
Large multimodal models (LMM) allow systems to interpret images, answer visual questions and recover factual information by combining several methods. Their development has considerably advanced the capacities of virtual assistants and AI systems used in the parameters of the real world. However, even with massive training data, LMMS often neglect dynamic or evolving information, in particular facts that emerge after training or exist behind owner or secure borders.
One of the main limits of current LMMs is their inability to manage requests that require real -time or rare information. Faced with invisible visual entries or newly emerging facts, these models often hallucinate responses instead of admitting knowledge limits or the search for external assistance. This problem becomes essential in use cases which require precision, such as answering questions on current events or specific details in the field. These gaps not only compromise the reliability of LMMs, but also make them unsuitable for tasks that require factual verification or updated knowledge.

Various tools have tried to solve this problem by allowing models to connect with external sources of knowledge. Generation with recovery (CLOTH) Rests the information from the static databases before generating answers, while research agents based on prompts interact with online sources via scripted reasoning stages. However, RAG often recovers too much data and assumes that all the required information is already available. Guest agents, although capable of looking for, cannot learn optimal research behavior over time. These limitations prevent one or the other method from adapting fully to the unpredictability of the real world or from supporting effective interactions in practice.
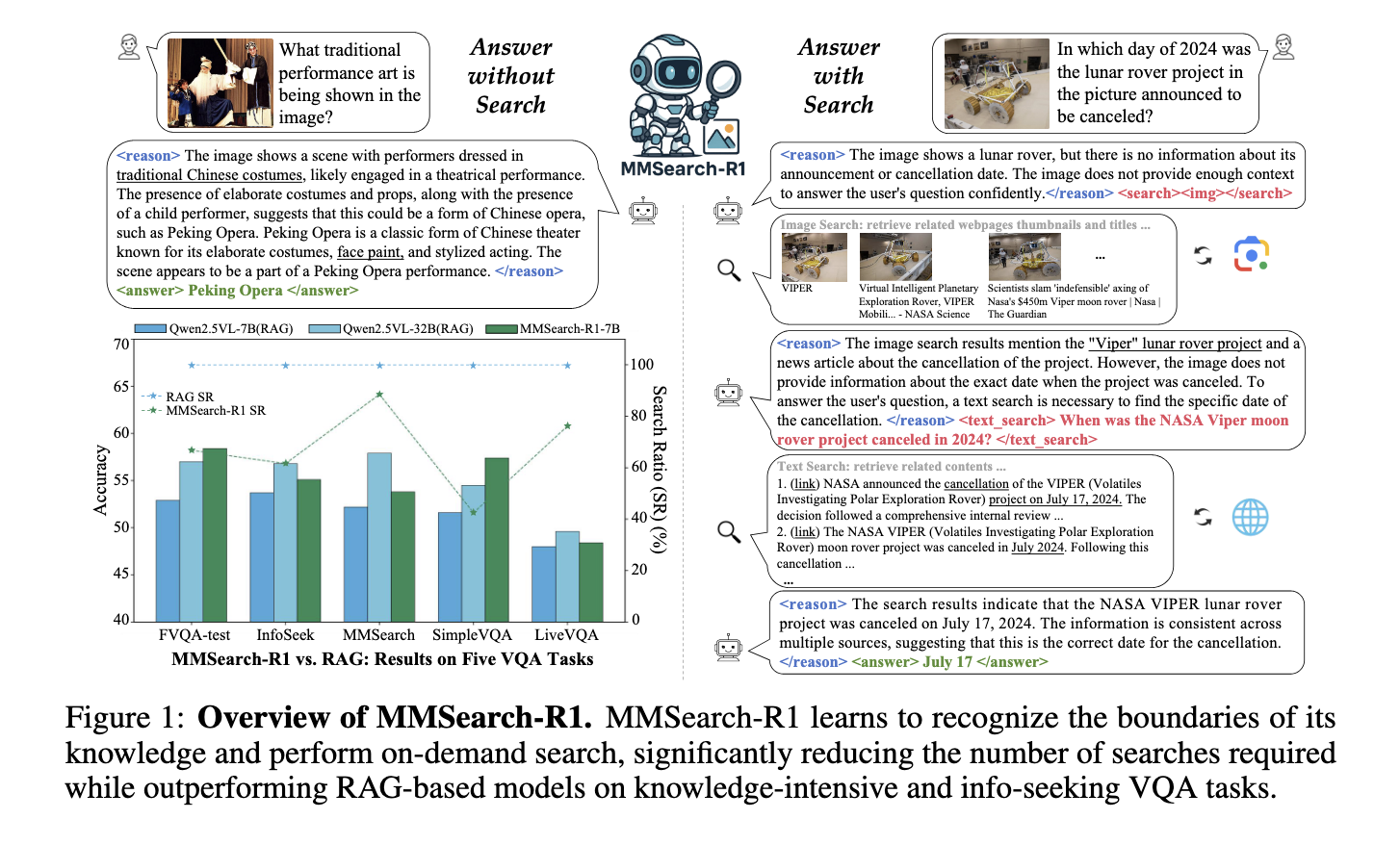
Researchers from Bytedance and S-LAB in Nanyang Technological University have developed MMSEarch-R1, a new frame designed to improve LMM performance through strengthening learning. Research has introduced a method where models are not only capable of looking for, but are also trained to decide when looking for, what to look for and how to effectively interpret research results. MMSECHERS-R1 is the first end-to-end strengthening learning framework that allows LMMs to carry out multi-tours research on demand in real world Internet environments. The system includes tools for image and text research, each tool invoked according to the judgment of the model rather than a fixed pipeline.
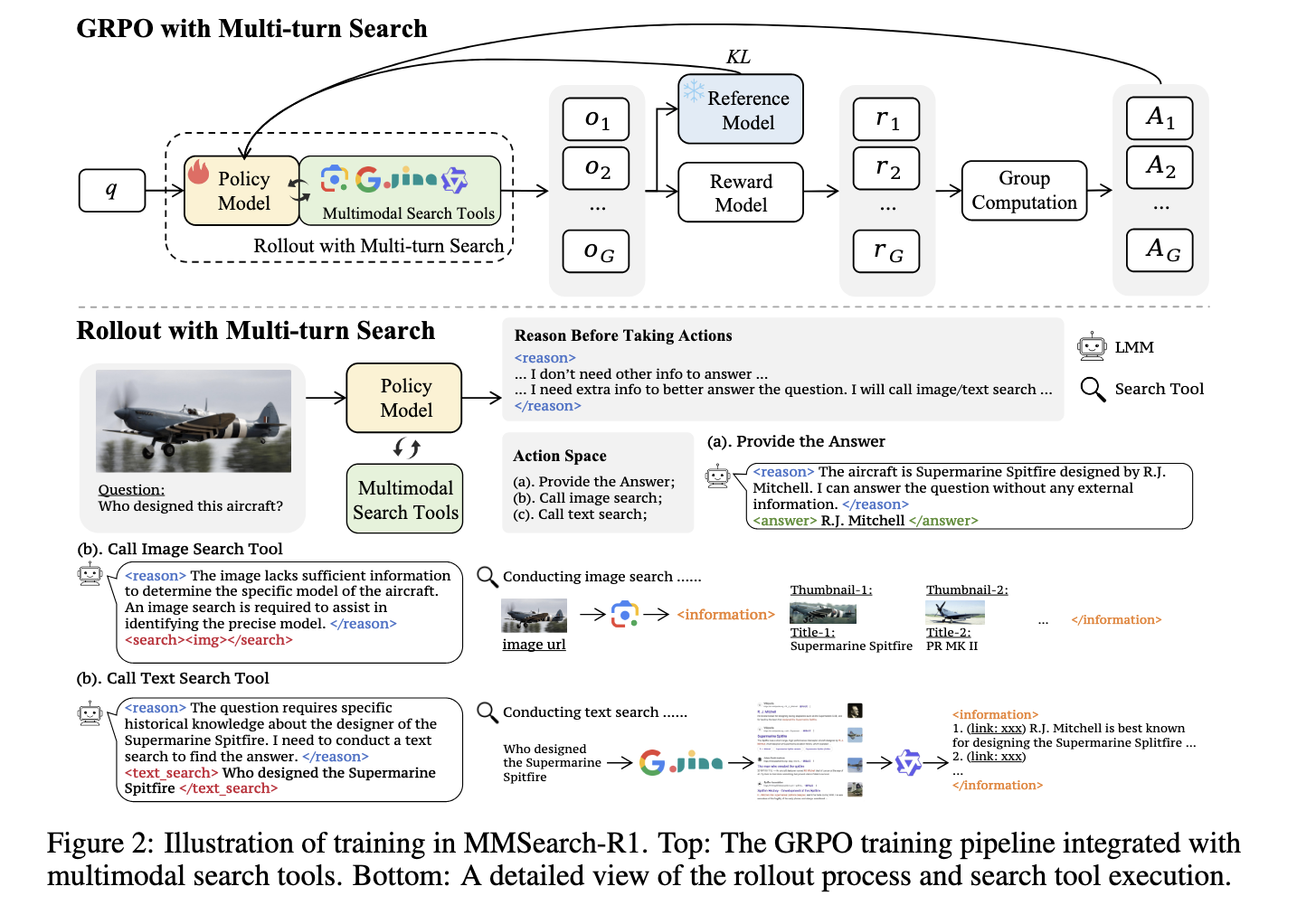
At the heart of this system is the optimization of the relative group policy (GRPO), a variant of the PPO algorithm. MMSEarch-R1 works by applying a reward system that promotes precise responses and discourages unnecessary research. The model performs several interaction cycles, evaluating if more information is necessary and, if necessary, the choice between text or image search. For example, he uses Serpapi to return the first five images or corresponding web pages and uses Jina Reader and QWEN3-32B to recover and summarize the relevant web content. The model is formed to envelop the reasoning in predefined formats, helping to structure the responses, to search for actions and to recover the content between the interaction towers.
In the tests, MMSECHERS-R1-7B has outperformed other basic lines from the same recovery size of the same size and corresponded almost to the performance of a larger 32B model based on rags. More importantly, this has done this while reducing the number of research calls by more than 30%. This shows that the model provides not only specific responses, but does it more effectively. The executive performance was evaluated on various tasks with a high intensity of knowledge, and the research behavior he learned has demonstrated both efficiency and reliability. The researchers also built and shared a full set of data, invoiced (FVQA), which included samples required and without research. This balanced data set was crucial to guide the model to be distinguished when external data was necessary.
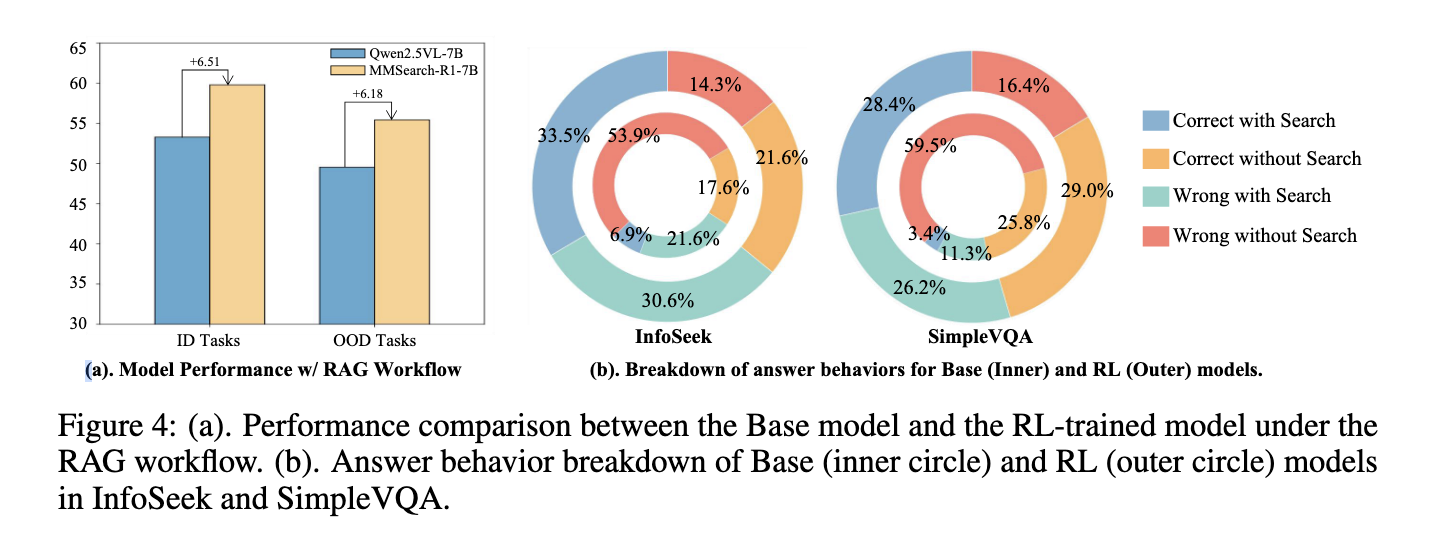
Overall, research addresses a practical weakness of the current LMMs by forming them to be selective and deliberate in their use of external research. Instead of passively recovering information, MMSEarch-R1 encourages models to act with intention, improving both the quality and efficiency of the responses. The solution marks a change in the way AI systems are designed to interact with the world by learning to know what they do not know and respond accordingly.
Discover the Paper And GitHub page. All the merit of this research goes to researchers in this project. If you plan a product launch / release, fundraising or simply aim for the development of the developer –Let us help you achieve this goal effectively.
Nikhil is an intern consultant at Marktechpost. It pursues a double degree integrated into materials at the Indian Kharagpur Institute of Technology. Nikhil is an IA / ML enthusiast who is still looking for applications in fields like biomaterials and biomedical sciences. With a strong experience in material science, he explores new progress and creates opportunities to contribute.