| What is included in this article: |
| Performance breakthroughs – 2x faster inference and 3x faster training Technical architecture – Hybrid design with blocks of convolution and attention Model specifications – Three -sized variants (350 m, 700m, 1.2b settings) Reference results – higher performance compared to similar size models Deployment optimization – Design focused on the edges for various equipment Open source accessibility – Licenses based on Apache 2.0 Market implications – Impact on the adoption of AI |
The landscape of artificial intelligence on the devices has leapped forward with the release of LFM2 by liquid AI, their second generation liquid foundation models. This new series of generative AI models represents a paradigm shift in EDGE IT, offering unprecedented performance optimizations specially designed for a deployment on devices while maintaining competitive quality standards.
Revolutionary performance gains
LFM2 establishes new benchmarks in the AI Edge space by making remarkable improvements of efficiency through several dimensions. The models provide 2x the faster decoding and prefusion performance compared to QWEN3 on CPU architectures, a critical progression for real -time applications. Perhaps more impressive, the training process itself has been optimized to obtain 3x training faster compared to the previous LFM generation, making LFM2 the most profitable path to build capable general AI systems.

These performance improvements are not simply progressive but represent a fundamental breakthrough in strengthening powerful AI accessible on resource -related devices. The models are specifically designed to unlock latency in milliseconds, out -of -line resilience and data confidentiality – essential capacities for phones, laptops, cars, robots, laptops, satellites and other termination points that must reason in real time.
Hybrid architecture innovation
The technical foundation of LFM2 lies in its new hybrid architecture which combines the best aspects of the mechanisms of convolution and attention. The model uses a sophisticated structure of 16 blocks made up of 10 double -range double -range convolution blocks and 6 blocks of attention from the grouped query (GQA). This hybrid approach is based on the pioneering works of the liquid on the liquid time findings networks (LTC), which has introduced recurrent neural networks in continuous time with linear dynamic systems modulated by interconnected non -linear input doors.
At the heart of this architecture is the framework of the operator of linear input variation (LIV), which makes it possible to generate weights on the fly from the entrance on which they act. This allows convolutions, recurrences, attention and other structured layers to go into a unified and aware framework of the entrance. The LFM2 Convolution blocks implement multiplicative doors and short convolution, creating first -rate linear systems that converge at zero after a finished time.
The architecture selection process used the star, the AI neural neural architecture search engine, which has been modified to assess language modeling capacities beyond the loss of traditional validation and perplexity measures. Instead, he uses a complete suite of more than 50 internal assessments that assess various capacities, including recalling knowledge, multi-hop reasoning, understanding of low-resources languages, instructions and the use of tools.

Full range of the model
LFM2 is available in three strategic size configurations: 350m, 700m and 1.2b, each optimized for different deployment scenarios while retaining the advantages of basic efficiency. All models were formed out of 10 billions of tokens drawn from a carefully organized pre-training corpus comprising approximately 75% English, 20% multilingual content and 5% code data from the web and under license.
The training methodology incorporates the distillation of knowledge by using the LFM1-7B model existing as a teacher model, with a cross entropy between the results of LFM2 students and the teacher outputs serving as a main training signal throughout the 10T tokens training process. The length of the context was extended to 32K during pre-training, allowing models to effectively manage longer sequences.

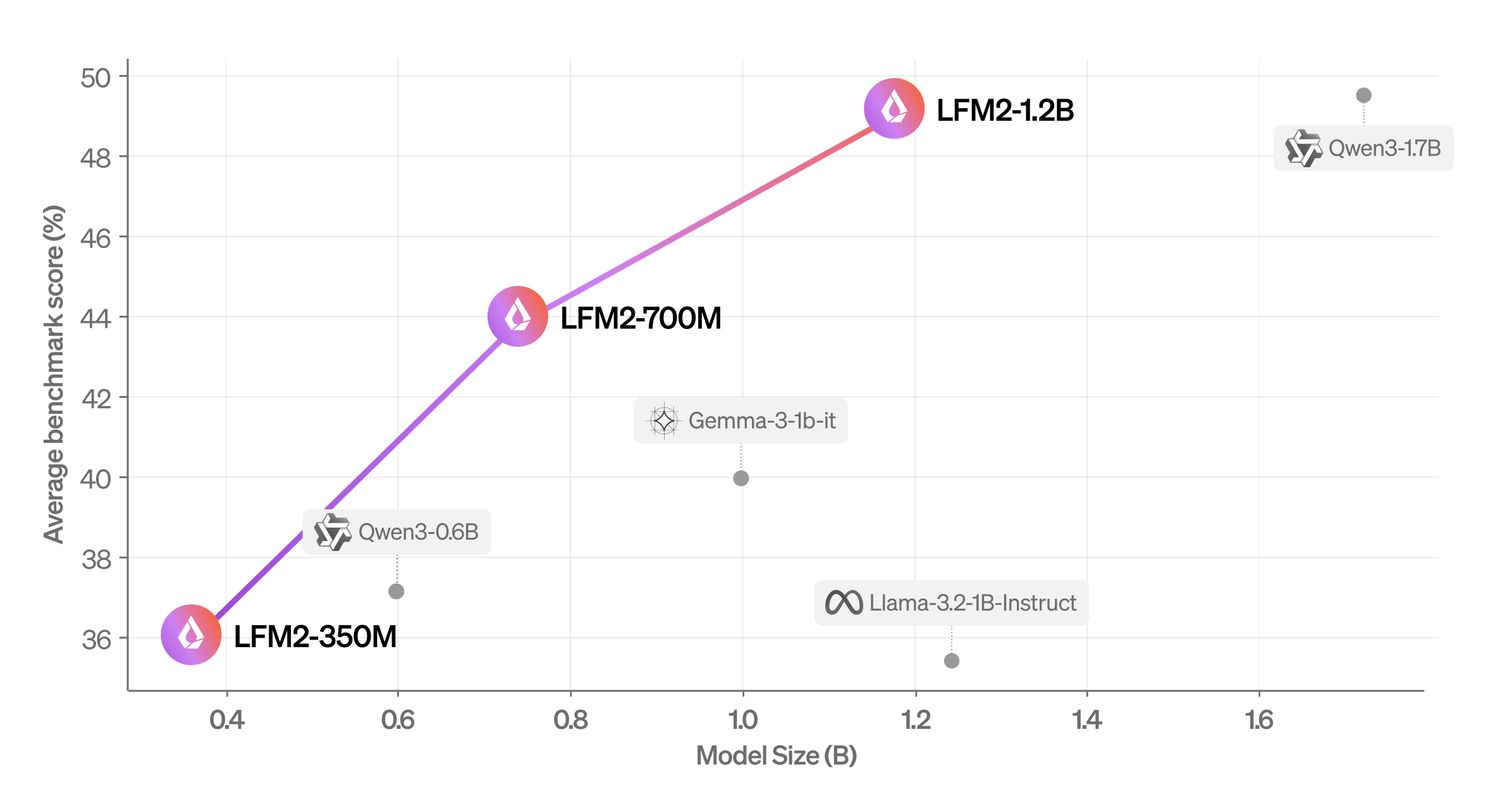
Superior reference performance
The results of the evaluation demonstrate that LFM2 considerably surpasses models of similar size in several reference categories. The LFM2-1.2B model works competitively with QWEN3-1.7B despite 47% less parameters. Similarly, LFM2-700M surpasses Gemma 3 1B, while the smallest control point LFM2-350M remains competitive with QWEN3-0.6B and LLAMA 3.2 1B instruct.
Beyond automated references, LFM2 shows higher conversational capacities in multi-tours dialogues. Using the WildChat data set and the LLM-AA-AA-Judge assessment frame, LFM2-1.2B has shown significant advantages on LLAMA 3.2 1B Instruct and Gemma 3 1B while corresponding to QWEN3-1.7B performance despite their significantly smaller and faster sensitivity.

Deployment optimized by the edges
The models excel in the real world deployment scenarios, after having been exported to several inference frames, notably Executorch of Pytorch and the OpenSource Llama.cpp library. Tests on target equipment, including Samsung Galaxy S24 Ultra and AMD Ryzen platforms, demonstrate that LFM2 dominates the Pareto border for preference speed of the preference and decoding compared to the size of the model.
The strong performance of the CPU is effectively translated into accelerators such as GPU and NPU after optimization of the nucleus, which makes LFM2 adapted to a wide range of hardware configurations. This flexibility is crucial for the various ecosystem of on -board devices that require AI capacities available.
Conclusion
The release of LFM2 deals with a critical gap in the AI deployment landscape where the transition from inference based on the cloud to the edges based on the edges is accelerated. By allowing the latency of millisecond, offline operation and data confidentiality, LFM2 unlocks new possibilities of integration of AI in the sectors of consumer electronics, robotics, intelligent devices, finances, electronic and education.
The technical achievements represented in LFM2 indicate a maturation of AI Edge technology, where compromises between the capacity of the model and the deployment efficiency are successfully optimized. While companies go from Cloud LLMS to profitable, fast, private and localized intelligence, LFM2 is positioned as a fundamental technology for the next generation of AI devices and applications.
Asif Razzaq is the CEO of Marktechpost Media Inc .. as a visionary entrepreneur and engineer, AIF undertakes to exploit the potential of artificial intelligence for social good. His most recent company is the launch of an artificial intelligence media platform, Marktechpost, which stands out from its in-depth coverage of automatic learning and in-depth learning news which are both technically solid and easily understandable by a large audience. The platform has more than 2 million monthly views, illustrating its popularity with the public.