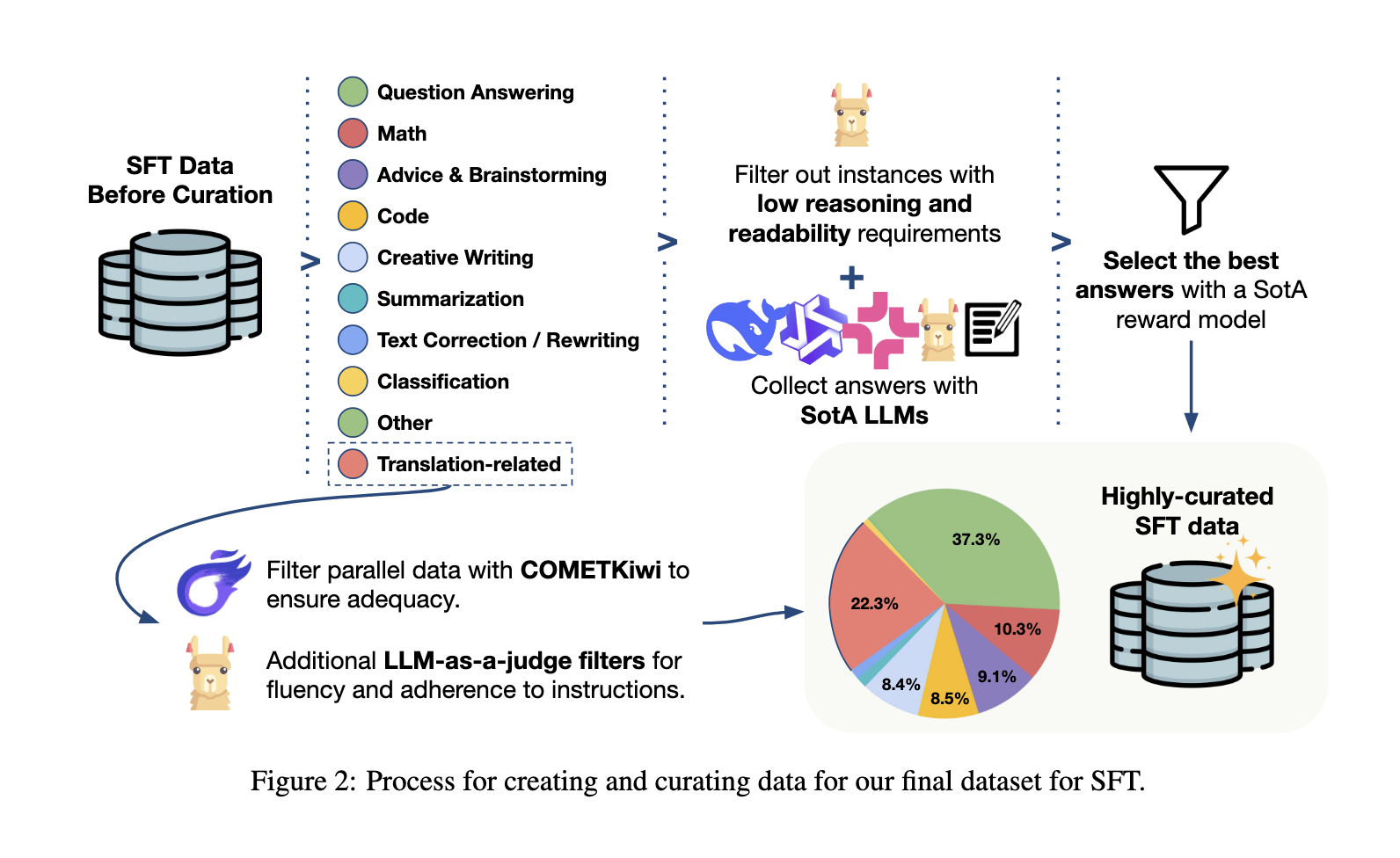
Tour + Training pipeline: pre-training, supervised, preferences and RL
The training pipeline begins with the continuation of pre-training on carefully organized data which include monolingual content, the filtered parallel sentences formatted in translation instructions and a small fraction of examples of the instruction type. Then, the supervised fine adjustment refines the model using a combination of translation tasks and various instructions monitoring scenarios, including code generation, mathematical problems solving and questions. A step in optimizing preferences follows, using the optimization of weighted preferences and updates to the relative policy of the group formed on out -of -policy signals and translation variants published by humans. Finally, learning to strengthen verifiable rewards reinforces precise compliance with transformation guidelines, using Regex -based controls and preferably annotations to refine the capacity of the model to follow the explicit instructions during the translation. This combination of pre-training, supervised alignment and reward updates gives a robust balance between the accuracy of specialized translation and versatile linguistic competence.
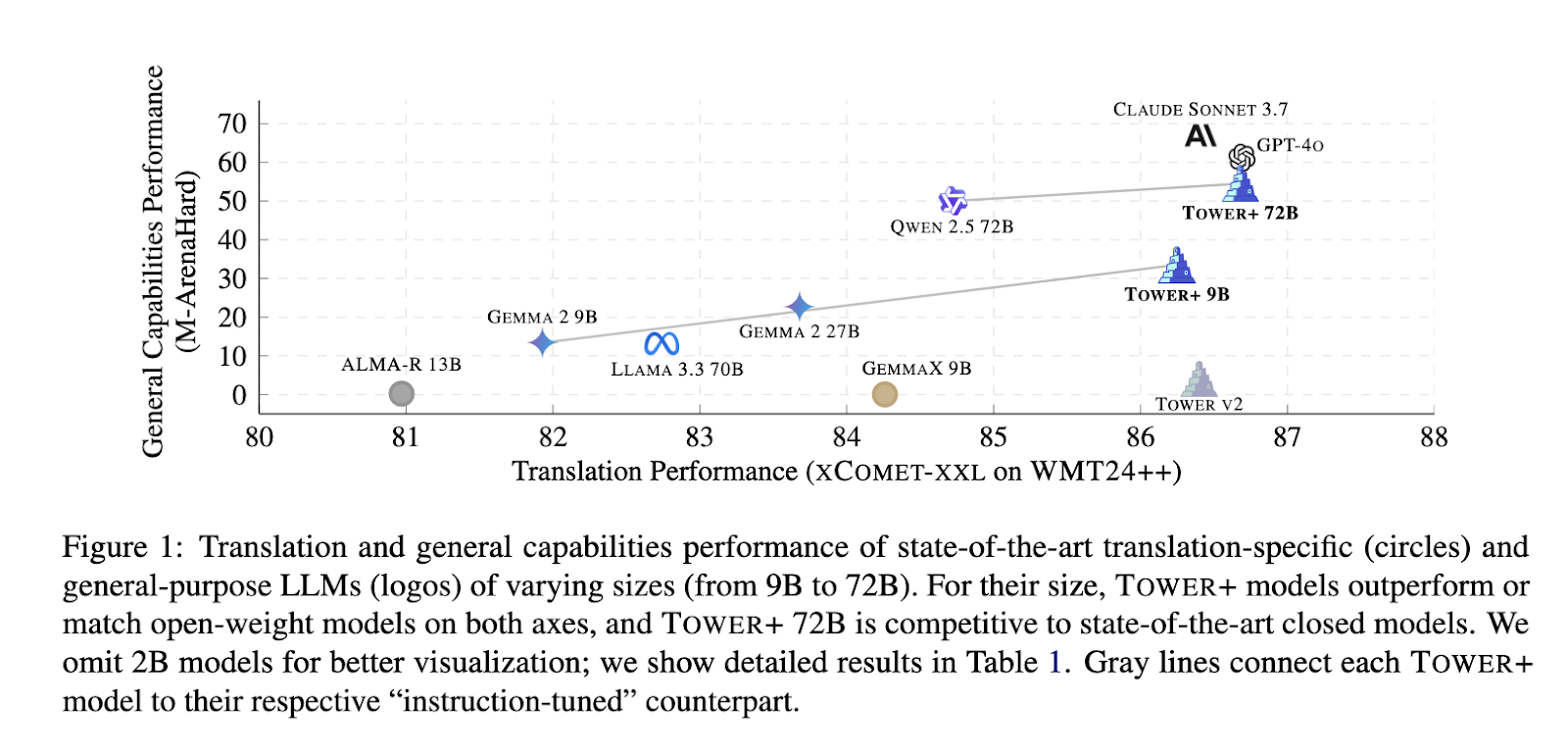
Reference results: Tower + reaches the following cutting -edge translation and instruction
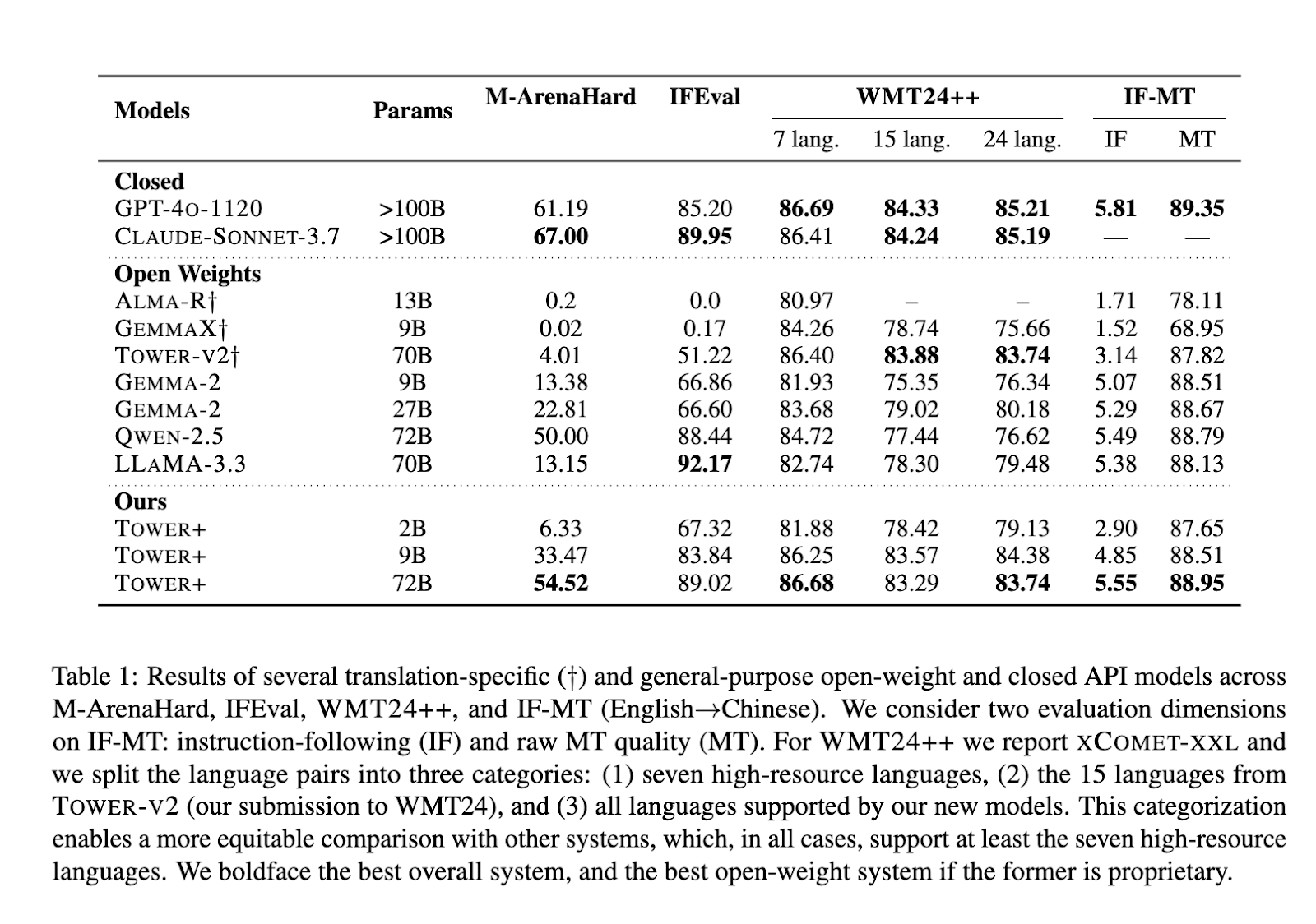
The Tower + 9B model has reached a 33.47% victory rate on general multilingual cat invites, while obtaining an XCOT-XXL score of 84.38 out of 24 language pairs, outperforming open-size counterparts. The flagship variant of 72 billion parameters obtained a 54.52% victory rate on M-Arenahard, recorded an IFEVAL instructions monitoring of 89.02 and has reached an XCOMET-XXL level of 83.29 on the full WMT24 ++ reference. On the combined translation and the reference according to the instructions, IF-MT obtained a score of 5.55 for the accession to instruction and 88.95 for translation loyalty, establishing advanced results among the open models. These results confirm that the integrative pipeline of researchers effectively fills the gap between specialized translation performance and wide language capacities, demonstrating its viability for business and research applications.
Technical Keys Key of Tower + models
- Tower + Models, developed by Unbabel and Academic, SPAN 2 B, 9 B and 72 B parameters to explore the performance border between the specialization of translation and general utility.
- The post-training pipeline includes four stages: continuous pre-training (66% monolingual, 33% parallel and 1% instructions), a supervised fine adjustment (22.3% translation), optimization of weighted preferences and learning in verifiable strengthening, to preserve cat skills while improving the accuracy of the translation.
- The continuation of pre-training covers 27 languages and dialects, as well as 47 language pairs, more than 32 billion tokens, merging specialized and general control points to maintain balance.
- Variant 9 B reached a victory rate of 33.47% on M-Arenahard, 83.84% on Ifeval and an 84.38% XCOT-XXL on 24 pairs, with IF-MT scores of 4.85 (instruction) and 88.51 (translation).
- The 72 B model recorded 54.52% of M-Arenahard, 89.02% IFEVAL, 83.29% XCOT-XXL and 5.55 / 88.95% IF-MT, setting a new open standard.
- Even the 2B model corresponded to larger base lines, with 6.33% on M-Arenahard and 87.65% of IF-MT translation quality.
- Benchmarked against GPT-4-1120, Claude-Sonnet-3.7, Alma-R, Gemma-2 and Llama-3.3, the Tower + Suite corresponds or constantly surpasses to specialized and general tasks.
- Research provides a reproducible recipe for the construction of LLM which simultaneously respond to translation and conversational needs, reducing the proliferation of models and operational general costs.
Conclusion: a pateto-optimal frame for future LLMs focused on the translation
In conclusion, by unifying large-scale pre-training with specialized alignment stages, Tower + demonstrates that the excellence of translation and conversational versatility can coexist in a single open suite. The models obtain a parto-optimal balance through translation loyalty, monitoring of instructions and general cat capacities, offering an evolutionary plan for LLM development specific to the domain.
Discover the Paper And Models. All the merit of this research goes to researchers in this project. Also, don't hesitate to follow us Twitter And don't forget to join our Subseubdredit 100k + ml and subscribe to Our newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc .. as a visionary entrepreneur and engineer, AIF undertakes to exploit the potential of artificial intelligence for social good. His most recent company is the launch of an artificial intelligence media platform, Marktechpost, which stands out from its in-depth coverage of automatic learning and in-depth learning news which are both technically solid and easily understandable by a large audience. The platform has more than 2 million monthly views, illustrating its popularity with the public.
