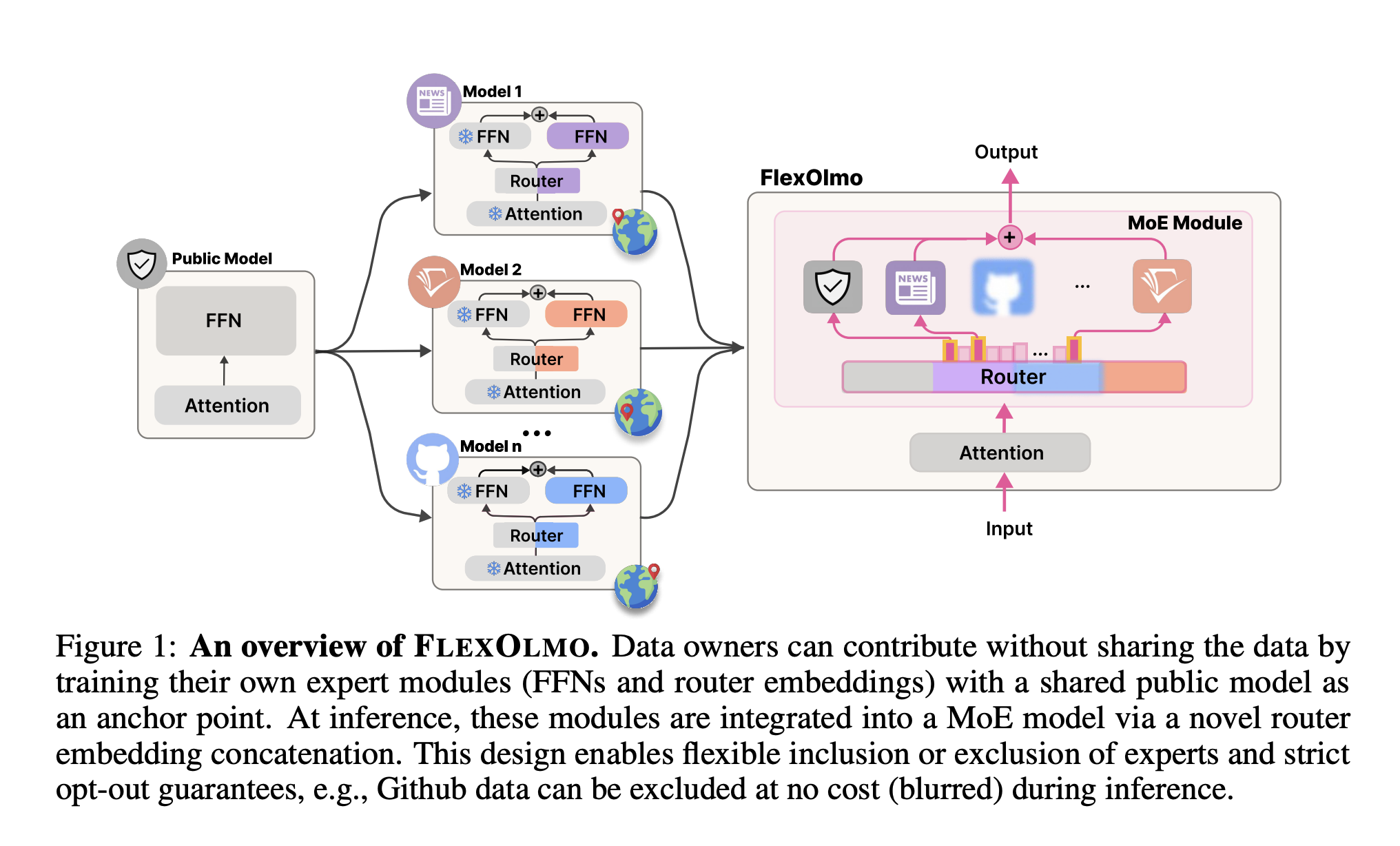
The development of large -scale language models (LLMS) has historically required centralized access to in -depth data sets, many of which are sensitive, protected by copyright or governed by use restrictions. This constraint severely limits the participation of organizations rich in data operating in regulated or owner environments. Flexolmo – introduced by researchers from the Allen Institute for AI and employees – offers a training and modular inference framework which allows the development of the LLM in data governance constraints.
Llms current… ..
Current LLM training pipelines are based on the aggregation of all training data in a single corpus, which requires a static inclusion decision and eliminates the possibility of abandonment after training. This approach is incompatible with:
- Regulatory regimes (for example, HIPAA, GDPR, data sovereignty laws),
- Data sets related to the license (for example, non -commercial or restricted to allocation),
- Data sensitive to the context (for example, internal source code, clinical files).
Flexolmo deals with two objectives:
- Decentralized and modular training: Authorize the modules formed independently on disjoint and local data sets.
- Flexibility of inference time: Activate the opt-in / opt-out deterministic mechanisms for contributions from the data set without recycling.

Model Architecture: Expert modularity via the mixture of experts (MOE)
Flexolmo relies on an expert architecture of experts (MOE) where each expert corresponds to a restoration network module (FFN) formed independently. A fixed public model (indicated as mpub) serves as a shared anchor. Each data owner forms an expert MI Use of their private data setIWhile all layers of attention and other non -expert parameters remain frozen.
Key architectural components:
- Sparse activation: Only a subset of expert modules is activated by entrance token.
- Expert routing: The assignment of token to the expert is governed by a router matrix derived from the interest informed of the field, eliminating the need for joint training.
- Regularization of the bias: A term of negative bias is introduced to calibrate the selection of independently trained experts, preventing the over-selection of any unique expert.
This design maintains interoperability between modules while allowing selective inclusion during inference.

Asynchronous and isolated optimization
Each expert mI is formed via a constrained procedure to ensure alignment with Mpub. Specifically:
- The training is carried out on a hybrid MOE instance including MI and mpub.
- Thempub Expert and shared diapers of attention are frozen.
- Only the FFN corresponding to MI and the Router Information RI are updated.
To initialize RIa set of samples of DI is integrated using a pre-trained encoder, and their medium forms the incorporating router. The optional light router adjustment can further improve performance using Public Corpus Proxy data.
Construction of the data set: FlexMix
The training corpus, flexmix, is divided into:
- A public mixingComposed of web data for general use.
- Seven closed sets Simulating non -sharable domains: news, reddit, code, academic text, educational text, creative and mathematical writing.
Each expert is trained on a disjointed subset, without access to joint data. This configuration is close to real use where organizations cannot pool data due to legal, ethical or operational constraints.

Reference assessment and comparisons
Flexolmo was evaluated on 31 reference tasks in 10 categories, in particular the general understanding of language (for example, MMLU, Agieval), QA generative (for example, Gen5), generation of code (for example, code4) and mathematical reasoning (for example MATH2).
Reference methods include:
- Model soup: To make an average of the weights of individuals refined individually.
- Branch-Train-Merge (BTM): Weighted set of exit probabilities.
- Btx: Convert dense models trained independently into a MOE via a parameter transplant.
- Quick road: Use classifiers set by instruction to transport requests to experts.
Compared to these methods, Flexolmo reaches:
- A 41% average relative improvement On the basic public model.
- A Improvement of 10.1% On the strongest fusion base line (BTM).
The gains are particularly notable on tasks aligned in closed areas, confirming the usefulness of specialized experts.
Architectural analysis
Several controlled experiences reveal the contribution of architectural decisions:
- The abolition of the coordination of the expert-public during the training considerably degrades performance.
- Incorporations of random initialized routers reduce the separability between expressions.
- Deactivation of the term bias on the selection of experts, in particular when the merger of more than two experts.
The routing models at the tokens show an expert specialization on specific layers. For example, the mathematical entry activates the expert in mathematics to deeper layers, while the introductory tokens are based on the public model. This behavior underlines the expressiveness of the model in relation to routing strategies of unique experts.
Opt-out and data governance
A key feathery of flexolmo is Deterministic disabiation capacity. The deletion of an expert from the router matrix fully removes his influence at the time of inference. Experiences show that the abolition of the expert in news reduces performance on Newsg but leaves other non -affected tasks, confirming the localized influence of each expert.
Confidentiality considerations
The risks of extraction of training data have been evaluated using known attack methods. The results indicate:
- 0.1% extraction rate for a public model only.
- 1.6% for a dense model formed on the mathematical data set.
- 0.7% for Flexolmo with the expert in mathematics included.
Although these rates are low, differential privacy training (DP) can be applied independently to each expert for stronger guarantees. Architecture does not prevent the use of DP or encrypted training methods.
Scalability
The Flexolmo methodology has been applied to an existing basic line (OLMO-2 7B), pre-trained on 4T. The integration of two additional experts (mathematics, code) improved average reference performance from 49.8 to 52.8, without recycling the basic model. This demonstrates scalability and compatibility with existing training pipelines.
Conclusion
Flexolmo introduces a framework of principle for the construction of modular LLM under data governance constraints. Its design supports the distributed training on locally maintained data sets and allows the inclusion / exclusion of the inference time of the influence of the data set. The empirical results confirm its competitiveness against the monolithic base lines and based on sets.
Architecture is particularly applicable to environments with:
- Data locality requirements,
- Dynamic data use policies,
- Regulatory compliance constraints.
Flexolmo provides a viable path to build powerful language models while joining the limits of access to real data.
Discover the Paper,, Model on the embraced face And Codes. All the merit of this research goes to researchers in this project.
Sponsorship opportunity: Reach the most influential AI developers in the United States and Europe. 1M + monthly players, 500K + community manufacturers, endless possibilities. (Explore sponsorship)
Asif Razzaq is the CEO of Marktechpost Media Inc .. as a visionary entrepreneur and engineer, AIF undertakes to exploit the potential of artificial intelligence for social good. His most recent company is the launch of an artificial intelligence media platform, Marktechpost, which stands out from its in-depth coverage of automatic learning and in-depth learning news which are both technically solid and easily understandable by a large audience. The platform has more than 2 million monthly views, illustrating its popularity with the public.