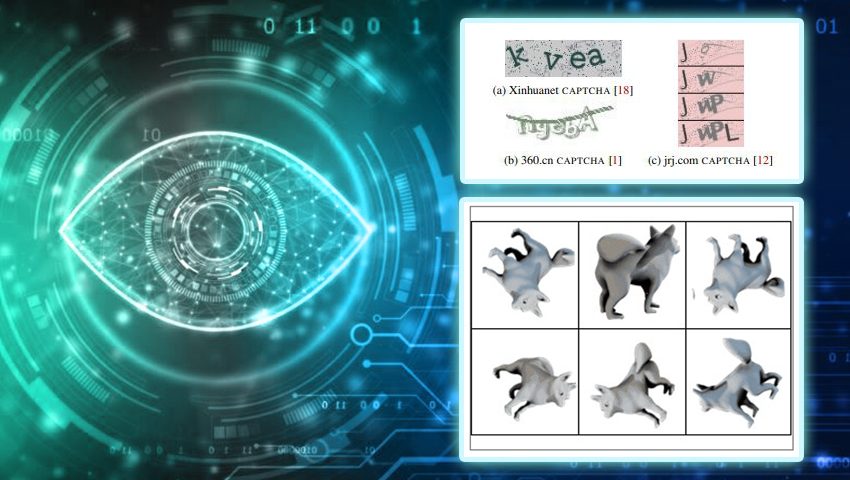
Developed 20 years ago to prevent hackers from stealing content, inserting malicious messages, getting involved in fraudulent transactions or slowing down websites to the point of complete inoperability, the acronym for this omnipresent defensive line clearly defines its mission: a fully automated audience test to distinguish computers and humans.
For almost two decades, Captchas were widely used as a means of protection against bots. Over time, as their use spread, bypassing or Captchas deception techniques have continued to improve. However, Captchas have also evolved in terms of complexity and diversity, becoming more and more difficult to solve for bots (machines) and humans. Given this long -term and always relevant technological competition, it is extremely important to study while legitimate users need to resolve modern captors and how they are perceived by these users.
Today, Captchas remain one of the main concerns for users.
However, researchers from the University of California in Irvine have concluded that robots seem to resolve them better than humans.
In their work, scientists study CAPTCHAs under natural conditions, assessing user performance to resolve them and their perception of the Captchas currently used. They collect this data through manual controls of popular websites and user studies in which 1,400 participants have collectively resolved 14,000 Captchas. The results show significant differences between the most popular types of captchas: surprisingly, the time required to resolve and the perception of users does not always correlate. A comparative study was conducted to examine the impact of the experimental context – in particular, the difference between the resolution directly of Captchas and resolve them within the framework of a more natural task, such as the creation of an account. Despite several potentially confounding factors, the results have indicated that the experimental context can influence this task and must be taken into account in the future research of Captcha. The researchers also explore the refusal of users to finish the tasks caused by Captchas, analyzing the participants who start a task and do not finish it.
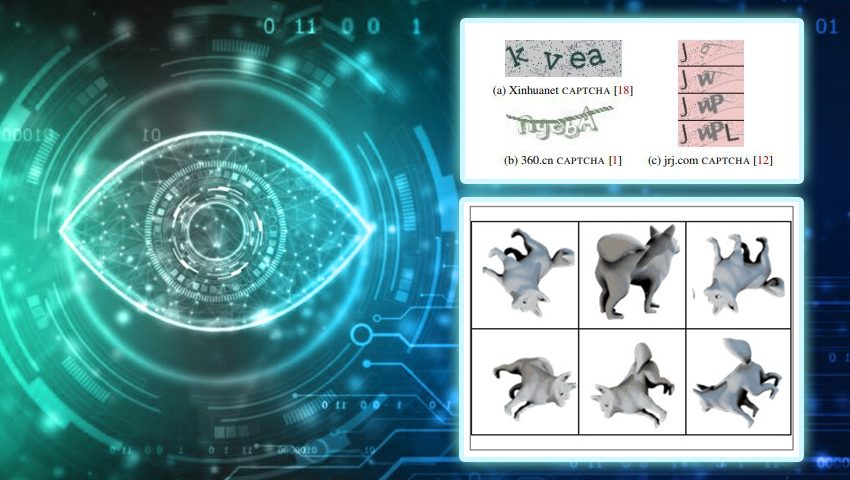
They found that the bots resolve not only various forms of captchas, such as image recognition, cursor puzzles and distorted, better but also faster text.
As captors evolve in terms of complexity and diversity, they become more and more difficult to solve for boots (machines) and humans. However, with the development of computer vision and automatic learning, the capabilities of bots by recognizing the distorted text have increased considerably, reaching precision of more than 99%. Robots can successfully overcome the Captchas with distorted text in almost 100% of cases. Human accuracy in the resolution of Captchas varies from 50% to 84%. In addition, humans are needed up to 15 seconds to solve these tasks, while robots can do it in less than a second.
Based on this study, the researchers arrived at an obvious conclusion: there is no longer a simple way, based on small images or other characteristics, to permanently distinguish humans from robots. Instead, they recommend using progress in artificial intelligence to develop “intelligent algorithms” which can more effectively differentiate BOT actions from human actions.
You can read the full search document to what follows link.