In this tutorial, we show how to build a system of answers from powerful and intelligent questions by combining the forces of TAVILY Research API,, ChromiumGoogle Gemini LLMS and the Langchain frame. The pipeline uses real -time web search using the semantic and semantic document cache with a chroma vector store and the generation of contextual response via the Gemini model. These tools are integrated via the modular components of Langchain, such as Runnablelambda, ChatPrompttemplate, Conversationbuffermemory and GooglegenerativeAdeddings. It goes beyond simple questions and answers by introducing a hybrid recovery mechanism that checks the fittings of hide and seek before calling new research on the web. The documents recovered are intelligently formatted, summarized and passed through a structured LLM prompt, with attention to the allocation of the source, the user history and the notation of confidence. Key functions such as advanced rapid engineering, analysis of feelings and dynamic updates of vector stores make this pipeline adapted to advanced use cases such as research assistance, the specific summary of the field and intelligent agents.
!pip install -qU langchain-community tavily-python langchain-google-genai streamlit matplotlib pandas tiktoken chromadb langchain_core pydantic langchainWe install and improve a full set of libraries necessary to create an advanced AI research assistant. It includes tools for recovery (Tavily-Python, Chromadb), LLM integration (Langchain-Google-Genai, Langchain), data handling (Pandas, Pyndantic), Visualization (Matplotlib, Streamlit) and Tokenization (Tiktoken). These components form the base base for the construction of a QA system in real time and aware.
import os
import getpass
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import json
import time
from typing import List, Dict, Any, Optional
from datetime import datetimeWe import essential python libraries used in the notebook. It includes standard libraries for environmental variables, secure inputs, time monitoring and data types (OS, GetPass, Time, Taping, Datetime). In addition, it provides basic data science tools such as pandas, matplotlib and Numpy for data management, visualization and digital calculations, as well as JSON for the analysis of structured data.
if "TAVILY_API_KEY" not in os.environ:
os.environ("TAVILY_API_KEY") = getpass.getpass("Enter Tavily API key: ")
if "GOOGLE_API_KEY" not in os.environ:
os.environ("GOOGLE_API_KEY") = getpass.getpass("Enter Google API key: ")
import logging
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s")
logger = logging.getLogger(__name__)We safely initialize API keys for TAVILY and Google Gemini by inviting users if they are not already defined in the environment, ensuring safe and reproducible access to external services. He also configures a standardized journalization configuration using the Python journalization module, which helps monitor the execution flow and the capture of messages of debug or error throughout the notebook.
from langchain_community.retrievers import TavilySearchAPIRetriever
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser, JsonOutputParser
from langchain_core.prompts import ChatPromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_google_genai import ChatGoogleGenerativeAI, GoogleGenerativeAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains.summarize import load_summarize_chain
from langchain.memory import ConversationBufferMemoryWe import key components of the Langchain ecosystem and its integrations. It brings the tavortyaarchapiretriever for real -time web search, chroma for vector storage and Googleratifaaai modules for cat and integration models. The Core Langchain modules such as ChatPrompttemplate, Runnablelambda, Conversationbuffermemory and output analyzers allow flexible inviting construction, memory management and pipeline execution.
class SearchQueryError(Exception):
"""Exception raised for errors in the search query."""
pass
def format_docs(docs):
formatted_content = ()
for i, doc in enumerate(docs):
metadata = doc.metadata
source = metadata.get('source', 'Unknown source')
title = metadata.get('title', 'Untitled')
score = metadata.get('score', 0)
formatted_content.append(
f"Document {i+1} (Score: {score:.2f}):n"
f"Title: {title}n"
f"Source: {source}n"
f"Content: {doc.page_content}n"
)
return "nn".join(formatted_content)We define two essential components for document research and management. The Searchqueryerror class creates a personalized exception to manage disabled or failed research requests. The format_docs function processes a list of documents recovered by extracting metadata such as the title, the source and the relevance score and formatting them in a clean and readable chain.
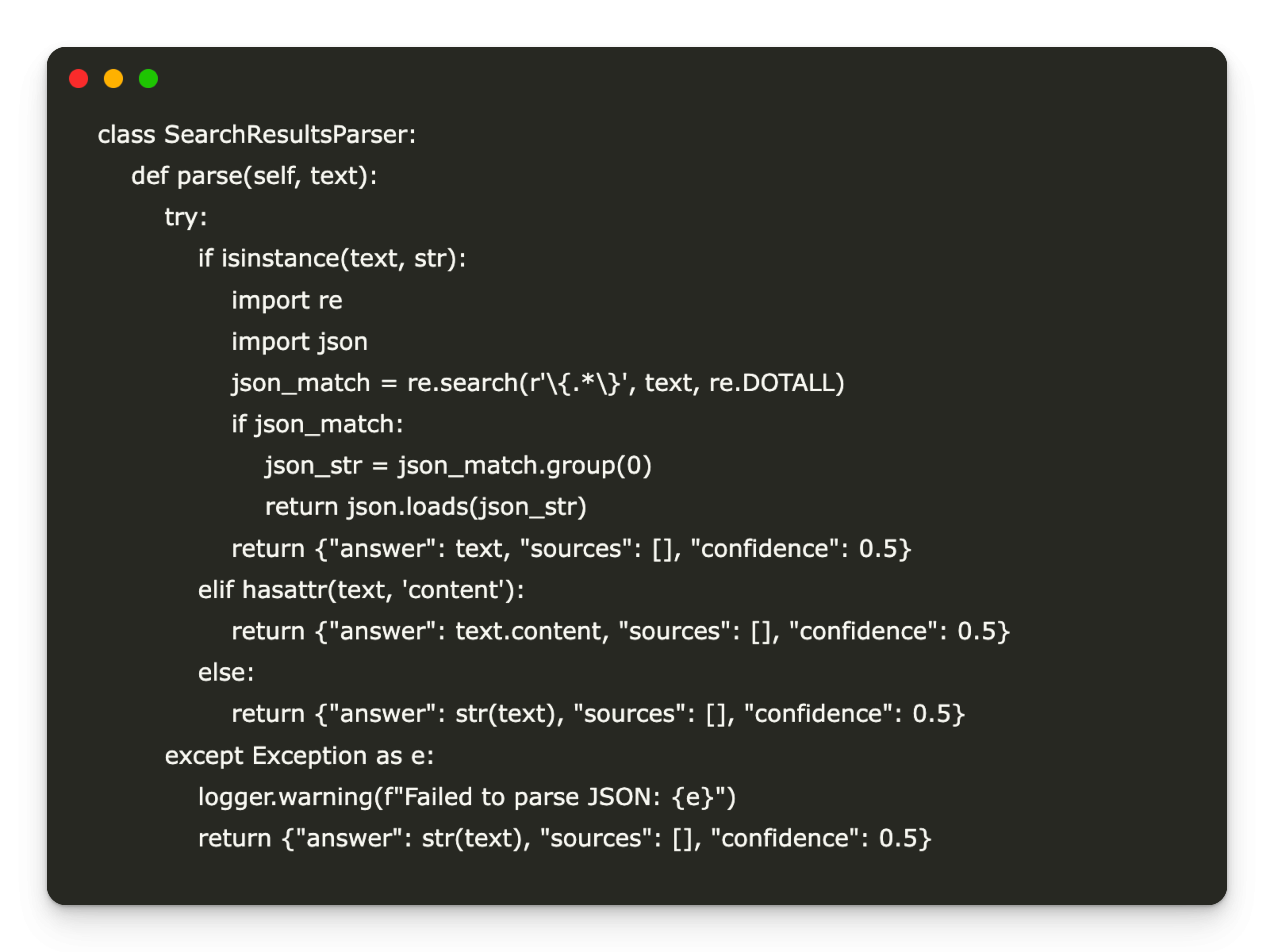
class SearchResultsParser:
def parse(self, text):
try:
if isinstance(text, str):
import re
import json
json_match = re.search(r'{.*}', text, re.DOTALL)
if json_match:
json_str = json_match.group(0)
return json.loads(json_str)
return {"answer": text, "sources": (), "confidence": 0.5}
elif hasattr(text, 'content'):
return {"answer": text.content, "sources": (), "confidence": 0.5}
else:
return {"answer": str(text), "sources": (), "confidence": 0.5}
except Exception as e:
logger.warning(f"Failed to parse JSON: {e}")
return {"answer": str(text), "sources": (), "confidence": 0.5}The SearchResultser class provides a robust method to extract structured information from LLM responses. He tries to analyze a JSON type chain from the output of the model, returning to a raw text response format if the analysis fails. It manages chain outputs and message objects graciously, ensuring coherent processing downstream. In the event of errors, he records a warning and returns a rescue response containing the gross response, empty sources and a default trust score, improving tolerance for system defects.
class EnhancedTavilyRetriever:
def __init__(self, api_key=None, max_results=5, search_depth="advanced", include_domains=None, exclude_domains=None):
self.api_key = api_key
self.max_results = max_results
self.search_depth = search_depth
self.include_domains = include_domains or ()
self.exclude_domains = exclude_domains or ()
self.retriever = self._create_retriever()
self.previous_searches = ()
def _create_retriever(self):
try:
return TavilySearchAPIRetriever(
api_key=self.api_key,
k=self.max_results,
search_depth=self.search_depth,
include_domains=self.include_domains,
exclude_domains=self.exclude_domains
)
except Exception as e:
logger.error(f"Failed to create Tavily retriever: {e}")
raise
def invoke(self, query, **kwargs):
if not query or not query.strip():
raise SearchQueryError("Empty search query")
try:
start_time = time.time()
results = self.retriever.invoke(query, **kwargs)
end_time = time.time()
search_record = {
"timestamp": datetime.now().isoformat(),
"query": query,
"num_results": len(results),
"response_time": end_time - start_time
}
self.previous_searches.append(search_record)
return results
except Exception as e:
logger.error(f"Search failed: {e}")
raise SearchQueryError(f"Failed to perform search: {str(e)}")
def get_search_history(self):
return self.previous_searchesThe TAVILYREVER IMPROVED CLASS is a personalized packaging around the TavillyaarChapiretriever, adding greater flexibility, control and traceability to research operations. It supports advanced features such as limiting the research depth, inclusion / exclusion filters of the domain and the number of configurable results. The method invoked performs web research and follows the metadata of each request (horoditing, response time and number of results), storing it for later analysis.
class SearchCache:
def __init__(self):
self.embedding_function = GoogleGenerativeAIEmbeddings(model="models/embedding-001")
self.vector_store = None
self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
def add_documents(self, documents):
if not documents:
return
try:
if self.vector_store is None:
self.vector_store = Chroma.from_documents(
documents=documents,
embedding=self.embedding_function
)
else:
self.vector_store.add_documents(documents)
except Exception as e:
logger.error(f"Failed to add documents to cache: {e}")
def search(self, query, k=3):
if self.vector_store is None:
return ()
try:
return self.vector_store.similarity_search(query, k=k)
except Exception as e:
logger.error(f"Vector search failed: {e}")
return ()The Searchcache class implements a semantic cache layer that stores and recovers documents using vector incorporations for an effective similarity search. He uses GooglegeneratifaDddings to convert documents into dense vectors and stores them in a chroma vector database. The Add_Documents initializes or updates the vector store, while the search method allows rapid recovery of the most relevant cache documents based on the semantic similarity. This reduces redundant API calls and improves response times for repeated or related queries, serving as a light hybrid memory layer in the AI assistant pipeline.
search_cache = SearchCache()
enhanced_retriever = EnhancedTavilyRetriever(max_results=5)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
system_template = """You are a research assistant that provides accurate answers based on the search results provided.
Follow these guidelines:
1. Only use the context provided to answer the question
2. If the context doesn't contain the answer, say "I don't have sufficient information to answer this question."
3. Cite your sources by referencing the document numbers
4. Don't make up information
5. Keep the answer concise but complete
Context: {context}
Chat History: {chat_history}
"""
system_message = SystemMessagePromptTemplate.from_template(system_template)
human_template = "Question: {question}"
human_message = HumanMessagePromptTemplate.from_template(human_template)
prompt = ChatPromptTemplate.from_messages((system_message, human_message))
We initialize the central components of the AI assistant: a semantic Searchcache, the improved tavilyrriever for the online request and a conversation of conversation to keep cat history through turns. It also defines a structured prompt using ChatPrompttemplate, guiding the LLM to act as a research assistant. The invite applies strict rules for factual precision, use of the context, a source quote and a concise response, guaranteeing reliable and founded responses.
def get_llm(model_name="gemini-2.0-flash-lite", temperature=0.2, response_mode="json"):
try:
return ChatGoogleGenerativeAI(
model=model_name,
temperature=temperature,
convert_system_message_to_human=True,
top_p=0.95,
top_k=40,
max_output_tokens=2048
)
except Exception as e:
logger.error(f"Failed to initialize LLM: {e}")
raise
output_parser = SearchResultsParser()
We define the GET_LLM function, which initializes a Google Gemini language model with configurable parameters such as the model name, temperature and decoding settings (for example, TOP_P, TOP_K and TOKENS MAX). It ensures robustness with the management of errors for the initialization of the failed model. An instance of Searchresultsparser is also created to standardize and structure the raw responses of the LLM, allowing coherent treatment downstream of responses and metadata.
def plot_search_metrics(search_history):
if not search_history:
print("No search history available")
return
df = pd.DataFrame(search_history)
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(range(len(df)), df('response_time'), marker="o")
plt.title('Search Response Times')
plt.xlabel('Search Index')
plt.ylabel('Time (seconds)')
plt.grid(True)
plt.subplot(1, 2, 2)
plt.bar(range(len(df)), df('num_results'))
plt.title('Number of Results per Search')
plt.xlabel('Search Index')
plt.ylabel('Number of Results')
plt.grid(True)
plt.tight_layout()
plt.show()
The Plot_Search_metrics function visualizes the performance trends of the requests spent using Matplotlib. He converts research history into a dataaframa and traces two sub-graphics: one showing the response time by research and the other displaying the number of results returned. This helps to analyze the effectiveness of the system and the quality of research over time, by helping developers to refine the retriever or to identify the bottlenecks in the use of the real world.
def retrieve_with_fallback(query):
cached_results = search_cache.search(query)
if cached_results:
logger.info(f"Retrieved {len(cached_results)} documents from cache")
return cached_results
logger.info("No cache hit, performing web search")
search_results = enhanced_retriever.invoke(query)
search_cache.add_documents(search_results)
return search_results
def summarize_documents(documents, query):
llm = get_llm(temperature=0)
summarize_prompt = ChatPromptTemplate.from_template(
"""Create a concise summary of the following documents related to this query: {query}
{documents}
Provide a comprehensive summary that addresses the key points relevant to the query.
"""
)
chain = (
{"documents": lambda docs: format_docs(docs), "query": lambda _: query}
| summarize_prompt
| llm
| StrOutputParser()
)
return chain.invoke(documents)These two functions improve the intelligence and efficiency of the assistant. The Retrieve_With_Fallback function implements a hybrid recovery mechanism: it first tries to recover semantically relevant documents from the local chroma cache and, in the event of a defect, folds in search on the TAVILY web in real time, by cating the new results for future use. Meanwhile, summarizing_documents operates a gemini LLM to generate concise summaries from recovered documents, guided by a structured prompt which ensures the relevance of the request. Together, they allow low latency, informative and context responses.
def advanced_chain(query_engine="enhanced", model="gemini-1.5-pro", include_history=True):
llm = get_llm(model_name=model)
if query_engine == "enhanced":
retriever = lambda query: retrieve_with_fallback(query)
else:
retriever = enhanced_retriever.invoke
def chain_with_history(input_dict):
query = input_dict("question")
chat_history = memory.load_memory_variables({})("chat_history") if include_history else ()
docs = retriever(query)
context = format_docs(docs)
result = prompt.invoke({
"context": context,
"question": query,
"chat_history": chat_history
})
memory.save_context({"input": query}, {"output": result.content})
return llm.invoke(result)
return RunnableLambda(chain_with_history) | StrOutputParser()The Advanced_Chain function defines a modular end -to -end workflow to respond to user requests using cache or real -time research. It initializes the specified gemini model, selects the recovery strategy (cache or direct research), builds a response pipeline incorporating chat history (if activated), formats of documents in context and invites the LLM using a model guided by system. The chain also records the interaction in memory and returns the final response, analyzed in clean text. This design allows flexible experimentation with recovery models and strategies while maintaining the consistency of the conversation.
qa_chain = advanced_chain()
def analyze_query(query):
llm = get_llm(temperature=0)
analysis_prompt = ChatPromptTemplate.from_template(
"""Analyze the following query and provide:
1. Main topic
2. Sentiment (positive, negative, neutral)
3. Key entities mentioned
4. Query type (factual, opinion, how-to, etc.)
Query: {query}
Return the analysis in JSON format with the following structure:
{{
"topic": "main topic",
"sentiment": "sentiment",
"entities": ("entity1", "entity2"),
"type": "query type"
}}
"""
)
chain = analysis_prompt | llm | output_parser
return chain.invoke({"query": query})
print("Advanced Tavily-Gemini Implementation")
print("="*50)
query = "what year was breath of the wild released and what was its reception?"
print(f"Query: {query}")We initialize the final components of the intelligent assistant. QA_CHAIN is the assembled reasoning pipeline ready to process user requests using the response generation based on recovery, memory and gemini. The Analyze_Query function performs a light semantic analysis on a request, extracts the main subject, the feeling, the entities and the type of request using the Gemini model and a structured JSON invite. The example of a request, on the release and reception of Breath of the Wild, shows how the assistant is triggered and prepared for complete inference and semantic interpretation. The printed course marks the start of interactive execution.
try:
print("nSearching for answer...")
answer = qa_chain.invoke({"question": query})
print("nAnswer:")
print(answer)
print("nAnalyzing query...")
try:
query_analysis = analyze_query(query)
print("nQuery Analysis:")
print(json.dumps(query_analysis, indent=2))
except Exception as e:
print(f"Query analysis error (non-critical): {e}")
except Exception as e:
print(f"Error in search: {e}")
history = enhanced_retriever.get_search_history()
print("nSearch History:")
for i, h in enumerate(history):
print(f"{i+1}. Query: {h('query')} - Results: {h('num_results')} - Time: {h('response_time'):.2f}s")
print("nAdvanced search with domain filtering:")
specialized_retriever = EnhancedTavilyRetriever(
max_results=3,
search_depth="advanced",
include_domains=("nintendo.com", "zelda.com"),
exclude_domains=("reddit.com", "twitter.com")
)
try:
specialized_results = specialized_retriever.invoke("breath of the wild sales")
print(f"Found {len(specialized_results)} specialized results")
summary = summarize_documents(specialized_results, "breath of the wild sales")
print("nSummary of specialized results:")
print(summary)
except Exception as e:
print(f"Error in specialized search: {e}")
print("nSearch Metrics:")
plot_search_metrics(history)
We demonstrate the full pipeline in action. He performs a search using the QA_Chain, displays the response generated, then analyzes the request for feeling, subject, entities and the type. It also recovers and prints the research history of each request, the response time and the number of results. In addition, he performs filtered research on the area focused on Nintendo sites, sums up the results and visualizes research performance using Plot_Search_metrics, offering a complete view of the assistant in real time.
In conclusion, the follow -up of this tutorial gives users a full plan to create a very competent, and scalable context CLOTH System that folds web intelligence in real time with conversational AI. API TAVILY Search allows users to directly draw fresh and relevant content from the web. Gemini LLM adds robust reasoning and summary capacities, while the Langchain abstraction layer allows a transparent orchestration between memory, incorporations and outputs of the model. The implementation includes advanced features such as the filtering specific to the domain, the analysis of requests (feeling, subject and extraction of entity) and rescue strategies using a semantic vector cache built with the chroma and the googlegenerativeaiemembdings. In addition, structured journalization, error management and analytical dashboards offer transparency and diagnostics for the deployment of the real world.
Discover the Colaab. All the merit of this research goes to researchers in this project. Also, don't hesitate to follow us Twitter And don't forget to join our 90K + ML Subdreddit.
Asif Razzaq is the CEO of Marktechpost Media Inc .. as a visionary entrepreneur and engineer, AIF undertakes to exploit the potential of artificial intelligence for social good. His most recent company is the launch of an artificial intelligence media platform, Marktechpost, which stands out from its in-depth coverage of automatic learning and in-depth learning news which are both technically solid and easily understandable by a large audience. The platform has more than 2 million monthly views, illustrating its popularity with the public.