The generation of self -regressive videos is a rapidly evolving research area. It focuses on the synthesis of frame videos by frame using models learned both space arrangements and temporal dynamics. Unlike traditional video creation methods, which can rely on predefined frames or hand -made transitions, self -regressive models aim to generate content dynamically depending on the front tokens. This approach is similar to how large language models predict the following word. It offers potential to unify the generation of videos, image and text under a shared frame using the structural power of architectures based on transformers.
A major problem in this space is how to capture and precisely model the intrinsic spatio-temporal dependencies in the videos. Videos contain rich structures through time and space. Encode this complexity so that the models can predict coherent future frames remains a challenge. When these dependencies are not well modeled, this leads to a continuity of the broken frame or to a generation of unrealistic content. Traditional training techniques and random masking also have trouble. They often fail to provide balanced learning signals between executives. When the spatial information of the adjacent Fuite frames, the prediction becomes too easy.
Several methods try to take up this challenge by adapting the self -regressive generation pipeline. However, they often deviate from the standard Great language model structures. Some use external pre-formed text encoders, making the models more complex and less consistent. Others provide significant latency during generation with ineffective decoding. Self -regressive models like Phenaki and EMU3 try to take care of the end -to -end generation. Despite this, they still have trouble with the consistency of performance and high training costs. Techniques such as the order of raster balas or the attention of the overall sequence do not lie well with high -dimension video data.
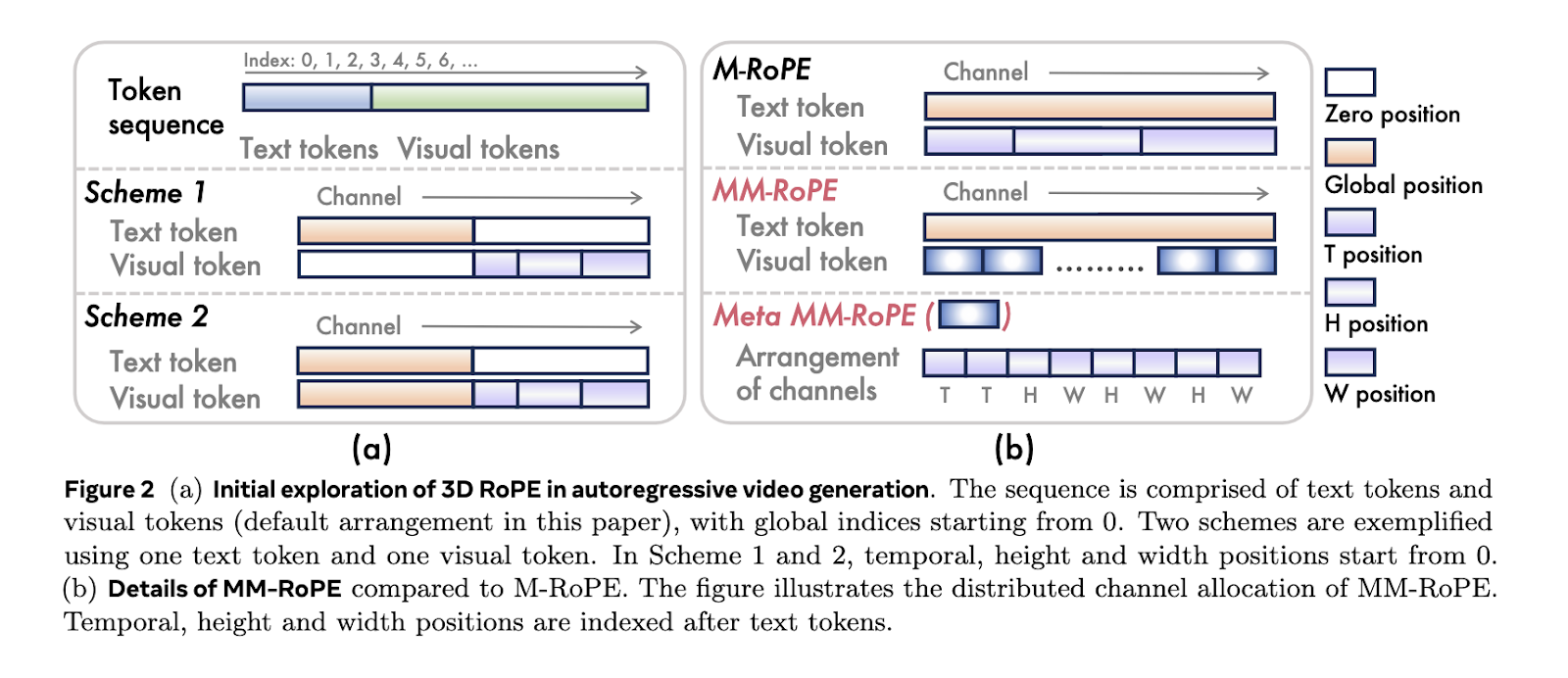
The Damo Academy, Hupan Lab's research team and the University of Zhejiang from the Alibaba group presented Lumos-1. It is a unified model for the generation of self -regressive videos which remains faithful to the architecture of model of large language. Unlike previous tools, Lumos-1 eliminates the need for external encoders and changes very little in the original LLM design. The model uses the mm rope, or the multimodal rotary position incorporations, to meet the challenge of modeling the three -dimensional structure of the video. The model also uses an approach to token dependence. This preserves intra-trame bidirectionality and inter-trame temporal causality, which is more naturally aligned with video data behavior.
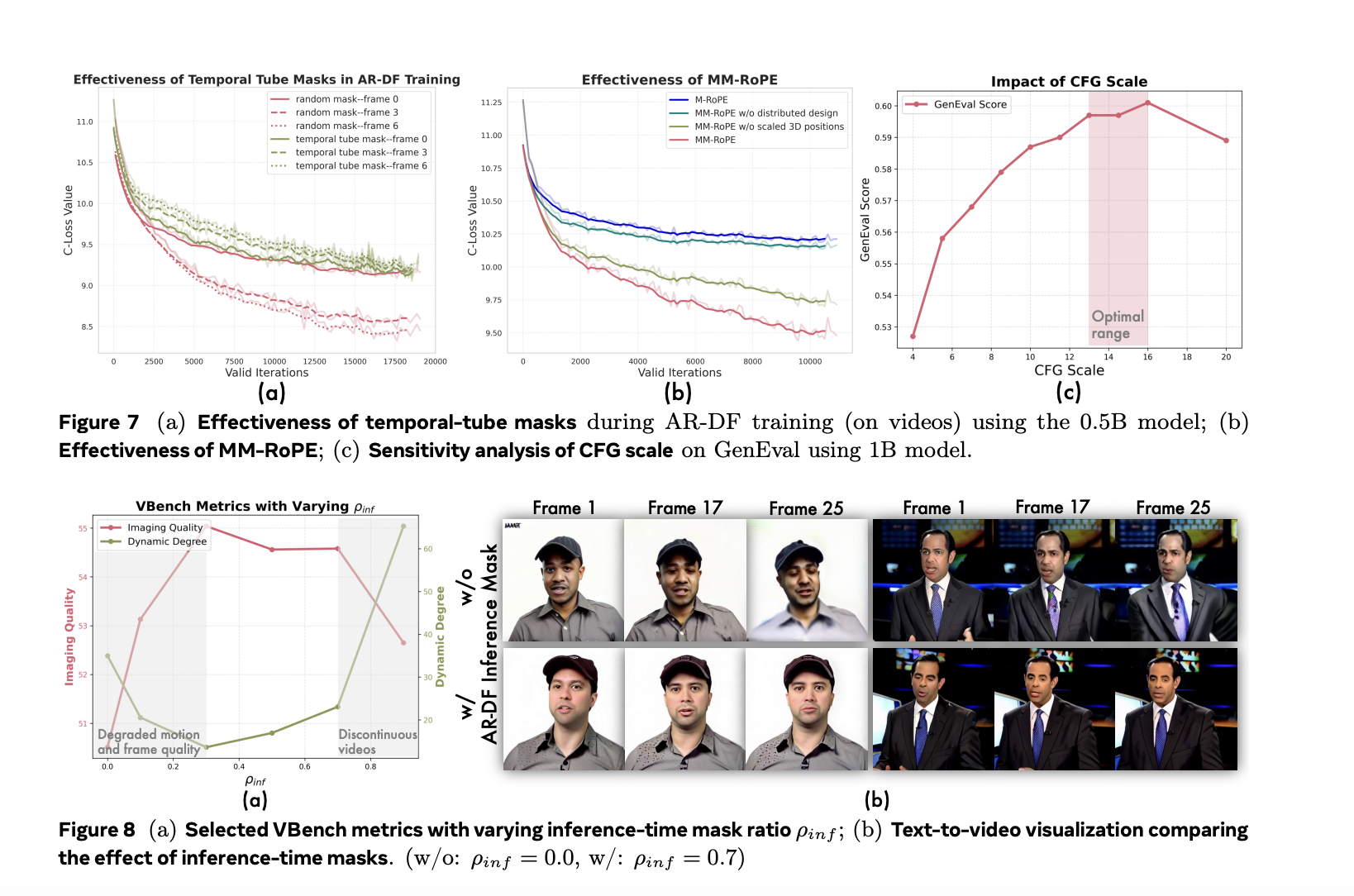
In the rope MM, researchers broaden existing rope methods to balance the frequency spectrum for spatial and temporal dimensions. The traditional decay 3D rope the frequency development, causing a loss of details or an ambiguous positional coding. Restructure attributions mm mm so that temporal, height and width each receive a balanced representation. To treat the imbalance of losses in the formation by frame, Lumos-1 presents AR-DF or forcing of self-regressive discreet diffusion. He uses the masking of temporal tube during training, so the model does not rely too much on non -masked spatial information. This even guarantees learning through the video sequence. The inference strategy reflects the training, allowing a generation of high quality frame without degradation.
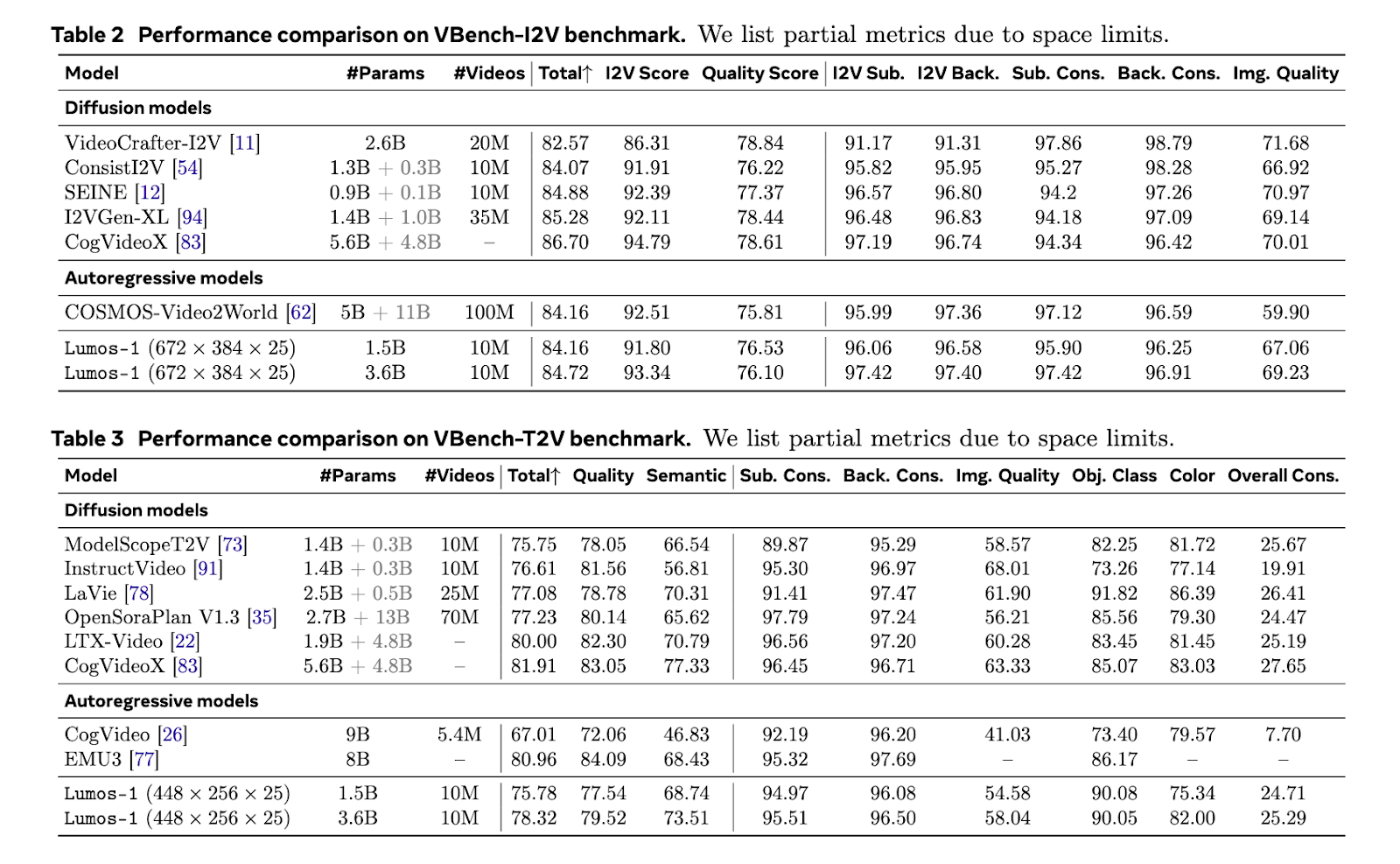
Lumos-1 was formed from zero on 60 million images and 10 million videos, using only 48 GPUs. This is considered to be economical in memory given the training scale. The model obtained results comparable to the best models in the field. It corresponded to the results of the EMU3 on the Geneval references. He worked equivalent to Cosmos-Video2world on the VBENCH-I2V test. He also competed with OpenSoraplan's outings on the Vbench-T2V reference. These comparisons show that the light training of Lumos-1 does not compromise competitiveness. The model supports the generation of video, video image and text image. This demonstrates a strong generalization between the modalities.

Overall, this research identifies and not only meets the basic challenges of spatio-temporal modeling for the generation of videos, but also shows how Lumos-1 establishes a new standard to unify efficiency and efficiency in self-regressive frames. By successfully mixing advanced architectures with innovative training, Lumos-1 opens the way to the next generation of models of generation of high quality videos and opens up new ways for future multimodal searches.
Discover the Paper And Github. All the merit of this research goes to researchers in this project.
Nikhil is an intern consultant at Marktechpost. It pursues a double degree integrated into materials at the Indian Kharagpur Institute of Technology. Nikhil is an IA / ML enthusiast who is still looking for applications in fields like biomaterials and biomedical sciences. With a strong experience in material science, he explores new progress and creates opportunities to contribute.
