The LLMs produced impressive gains in complex reasoning, mainly by innovations in architectural, scale and training approaches like RL. RL improves LLM using reward signals to guide the model to more effective reasoning strategies, resulting in longer and more coherent thinking processes that dynamically adapt to the complexity of a task. Despite this, most LLM improved by RL greatly depend on static internal knowledge and texture in text only, which makes them poorly adapted to tasks requiring real -time information, specific expertise in the domain or specific calculations. This limitation is particularly obvious in problems with high intensity of knowledge or open where the inability to access and interact with external tools leads to inaccuracies or hallucinations.
To overcome these constraints, recent work has explored aging reasoning, where LLMs are dynamically engaged with external tools and environments during the reasoning process. These tools include web, API and code research platforms, while environments range from browsers simulated to operating systems. Agency reasoning allows models to plan, adapt and solve tasks interactively, beyond static inference. However, the current methods of integration of tools often depend on prompts designed manually or a supervised fine adjustment, which hinder scalability and generalization. Emerging techniques for learning strengthening as well as the relative optimization of group policies (GRPO) offer more efficient and adaptive training for the use of tools without overwhelming level. However, the intersection of RL, the use of tools and agent decision-making remains under-explored, in particular in real world tasks which require multi-live reasoning, dynamic planning and robust external interaction.
Microsoft Research presents the artist (agental reasoning and integration of tools in self-improvement transformers), a framework that combines agentic reasoning, learning to strengthen and use dynamic tools to improve LLM. The artist allows models to decide independently when, how and what tools to use during reasoning in several steps, learning robust strategies without supervisory. The model improves reasoning and interaction with external environments thanks to integrated requests and outings. Assessed on difficult references and calling on function functions, the artist surpasses the best models like GPT-4O, reaching up to 22% of earnings. It demonstrates emerging agent behaviors, establishing a new standard in resolution of generalizable and interpretable problems.
The artist is a flexible framework that allows LLM to interact with external tools and environments using strengthening learning. It alternates between reasoning and the use of tools, allowing the model to choose when and how to invoke tools such as code interpreters or APIs. The training uses GRPO, who avoids value functions and uses group -based group rewards. Structures of artists deploy reasoning, tool queries, tools outings and final responses, with a composite reward system encouraging the accuracy, appropriate format and successful use of tools, allowing an adaptive problem solving and in several stages.
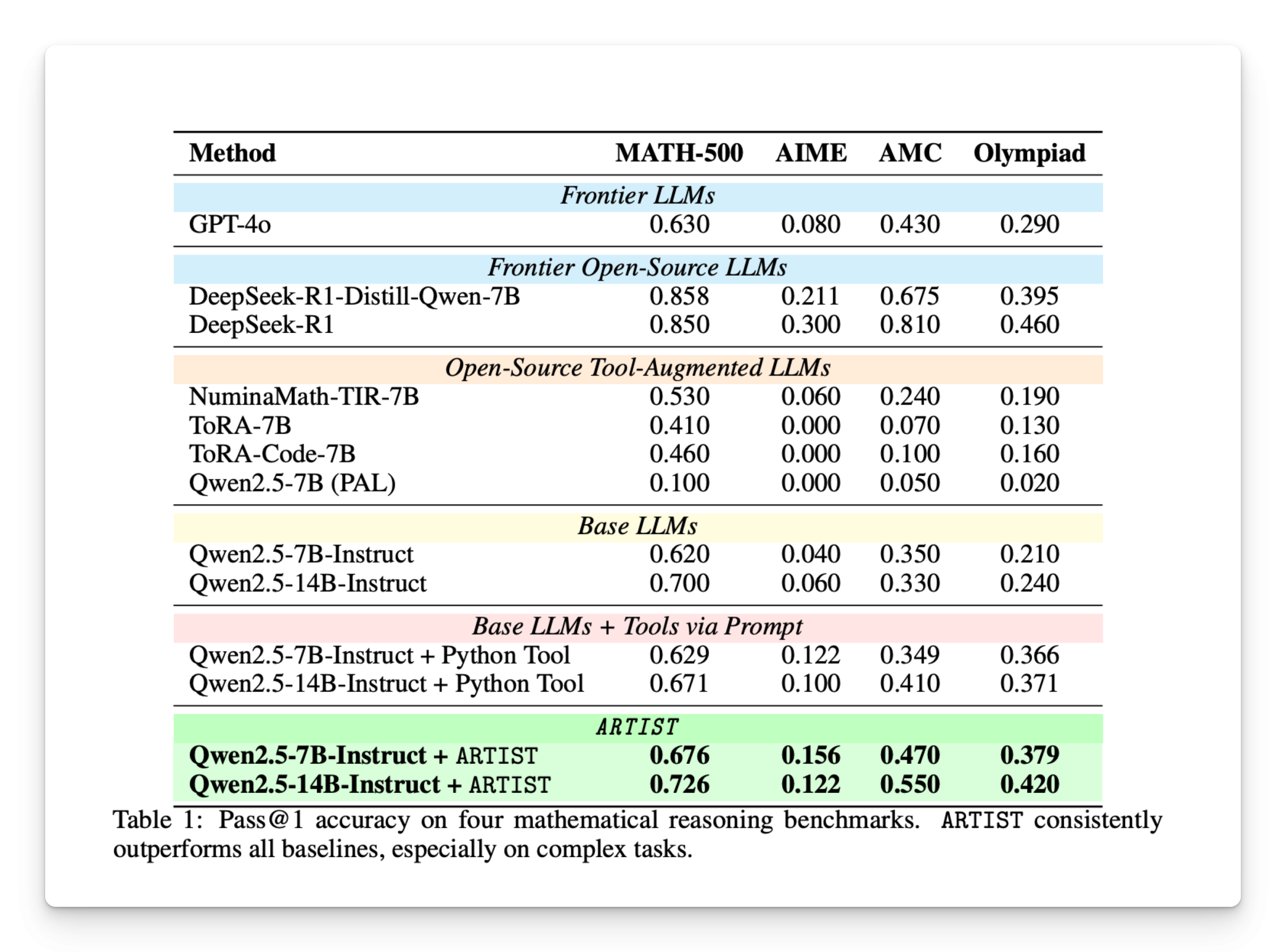
The artist surpasses various basic lines, including GPT-4O and LLMS with tools, on complex mathematical references such as AMC, loves him and Olympiad. It achieves higher precision \ @ 1, with notable gains up to 22% compared to basic models and more than 35% compared to other methods integrated into the tool. The artist's advantage comes from his learning in agental strengthening, allowing him to strategically use external tools and refine solutions in several steps. In relation to the use of the tool based on an prompt, it shows a higher invocation of the tool, a quality of response and a reasoning depth. Although its advantages are the most obvious in complex tasks, the artist considerably improves simpler data sets like Math-500 thanks to the selective use of tools.

In conclusion, the artist is a framework that combines aging reasoning, learning to strengthen and use dynamic tools to improve LLM capabilities. Unlike traditional approaches based on prompts, the artist allows models to plan, adapt and resolve complex tasks independently by interacting with external tools and environments. He learns strategies for using effective tools without supervision step by step, improving deeper accuracy and reasoning. The assessments on mathematical references and calling on the functions show significant performance gains. The artist also produces more interpretable paths of reasoning and robust behavior. This work highlights the potential of agentic RL as a promising direction to create more adaptive and capable AI systems.
Discover the Paper. Also, don't forget to follow us Twitter.
Here is a brief overview of what we build on Marktechpost:
Sana Hassan, consulting trainee at Marktechpost and double -degree student at Iit Madras, is passionate about the application of technology and AI to meet the challenges of the real world. With a great interest in solving practical problems, it brings a new perspective to the intersection of AI and real life solutions.