The Hanyuan team from Tencent introduced HUNYUAN-A13BA new open source Great language model built on a sparse Mixture of experts (MOE) architecture. Although the model includes 80 billion parameters in total, only 13 billion are active during inference, offering a very effective balance between performance and the cost of calculation. He supports Watch out for the group request (GQA),, Context length 256Kand a Double -style reasoning framework which rocks between rapid and slow thought.
Designed for effective deployment and robust reasoning, Hunyuan-A13B obtains high-level performance through aging references, in particular BFCL-V3,, bench τ,, C3 benchAnd ComplexOften surprising larger models in tool call scenarios and long context.
Architecture: sparse MOE with active parameters 13B
Basically, Hanyuan-A13B follows a fine grain MOE design comprising 1 shared expert And 64 unrelated expertswith 8 experts activated by front pass. This architecture, supported by scaling experiences, guarantees the consistency of performance while maintaining low inference costs. The model includes 32 layers, uses Swiglu Activations, a vocabulary size of 128K and integrates GQA for improved memory efficiency during long context inference.
The MOE configuration of the model is associated with optimization training program: A 20T pre-training phase, followed by a rapid receipt and long-context adaptation. This last phase evolves the context window first at 32K then to 256K tokens using the positional coding of NTK-Aware, guaranteeing stable performance with long sequence length.
Double -style reasoning: fast and slow reflection
A remarkable characteristic of Hunyuan-A13B is its Double mode of thought chain (COT) ability. It supports both a low latency fast mode for routine queries and a more elaborate slow Mode for reasoning in several stages. These modes are controlled via a simple tag system: /no think for rapid inference and /think For reflective reasoning. This flexibility allows users to adapt the calculation cost to the complexity of tasks.
Post-training: learning to strengthen with specific reward models
Hunyuan-A13B's post-training pipeline includes Fine refinement supervised in several stages (SFT) And Reinforcement learning (RL) Both both specific to reasoning and general tasks. The RL steps incorporate Rewards based on results And Breakdown specific to the toolIncluding Sandbox execution environments for code and checks based on rules for agents.
In the training phase of agents, the team synthesized various scenarios for using tools with planner, verifier and tools roles, generating on 20,000 format combinations. This has strengthened the capacity of Hunyuan-A13B to execute real world work flows such as processing of spreadsheets, information search and structured reasoning.

Evaluation: advanced agentic performance
HUNYUAN-A13B shows Solid reference results Through various NLP tasks:
- On MATHEMATICS,, CmathAnd GpqaIt marks in relation to dense models and larger and more MOE.
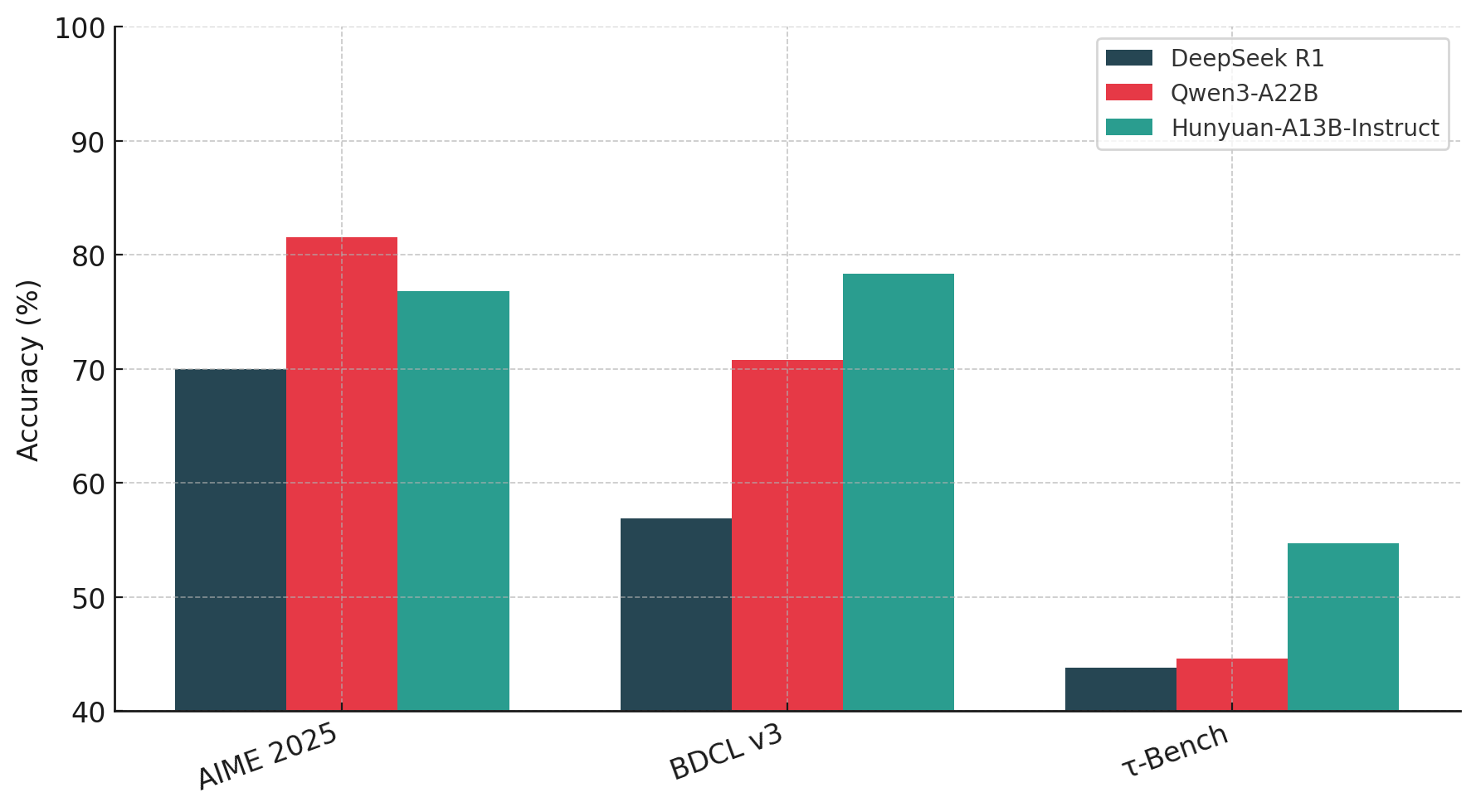
- It exceeds Qwen3-A22B And Deepseek R1 In logical reasoning (BBH: 89.1; Zebralogic: 84.7).
- In coding, he holds up with 83.9 on MBPP and 69.3 on multipl-e.
- For agent tasksIt leads to BFCL-V3 (78.3) And Complexfuncbench (61.2)Validate its tool capacities.
Understanding with long context is another highlight. On PingouinscrollsIt marks 87.7 – Just shy from Gemini 2.5 Pro. On RULERHe supports high performance (73.9) even 64K context – 128Koutperform larger models like QWEN3-A22B and Deepseek R1 in contextual resilience.

Optimization and deployment of inference
HUNYUAN-A13B is entirely integrated into popular inference frames such as vllm,, SglangAnd Tensorrt-LLM. It supports precision formats such as W16a16,, W8a8And KV FP8 Cacheas well as features such as Automatic prefix cover And Preplacement of songs. He realizes until 1981.99 tokens / dry Flower on an input of 32 lots (input 2048, output length 14336), which makes it practical for real -time applications.
Open source and industry relevance
Available on Face And GithubHunyuan-A13B is released with a permissive opening license. It is designed for effective research and production in production, especially in environments sensitive to latency and long -context tasks.
By combining MOE scalability,, Agental reasoningAnd Open source accessibilityHunyuan-A13B de Tencent offers a convincing alternative to the LLM of heavy goods vehicles, allowing wider experimentation and deployment without capacity to sacrifice.
Discover the Paper. All the merit of this research goes to researchers in this project. Also, don't hesitate to follow us Twitter And don't forget to join our Subseubdredit 100k + ml and subscribe to Our newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc .. as a visionary entrepreneur and engineer, AIF undertakes to exploit the potential of artificial intelligence for social good. His most recent company is the launch of an artificial intelligence media platform, Marktechpost, which stands out from its in-depth coverage of automatic learning and in-depth learning news which are both technically solid and easily understandable by a large audience. The platform has more than 2 million monthly views, illustrating its popularity with the public.
