The models of large languages (LLM) are faced with important challenges when they are trained as autonomous agents in interactive environments. Unlike static tasks, agent parameters require sequential decision -making, maintenance of cross -turn memory and adaptation to stochastic environmental feedback. These capacities are essential for developing effective planning assistants, robotic applications and tutoring agents that can improve through experience. While strengthening learning (RL) has been applied to LLM using rules based on rules, the training of self-evolutive agents that can reason and adapt remains under-explored. Current approaches suffer from the instability of the training, the interpretation of the complex reward signal and limited generalization through variable prompts or changing environments, in particular during multi-tour interactions with unpredictable feedback. The fundamental question emerges: What design elements are crucial to creating LLM agents who learn effectively and maintain stability throughout their evolution?
Thanks to various methodologies, RL has considerably advanced LLMS reasoning capacities. PPO maintains the stability of the training by pre -updates to policies, while GRPO improves systematic problem solving capacities. The bag uses regular objectives to entropy for robust exploration, and meta tokens facilitate structured thought. The approaches based on PRM and MCTS have further improved systematic reasoning. Simultaneously, the techniques of the chain of thoughts like the star use small examples of justification alongside larger data sets. At the same time, DAPO, Dr. GRPO and Open Reason Zero demonstrate that minimalist RL techniques with a decoupled cut and simple reward patterns can considerably improve the performance of reasoning.
The LLM agent architectures have gone from basic reasoning frames to structured planning approaches and complex multi-agent systems. Test environments range from specialized platforms like Sokoban and Frozenlake to general frames like HuggingGpt, allowing web navigation applications to coding assistance and embodied tasks. Despite these advances, the challenges persist in architectural complexity and self-correction, in particular for various reasoning tasks in several stages where the maintenance of consistency between interactions remains problematic.
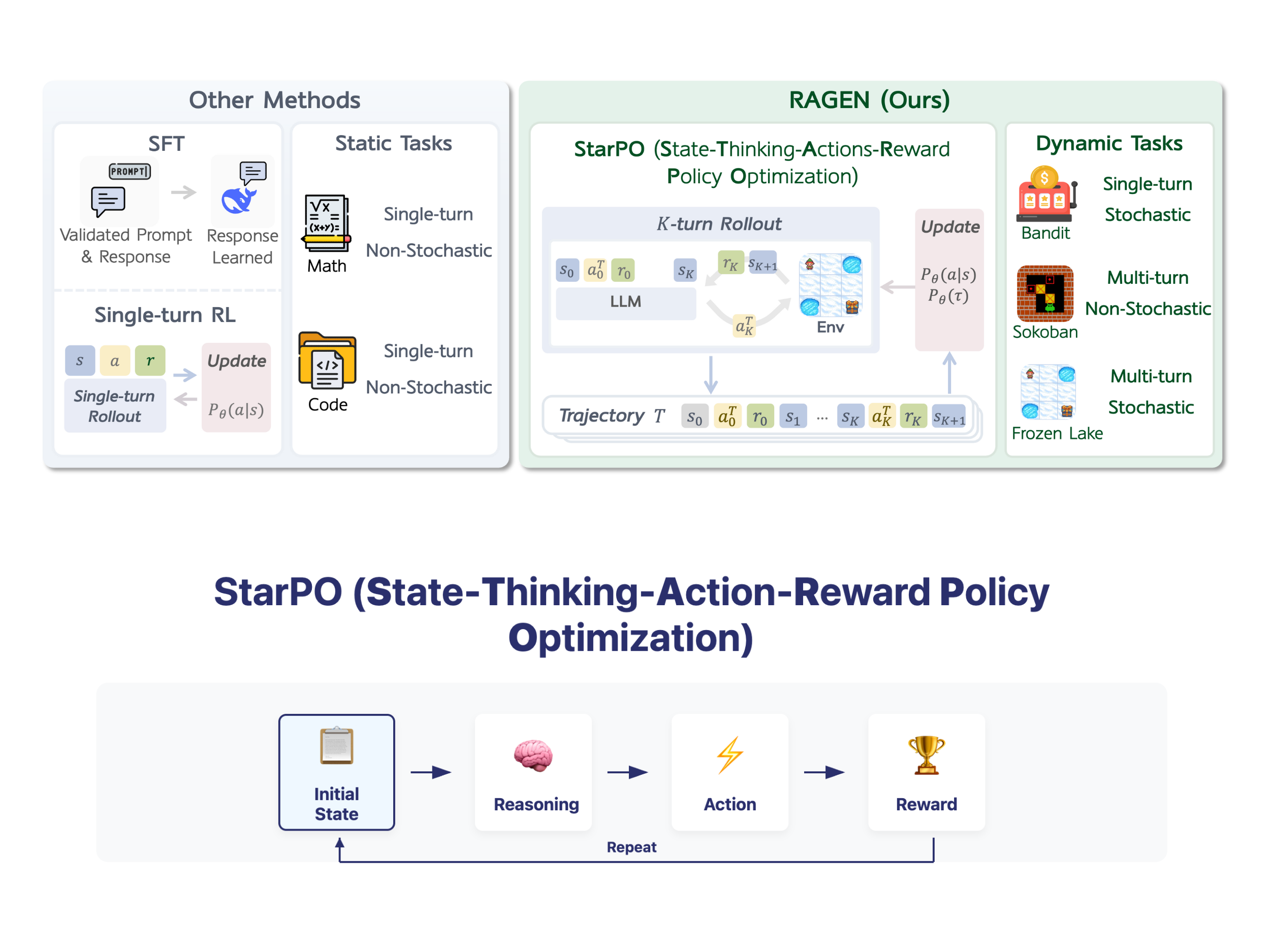
The researchers addressed the learning of agents via StarPO (optimization of action-re-entry policies of the reward state)A unified framework for the training of agent in terms of trajectory with flexible control over reasoning processes, reward mechanisms and rapid structures. Relying on this framework, they have developed RageA modular system implementing complete training loops to analyze the dynamics of LLM agents in multi-viing stochastic environments. To isolate the learning factors from confusion variables such as pre-stretched knowledge, the evaluation focuses on three controlled play environments: bandit (fire tower, stochastic), Sokoban (multi-tours, deterministic) and frozen lake (multi-tours, stochastic). These minimalist environments require the learning of interaction policies rather than relying on pre -existing knowledge. The analysis reveals three critical dimensions of agent learning: the stability problems of the gradient in the learning of multi-tours strengthening, the importance of the frequency and the diversity of deployment in the evolution of agents and the need for reward signals carefully designed to develop real reasoning capacities rather than a selection of superficial action or hallucinated reflection processes.

Starpo represents a unique frame designed specifically to optimize multi-tours interaction trajectories in LLM agents. Unlike traditional approaches that deal with each action independently, Starpo optimizes whole trajectories – including observations, traces of reasoning, actions and comments – as coherent units. This approach to the trajectory is particularly suitable for interactive environments where agents must maintain memory through turns and adapt to stochastic feedback. The objective function of StarPO focuses on the maximization of the rewards expected on the complete trajectories rather than on the individual stages, which makes it directly compatible with the LLM self -regressive by decomposition in likelihood at the level of the token. The framework incorporates structured outings guided by reasoning which combines both intermediate thought processes and executable actions, allowing agents to develop more sophisticated decision -making capacities while maintaining the stability of learning in complex environments.


The experimental results reveal that Starpo-S considerably surpasses the Vanilla Starpo on several agent tasks. By implementing the filtering of instances based on uncertainty, elimination of KL terms and asymmetrical clipping, StarPo-S effectively delays the collapse of performance and improves the final results of the task. The stabilized approach demonstrates a particular efficiency in complex environments such as Frozenlake and Sokoban, where only 25 to 50% of deployments with wide variance considerably improves the stability of training while reducing the calculation requirements up to 50%.
The diversity of tasks and interaction granularity have a significant impact on performance. The models formed with a higher diversity of tasks and 4 to 6 actions per turn demonstrate higher generalization capacities through new vocabularies and larger environments. In addition, frequent deployment updates are essential to maintain alignment between optimization targets and political behavior. Agents formed with update deployments All updates 1 to 10 reach faster convergence and higher success rates compared to those based on obsolete trajectory data.
The advantages of symbolic reasoning vary mainly between the tasks in turn and in turn. Although the traces of reasoning considerably improve generalization in bandit environments in a fire tour, they provide a limited advantage in complex multi-viage parameters like Sokoban and Frozenlake. The analysis shows that the length of the reasoning decreases in a coherent way during the training, suggesting that the models gradually suppress their reflection processes when the awards are rare and delayed. This highlights the need for reward mechanisms which directly reinforce the intermediate reasoning stages rather than relying solely on the results based on results.







This research establishes the learning of strengthening as a viable approach for the training of language agents in complex and stochastic environments. StarPo-S represents an important progression in stabilization of the training of multiple agents thanks to sampling based on uncertainty and encouragement of exploration. Going from human supervision to verifiable rewards based on results, this framework creates opportunities to develop more competent AI systems through the prouvance of theorem, software engineering and scientific discovery. Future work should focus on multimodal inputs, improved training efficiency and applications in increasingly complex areas with verifiable objectives.
Discover the Paper And GitHub page. Also, don't forget to follow us Twitter And join our Telegram And Linkedin Group. Don't forget to join our 90K + ML Subdreddit.
Asjad is an internal trainee at Marktechpost. He persuades B.Tech in mechanical engineering at the Indian Kharagpur Institute of Technology. ASJAD is an automatic learning and in -depth learning enthusiast who is still looking for applications for automatic learning in health care.
