The image generation of the image text (T2I) has evolved to include approaches focused on the subject, which improve standard T2I models by incorporating reference images alongside the text prompts. This progression allows a more precise representation of subject in the images generated. Despite promising applications, the T2I generation focused on the subject is faced with an important challenge to lack reliable automatic evaluation methods. Current metrics focus on the alignment of the prosper text, that is to say the coherence of the subjects, when the two are essential for an effective generation focused on the subject. Although there are more correlative evaluation methods, they rely on costly API calls to models like GPT-4, limiting their practicality for in-depth research applications.
Assessment approaches for visual language models (VLMS) include various frameworks, with image text assessments (T2I) focusing on image quality, diversity and alignment of text. Researchers use integration -based measures as clip and Dino for the evaluation of the subject -oriented generation to measure the preservation of subjects. Complex measures such as Viescore and Dreambench ++ use GPT-4O to assess the textual alignment and the coherence of subjects, but at a higher calculation cost. T2I methods focused on subjects have developed on two main paths: the general models in specialized versions capturing specific subjects and styles, or allowing wider applicability through examples at a blow. These approaches to a blow include techniques based on the adapter and without adapter.
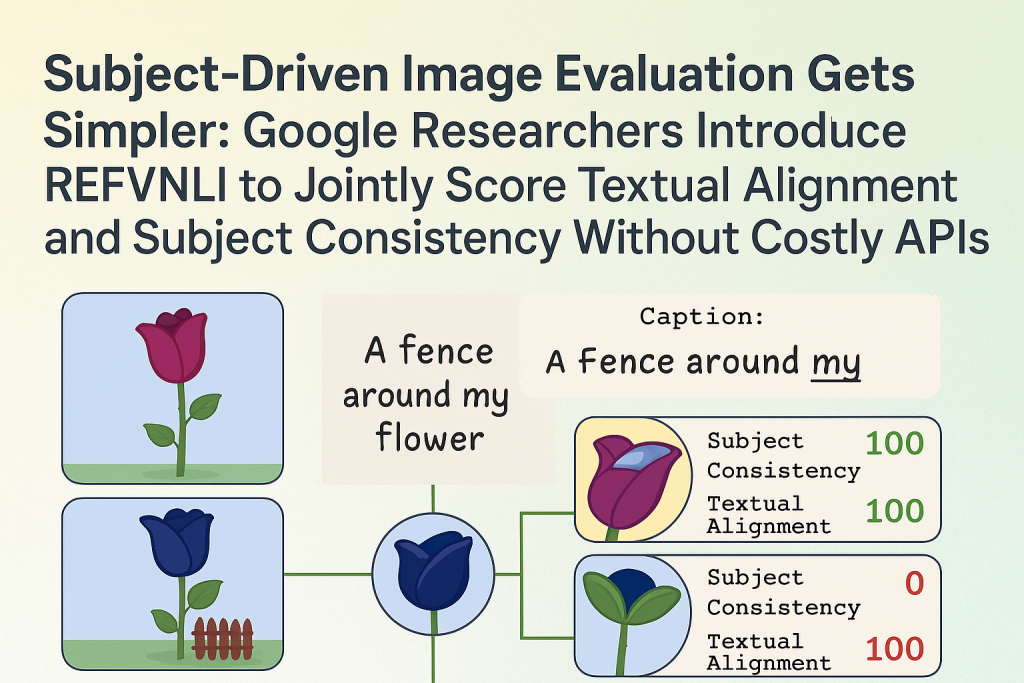
Researchers from Google Research and Ben Gurion University proposed Refvnli, a profitable metric that simultaneously assesses text alignment and the preservation of subjects in the T2i generation focused on the subject. He predicts two scores, the textual alignment and the coherence of the subject, in a single classification based on a triplet

For Refvnli training, a large -scale Triplet data set
For the consistency of subjects, Refvnli ranks among the two main measures in all categories and works better in the object category, exceeding Dreamembench ++ based on GPT4O of 6.3 points. On imagenhub, Refvnli reaches a top two classification for textual alignment in the animal category and the highest score for objects, surpassing the best model not finished by 4 points. It also works well in the multi-subject settings, ranking in the first three. Refvnli obtains the highest textual alignment score on Kitten, but has limits of coherence of subjects because of his sensation sensitive to identity which even penalizes minor inadequacy in the traits defining identity. Ablation studies reveal that joint training offers additional advantages, a single task training leading to performance drops.

In this article, the researchers introduced Refvnli, a reliable and profitable metric for the T2I generation focused on the subject which resolves both textual alignment and challenges of preservation of subjects. Trained on an automatically extensive generated data set, REFVNLI effectively balances robustness to agnostic identity variations such as laying, lighting and background with sensitivity to identity -specific features, including facial characteristics, object shape and unique details. Future research guidelines include improving the REFVNLI evaluation capacities between artistic styles, the management of textual modifications that explicitly modify the attributes defining the identity and improving the processing of several reference images for unique and distinct subjects.
Discover the Paper. Also, don't forget to follow us Twitter And join our Telegram And Linkedin Group. Don't forget to join our 90K + ML Subdreddit.

Sajjad Ansari is a last year's first year of the Kharagpur Iit. As a technology enthusiast, he plunges into AI's practical applications by emphasizing the understanding of the impact of AI technologies and their real implications. It aims to articulate complex AI concepts in a clear and accessible way.
