The recent progress in improving speech (SE) has passed beyond traditional methods of predicting mask or signal, turning rather towards pre-formed audio models for richer and more transferable features. These models, such as WAVLM, extract significant audio incorporations that improve SE performance. Some approaches use these interests to predict masks or combine with spectral data for better precision. Others explore generative techniques, using neural vocoders to rebuild clean speech directly from noisy incorporations. Although effective, these methods often involve the freezing of pre-formed models or require a thorough fine adjustment, which limits adaptability and increases calculation costs, rendering the transfer to other more difficult tasks.
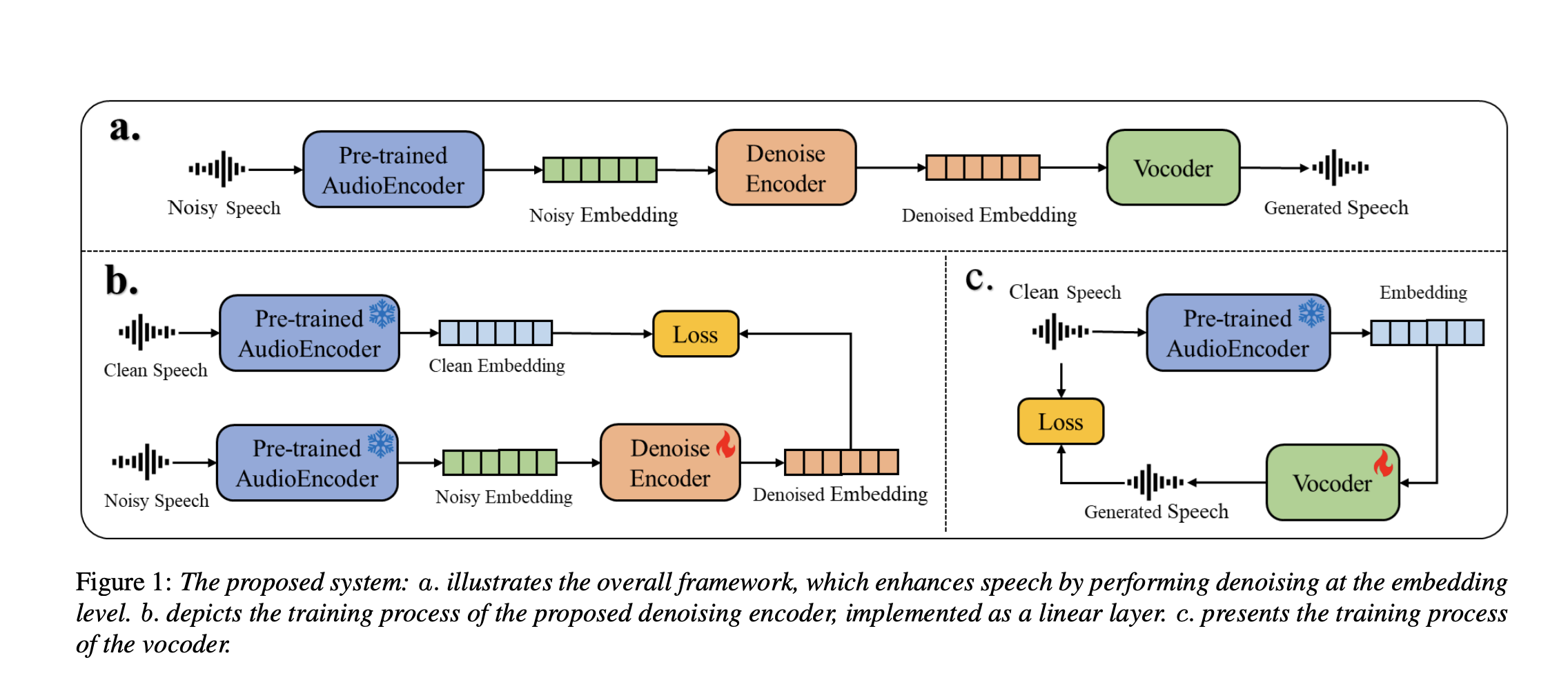
MILM PLUS researchers, Xiaomi Inc., have a light and flexible method that uses pre-formed models. First, audio incorporations are extracted from noisy speech using a frozen audioencoder. These are then cleaned by a small fabric flagship and transmitted to a vocoder to generate a clean word. Unlike models specific to the task, the audioecoder and the vocoder are pre-formed separately, which makes the system adaptable to tasks such as derever or separation. Experiences have shown that generative models surpass those discriminating in terms of the quality of speech and loyalty of speakers. Despite its simplicity, the system is very effective and even exceeds a model leader in listening tests.

The proposed speech improvement system is divided into three main components. First, a noisy speech went through a pre-formulated audioencoder, which generates noisy audio incorporations. A Denoise encoder then refines these integers to produce cleaner versions, which are ultimately converted to speech by a vocoder. Although the encoder and the Denoise vocoder are formed separately, they both count on the same frozen and pre-formulated audioencoder. During training, the Denoise encoder minimizes the difference between noisy and clean incorporations, which are both generated in parallel from paired speech samples, using an average square loss of error. This coder is built using an architecture lives with standard activation and standardization layers.
For the vocoder, the training is done in a self-supervised manner using clean speech data. The vocoder learns to reconstruct the wavelems of speech from audio incorporations by predicting the Fourier spectral coefficients, which are converted into audio by the opposite transformation of Fourier in the short term. It adopts a slightly modified version of the Vocos framework, tailor -made to accommodate various audioencoders. A generative configuration of an opponent network (GAN) is used, where the generator is based on Pronnese, and discriminators include both multi-periodes and multi-resolution types. The training also incorporates opponent, reconstruction and operating losses. Above all, throughout the process, audioencoder remains unchanged, using weights from models accessible to the public.
The evaluation has shown that generative audioencoders, such as Dasheng, have systematically surpassed audio-discriminatory. On the DNS1 data set, Dasheng obtained a 0.881 speaker similarity score, while Wavlm and Whisper marked 0.486 and 0.489, respectively. In terms of the quality of speech, non -intrusive measures such as DNSMOS and NISQAV2 have indicated notable improvements, even with smaller clearing. For example, VIE3 has reached a DNSMOS of 4.03 and a Nisqav2 score of 4.41. Subjective listening tests involving 17 participants showed that Dasheng produced an average opinion score (MOS) of 3.87, exceeding the DEMUCs at 3.11 and LMS at 2.98, highlighting its strong perceptual performance.

In conclusion, the study presents a system of improvement of practical and adaptable speech which is based on audioencors and pre-formed generative vocoders, by avoiding the need for a complete adjustment of the model. By bounding audio incorporations using a light coder and reconstructing speech with a pre-formulated vocoder, the system achieves both calculation and high performance efficiency. The evaluations show that generative audioencoders considerably surpass those discriminating in terms of the quality of speech and loyalty of speakers. The Compact Denoise Coder maintains high perceptual quality even with fewer parameters. Subjective listening tests also confirm that this method offers better perceptual clarity than an existing cutting -edge model, highlighting its efficiency and versatility.
Discover the Paper And GitHub page. All the merit of this research goes to researchers in this project. Ready to connect with 1 million developers / engineers / researchers? Find out how NVIDIA, LG AI Research and the best IA companies operate Marktechpost to reach their target audience (Learn more)
Sana Hassan, consulting trainee at Marktechpost and double -degree student at Iit Madras, is passionate about the application of technology and AI to meet the challenges of the real world. With a great interest in solving practical problems, it brings a new perspective to the intersection of AI and real life solutions.