
The LLMs have made impressive progress in the generation of code for various programming tasks. However, they are mainly based on the recognition of models from examples of static code rather than understanding how the code behaves during execution. This often leads to programs that seem correct but fail during execution. Although recent methods introduce iterative refinement and self-debt, they generally act in distinct stages, generating, testing, then revising. Unlike human programmers that are constantly carrying out code fragments and adjusting according to real -time output, these models cannot integrate continuous execution feedback, limiting their effectiveness in the production of really functional code.
The role of the synthesis of the program and the incentive in the generation of code
The program synthesis has been used for a long time to assess LLM and automate code generation benchmarks, such as MBPP, Humaneval and Codecontes, by testing models on various coding challenges. While encouraging strategies, such as a few strokes and reflections, have improved performance, more recent methods now incorporate feedback loops that use execution tools or results to refine outings. Some executives even attribute tasks to several LLM agents, each attacking different aspects of the problem. However, most approaches are still based on simple decoding methods. Unlike traditional strategies, new guidance techniques, such as CFG, offer a more dynamic approach but have not yet been widely applied with real -time execution comments.
Presentation of EG-CFG: generation of code guided by the execution of the university Tel Aviv

Researchers from the University of Tel Aviv introduced EG-CFG, a new code generation method that actively uses execution feedback during the generation process, a technique commonly used by human programmers. Instead of waiting for the end, EG-CFG assesses the partial code during its writing, guiding the model to correct and executable outings. He uses a beam search to generate several code options, performs them and incorporates the execution results to influence the next steps. This real -time feedback loop considerably increases the performance between standard benchmarks, such as MBPP, Humaneval and Codecontes, even exceeding closed source models, while allowing parallel reasoning and effective dynamic exploration.
How EG-CFG works: real-time comments meet the beam search and AST analysis
The EG-CFG method improves code generation by guiding language models using real-time execution feedback during inference. For a given programming task, it generates partial code solutions and explores several continuations using the beam search. These continuations are verified for syntax using the AST analysis, and only valid those are executed on test cases to collect detailed runting traces, including variable states and errors. This feedback is then injected into the prompt of the model to shed light on future predictions. An interpolated guide mechanism between the standard output of the model and the suggestions focused on feedback, helping the model to refine its step by step until it passes all test cases.
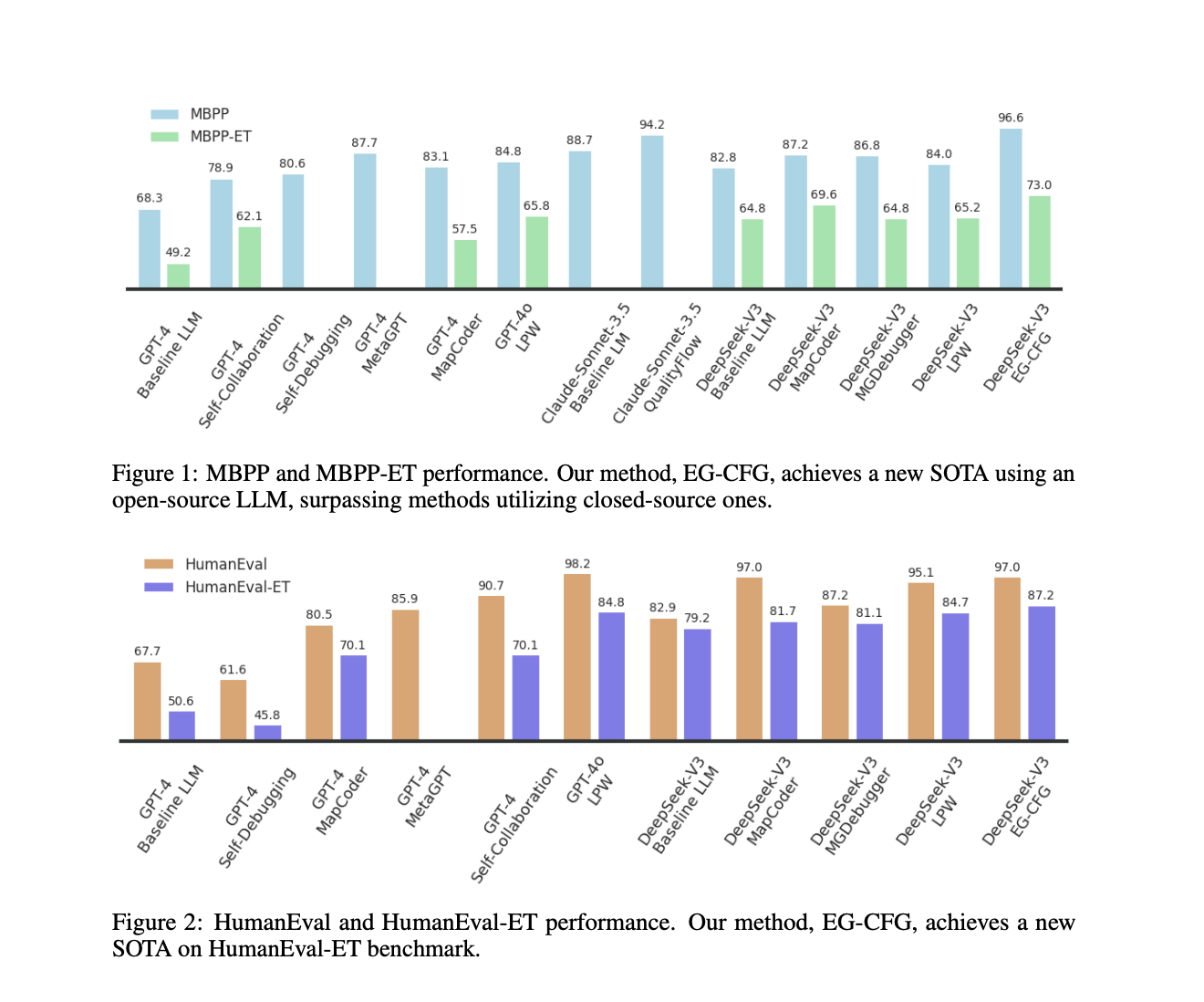
Reference results: EG-CFG surpasses GPT-4 and Claude sur Humaneval and MBPP-ET
The EG-CFG method was tested using two versions of Deepseek models: a 1.3B parameter model locally and the larger V3-0324 model via an API. It was evaluated on references to five code: MBPP, Humaneval, Codecontes, Mbpp-et and Humaneval-et. On Humaneval, EG-CFG with Deepseek V3 resolved 90.1%of tasks correctly, surpassing the GPT-4 (85.5%) and Claude 2 (83.2%). On MBPP-ET, it reached an accuracy rate of 81.4%, setting a new reference. In particular, the smaller 1.3B model also showed strong gains, improving from 46.3% to 61.7% on Humaneval when guided with EG-CFG. An ablation study confirmed the importance of components such as dynamic feedback and beam search to conduct these results.

Conclusion: EG-CFG simulates human debugging to advance the generation of code
In conclusion, the EG-CFG method introduces a new way to generate code using language models by incorporating real-time execution comments during generation. Unlike traditional approaches based on static models, EG-CFG simulates how human programmers test and refine the code. He uses beam search to explore possible code supplements, test them with actual entries, then generation guides depending on the results. This occurs line by line, ensuring that the comments are both structured and usable. The method also supports several agents working in parallel, increasing efficiency. EG-CFG reaches greater precision through standard benchmarks, showing solid results even on complex coding tasks and with smaller models.
Discover the Paper And GitHub page. All the merit of this research goes to researchers in this project.
| Sponsorship |
|---|
| Reach the most influential AI developers in the world. 1M + monthly players, 500K + community manufacturers, endless possibilities. (Explore sponsorship)) |
Sana Hassan, consulting trainee at Marktechpost and double -degree student at Iit Madras, is passionate about the application of technology and AI to meet the challenges of the real world. With a great interest in solving practical problems, it brings a new perspective to the intersection of AI and real life solutions.