
The long -term reasoning challenge in AI models
Large models of reasoning are not only designed to understand language, but are also structured to think about processes in several stages that require prolonged attention and a contextual understanding. As AI expectations are developing, in particular in real world development environments and software, researchers have looked for architectures that can manage longer inputs and maintain deep and consistent reasoning chains without overwhelming calculation costs.
Calculation constraints with traditional transformers
The main difficulty in extending these reasoning capacities lies in the excessive calculation load which comes with longer production lengths. The traditional models based on the transformer use a softmax attention mechanism, which evolves quadratic with the size of the input. This limits their ability to manage long entry sequences or extensive thought chains effectively. This problem becomes even more urgent in the fields which require real -time interaction or applications sensitive to costs, where inference expenditure is significant.
Existing alternatives and their limits
The efforts to solve this problem have given a range of methods, including clear attention and linear attention variants. Some teams have experienced state space models and recurring networks and alternatives to traditional attention structures. However, these innovations have experienced limited adoption in the most competitive reasoning models due to architectural complexity or a lack of scalability in deployments of the real world. Even large-scale systems, such as Hunyuan-T1 from Tencent, which uses a new architecture of Mamba, remain at a closed source, thus restricting wider commitment and validation of research.
Introduction of Minimax-M1: an evolutionary open weight model
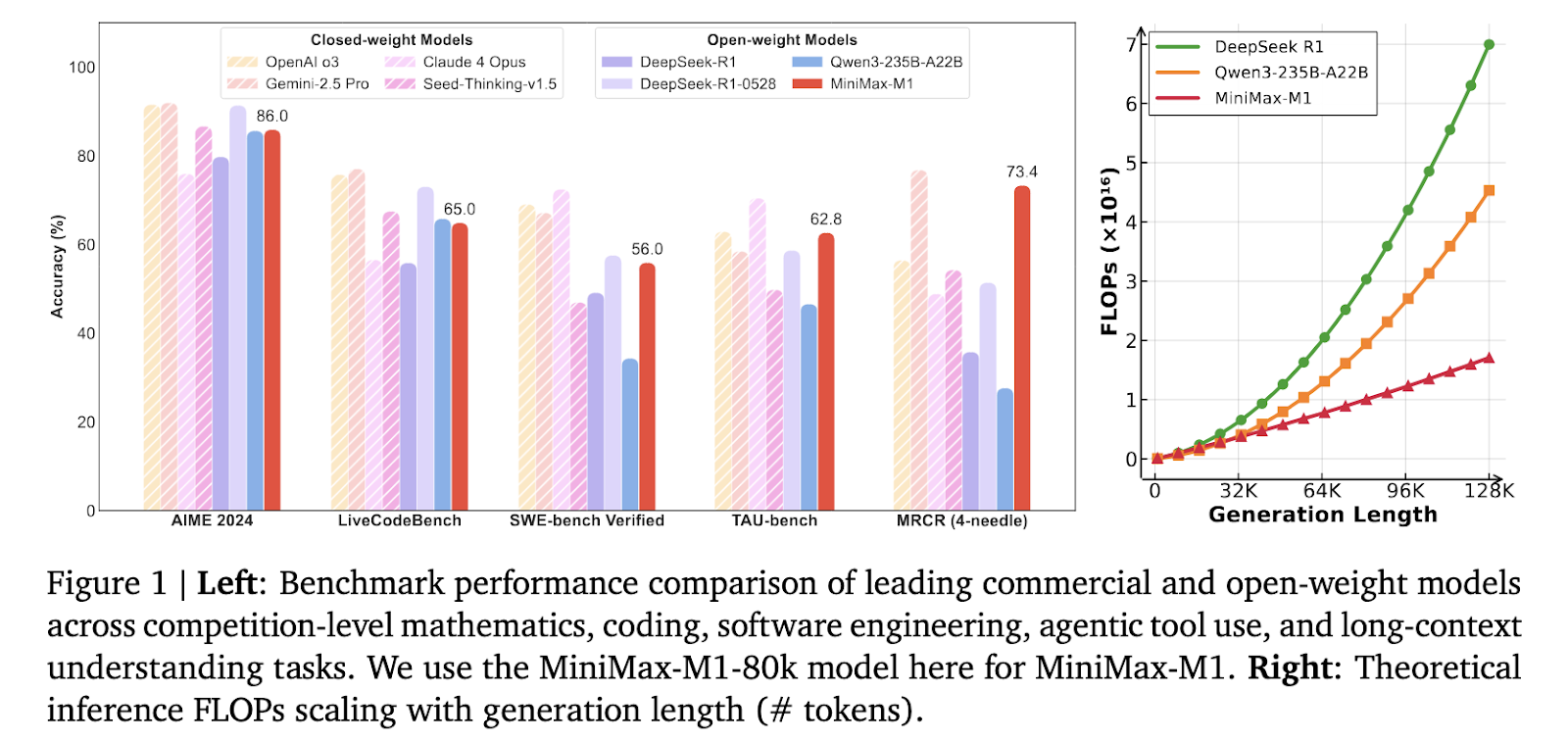
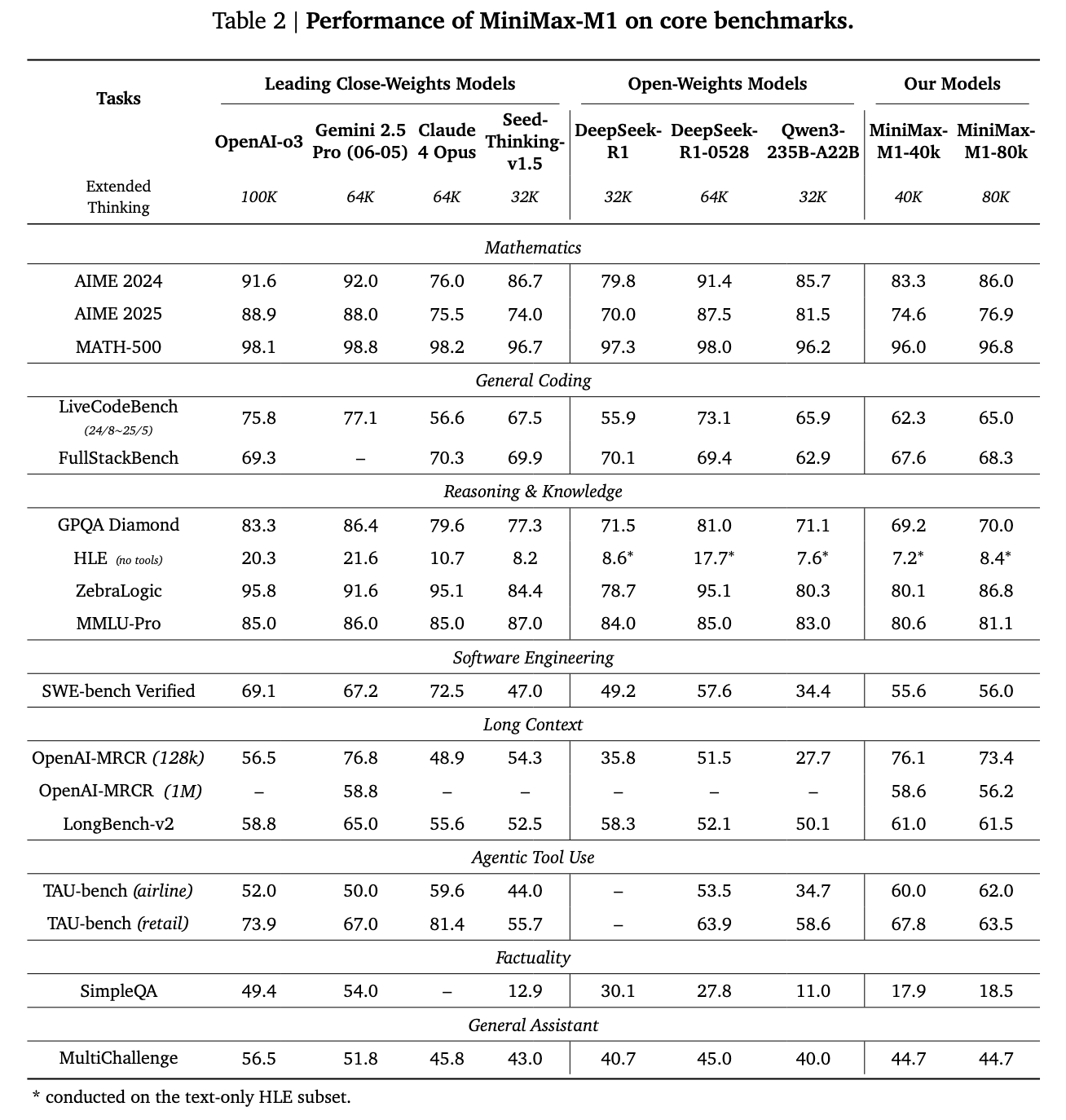
Minimax AI researchers have introduced Minimax-M1, a new large-scale model of reasoning on a large scale that combines a mixture of expert architecture with rapid attention. Built as an evolution of the minimum-text-01 model, Minimax-M1 contains 456 billion parameters, with 45.9 billion activated by token. It supports context durations up to 1 million tokens, eight times the capacity of Deepseek R1. This model deals with the scalability of calculation in inference time, consuming only 25% of the flops required by Deepseek R1 at 100,000 lengths of tokens production. It has been formed using large -scale strengthening learning on a wide range of tasks, mathematics and software engineering coding, marking an evolution towards practical and long -term models.
Hybrid-Attention with the attention of lightning and softmax blocks
To optimize this architecture, Minimax-M1 uses a hybrid attention diagram where each seventh transformer block uses the traditional SoftMax attention, followed by six blocks using the attention of lightning. This considerably reduces the complexity of calculation while preserving performance. The attention of lightning itself is devoted to I / O, suitable for linear attention, and is particularly effective in scale of reasoning lengths to hundreds of thousands of tokens. For the effectiveness of strengthening learning, researchers have introduced a new algorithm called Cispo. Instead of crushing the tokens updates as traditional methods do, Cispo clips imported sampling weights, allowing stable training and coherent tokens contributions, even in out -of -political updates.
Cispo algorithm and the effectiveness of RL training
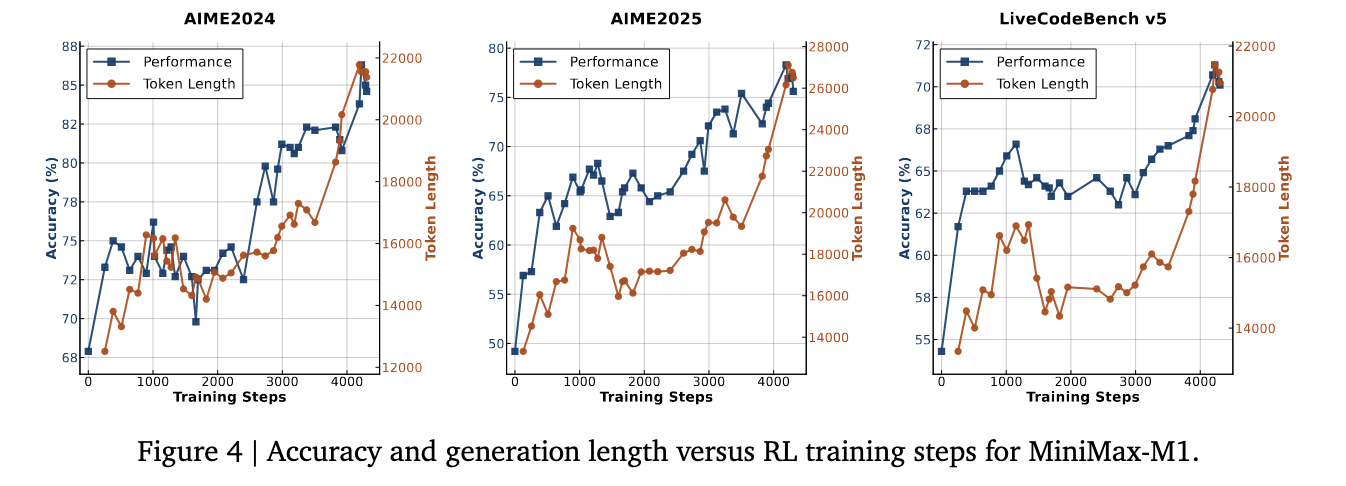
The Cispo algorithm has proven to be essential to overcome training instability faced with hybrid architectures. In comparative studies using the QWEN2.5-32B base line, Cispo has achieved 2x acceleration compared to DAPO. Pulling this, the learning cycle of the full minimax-M1 is completed in just three weeks using 512 H800 GPU, with a rental cost of approximately $ 534,700. The model was formed on a diversified data set comprising 41 logical tasks generated via the synlogical frame and real software engineering environments derived from the SWE bench. These environments have used execution -based awards to guide performance, resulting in stronger results in practical coding tasks.
Reference results and comparative performance
Minimax-M1 provided convincing reference results. Compared to Deepseek-R1 and QWEN3-235B, he excelled in software engineering, in long context processing and using the agentic tool. Although he followed the latest Deepseek-R1-0528 competitions in mathematics and coding competitions, he exceeded Openai O3 and Claude 4 opus in the references to understand the long-term context. In addition, he outperformed Gemini 2.5 Pro in the evaluation of the use of the Tau-Bench agent tool.
Conclusion: an evolutionary and transparent model for long context AI
Minimax-M1 presents a significant step forward by offering both transparency and scalability. By approaching the double challenge for the efficiency of inference and training complexity, the minimax AI research team established a previous one for open weight reasoning models. This work not only brings a solution to calculate constraints, but also introduces practical methods for the scale of intelligence of the language model in the applications of the real world.
Discover the Paper,, Model And GitHub page. All the merit of this research goes to researchers in this project. Also, don't hesitate to follow us Twitter And don't forget to join our Subseubdredit 100k + ml and subscribe to Our newsletter.
Nikhil is an intern consultant at Marktechpost. It pursues a double degree integrated into materials at the Indian Kharagpur Institute of Technology. Nikhil is an IA / ML enthusiast who is still looking for applications in fields like biomaterials and biomedical sciences. With a strong experience in material science, he explores new progress and creates opportunities to contribute.
