Introduction: the growing need for railing AI
As the language models (LLM) develop in the capacity and deployment scale, the risk of involuntary behavior, hallucinations and harmful results increases. The recent increase in real IA integrations in the real world in the health, finance, education and defense sectors amplifies the demand for robust safety mechanisms. The AI – Technical and procedural controls guaranteeing alignment with human values and policies – have appeared as a critical development area.
THE Stanford 2025 AI index pointed out a 56.4% In AI incidents in cases from 2025 to 233 in total, avoiding the urgency of robust railings. In the meantime, the Future of Life Institute Large IA companies noted Unfortunately on AC security planning, without any business receiving a note greater than C +.
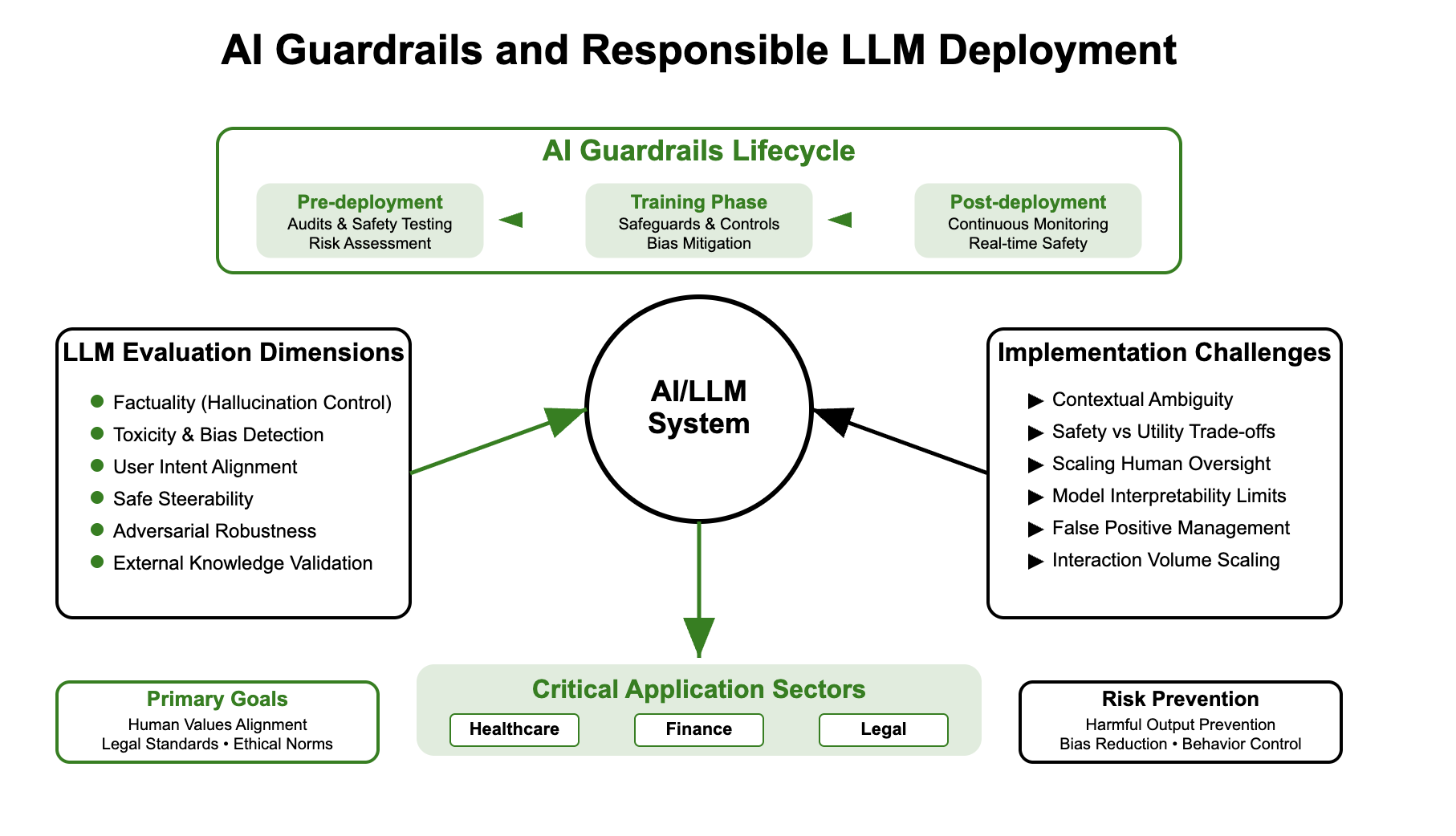
What are the railing ai?
The AI railings refer to the safety controls in the system integrated into the AI pipeline. These are not just outing filters, but include architectural decisions, feedback mechanisms, policy constraints and real -time surveillance. They can be classified in:
- Pre-deployment railings: Audits of the data set, red team model, fine policy adjustment. For example, AEGIS 2.0 includes 34,248 annotated interactions in 21 relevant security categories.
- Railing in training time: Learning to strengthen human feedback (RLHF), Differential confidentiality, biases of attenuation. In particular, overlapping data sets can collapse these railings and allow jailbreaks.
- Post-Deployment Rabe: Exit moderation, continuous evaluation, validation with recovery, emergency routing. The reference of unit 42 in June 2025 revealed high false positives in moderation tools.
Ai trustworthy: Principles and pillars
Trusted AI is not a single technique but a composite of key principles:
- Robustness: The model must behave reliably under a distribution shift or a contradictory input.
- Transparency: The path of reasoning must be explained to users and listeners.
- Responsibility: There should be mechanisms to trace the actions and failures of the model.
- Justice: The results should not perpetuate or amplify societal biases.
- Preservation of confidentiality: Techniques such as federated learning and differential confidentiality are essential.
The legislative emphasis on AI governance increased: in 2025 only, US agencies were published 59 AI regulations in 75 countries. UNESCO has also established Global ethical guidelines.
LLM assessment: beyond precision
The assessment of LLM extends far beyond traditional precision benchmarks. The key dimensions include:

- Biller: Does the model hallucinate?
- Toxicity and bias: Are the outings inclusive and not harmful?
- Alignment: Does the model follow the instructions safely?
- Direction: Can it be guided according to the intention of the user?
- Robustness: To what extent does it resist contradictory prompts?
Evaluation techniques
- Automated metrics: Blue, red, perplexity are always used but insufficient alone.
- Human loop assessments: Annotations of experts for security, tone and compliance of policies.
- Contradictory tests: Using red equipment techniques to highlight the efficiency of the test goalkeeper.
- Recovery assessment: Access to verifying facts against external knowledge bases.
Multidimensional tools such as Helm (Holistic assessment of linguistic models) and Holisticeval are being adopted.
Architecture Guard-Rus in LLM
The integration of the AI railings should start at the design stage. A structured approach includes:
- Intention detection layer: Classy potentially dangerous requests.
- Routing layer: Redirection to generation systems (RAG) (RAG) of recovery or human examination.
- Post-processing filters: Use classifiers to detect harmful content before the final output.
- Retraction loops: Includes user comments and continuous fine adjustment mechanisms.
Open source executives such as railings and rail provide modular APIs to experiment these components.
LLM security and evaluation challenges
Despite progress, major obstacles remain:
- Assessment ambiguity: The definition of NoCidirie or equity varies according to the contexts.
- Adaptability vs control: Too many restrictions reduce utility.
- Trusting human comments: Quality insurance for billions of generations is not trivial.
- Interns of the opaque model: The LLM based on the transformers remain largely dark despite the interpretation efforts.
Recent studies Show excessive railings which often result in high false positives or unusable outings (source).
Conclusion: towards responsible deployment of AI
Recupect railings are not a final solution but an evolving safety net. The trustworthy AI must be approached as a challenge in terms of systems, integrating architectural robustness, continuous evaluation and ethical provident. As LLMs gain autonomy and influence, proactive LLM assessment strategies will be used both as an ethical imperative and a technical necessity.
Organizations constructing or deploying AI must deal with security and reliability not as reflections after central design objectives. It is only then that AI can evolve as a reliable partner rather than an unpredictable risk.
FAQ on AI Rabe and LLM deployment
1. What exactly are the AI railings, and why are they important?
AI guards are integrated complete safety measures throughout the AI development life cycle, including pre-deployment audits, training guarantees and post-receipt monitoring-which help prevent outings, biases and involuntary behavior. They are crucial to ensure that AI systems align with human values, legal standards and ethical standards, in particular because AI is increasingly used in sensitive sectors such as health care and finance.
2. How are large-language models (LLM) evaluated beyond precision?
The LLMs are evaluated on several dimensions such as invoice (how often they hallucinate), toxicity and the means in the results, alignment with the intention of the user, the management (ability to be guided in complete safety) and the robustness against contradictory invites. This assessment combines automated measures, human journals, opponent tests and verification of facts against external knowledge bases to ensure a safe and more reliable AI behavior.
3. What are the biggest challenges in the implementation of effective AI railings?
The main challenges include ambiguity to define harmful or biased behavior in different contexts, balance security controls with the utility of the model, scaling human surveillance for massive interaction volumes and inherent opacity of in -depth learning models which limits the explanation. Too restrictive railings can also lead to high false positives, frustrating users and limit the usefulness of AI.

Michal Sutter is a data science professional with a master's degree in data sciences from the University of Padova. With a solid base in statistical analysis, automatic learning and data engineering, Michal excels in transforming complex data sets into usable information.
