In this tutorial, we introduce a rationalized approach to extract, processing and analyzing YouTube video transcriptions using LyzrAn advanced frame fueled by AI designed to simplify interaction with text data. Taking advantage of the Lyzr intuitive chatbot interface alongside the YouTube-Transcript-Papi and the FPDF, users can effortlessly convert video content into structured PDF documents and carry out insightful analyzes thanks to dynamic interactions. Ideal for researchers, educators and content creators, Lyzr accelerates the process of derivating significant ideas, generating summaries and formulating creative questions directly from multimedia resources.
!pip install lyzr youtube-transcript-api fpdf2 ipywidgets
!apt-get update -qq && apt-get install -y fonts-dejavu-coreWe have configured the environment necessary for the tutorial. The first command installs essential python libraries, including LYZR for the cat fueled by AI, YouTube-Transcript-Pap for transcription extraction, FPDF2 for the generation of PDF and IPYWIDGETS to create interactive cat interfaces. The second order guarantees that the police already is installed on the system to support the full text rendering in the generated PDF files.
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
os.environ('OPENAI_API_KEY') = "YOUR_OPENAI_API_KEY_HERE"We configure access to the API OPENAI key for the tutorial. We import the OS and OPENAI modules, then recover the API key from environmental variables (or define it directly via OS. Surprise). This configuration is essential to take advantage of the powerful Openai models in the Lyzr frame.
import json
from lyzr import ChatBot
from youtube_transcript_api import YouTubeTranscriptApi, TranscriptsDisabled, NoTranscriptFound, CouldNotRetrieveTranscript
from fpdf import FPDF
from ipywidgets import Textarea, Button, Output, Layout
from IPython.display import display, Markdown
import reDiscover the complete Notebook here
We import the essential libraries required for tutorial. It includes JSON for data management, the Lyzr chatbot for AI chat capabilities and youtubetappaptapi to extract transcription from YouTube videos. In addition, it brings FPDF for the generation of PDF, IPYWIDGETS for interactive user interface and ipyplay interface components to make Markdown content in laptops. The RE module is also imported for regular expression operations in word processing tasks.
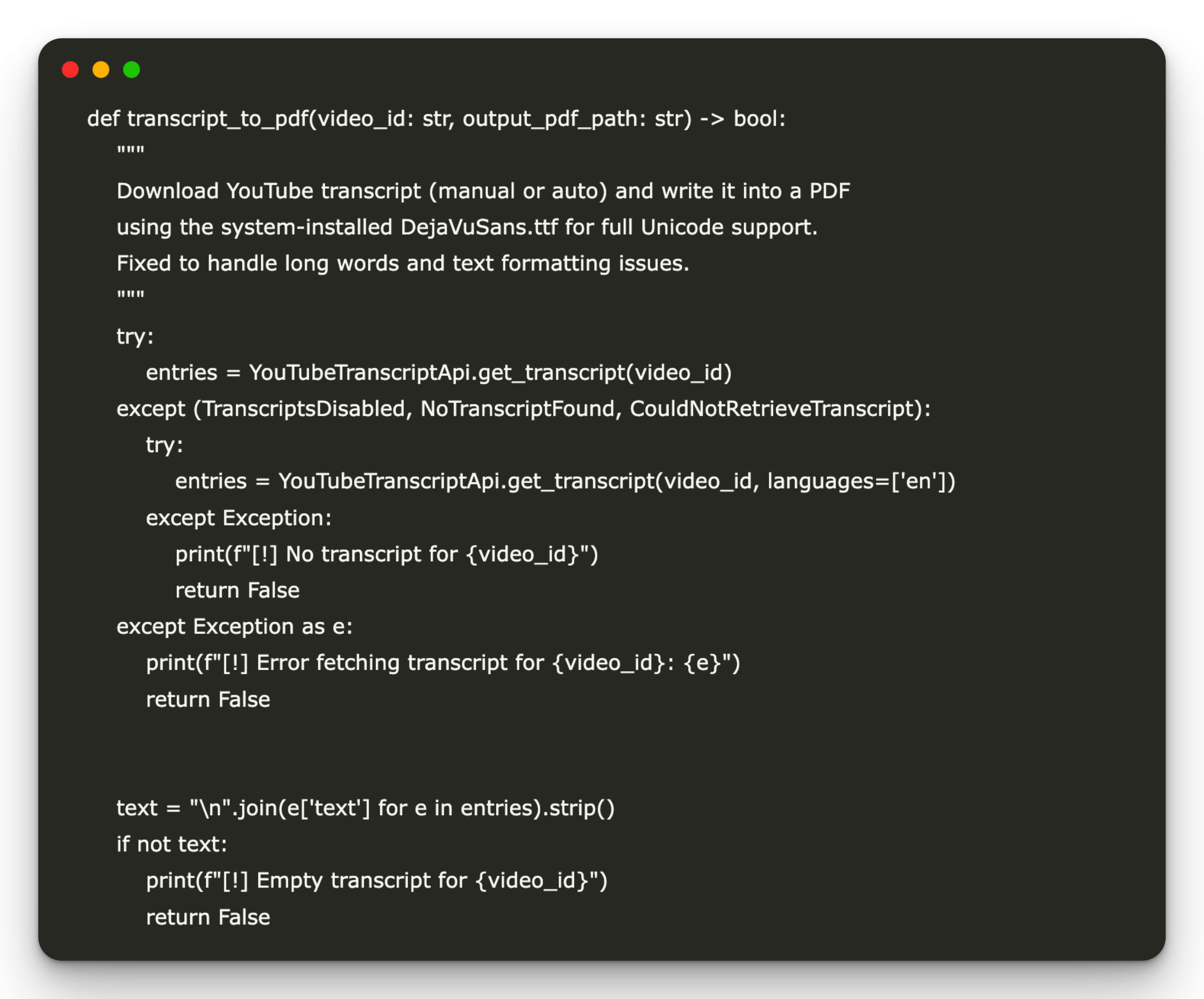
def transcript_to_pdf(video_id: str, output_pdf_path: str) -> bool:
"""
Download YouTube transcript (manual or auto) and write it into a PDF
using the system-installed DejaVuSans.ttf for full Unicode support.
Fixed to handle long words and text formatting issues.
"""
try:
entries = YouTubeTranscriptApi.get_transcript(video_id)
except (TranscriptsDisabled, NoTranscriptFound, CouldNotRetrieveTranscript):
try:
entries = YouTubeTranscriptApi.get_transcript(video_id, languages=('en'))
except Exception:
print(f"(!) No transcript for {video_id}")
return False
except Exception as e:
print(f"(!) Error fetching transcript for {video_id}: {e}")
return False
text = "\n".join(e('text') for e in entries).strip()
if not text:
print(f"(!) Empty transcript for {video_id}")
return False
pdf = FPDF()
pdf.add_page()
font_path = "/usr/share/fonts/truetype/dejavu/DejaVuSans.ttf"
try:
if os.path.exists(font_path):
pdf.add_font("DejaVu", "", font_path)
pdf.set_font("DejaVu", size=10)
else:
pdf.set_font("Arial", size=10)
except Exception:
pdf.set_font("Arial", size=10)
pdf.set_margins(20, 20, 20)
pdf.set_auto_page_break(auto=True, margin=25)
def process_text_for_pdf(text):
text = re.sub(r'\s+', ' ', text)
text = text.replace('\n\n', '\n')
processed_lines = ()
for paragraph in text.split('\n'):
if not paragraph.strip():
continue
words = paragraph.split()
processed_words = ()
for word in words:
if len(word) > 50:
chunks = (word(i:i+50) for i in range(0, len(word), 50))
processed_words.extend(chunks)
else:
processed_words.append(word)
processed_lines.append(' '.join(processed_words))
return processed_lines
processed_lines = process_text_for_pdf(text)
for line in processed_lines:
if line.strip():
try:
pdf.multi_cell(0, 8, line.encode('utf-8', 'replace').decode('utf-8'), align='L')
pdf.ln(2)
except Exception as e:
print(f"(!) Warning: Skipped problematic line: {str(e)(:100)}...")
continue
try:
pdf.output(output_pdf_path)
print(f"(+) PDF saved: {output_pdf_path}")
return True
except Exception as e:
print(f"(!) Error saving PDF: {e}")
return FalseDiscover the complete Notebook here
This function, transcript_to_pdf, automates the conversion of YouTube video transcriptions into clean and legible PDF documents. He recovers the transcription using the youtubetranscriptappi, freely manages exceptions such as unavailable transcriptions and formats the text to avoid problems such as long words breaking the PDF layout. The function also guarantees an appropriate unicode support using the Dejavusans police (if available) and optimizes the text for the PDF rendering by dividing the words too long and maintaining coherent margins. It returns true if the PDF is successfully generated or false if errors occur.
def create_interactive_chat(agent):
input_area = Textarea(
placeholder="Type a question…", layout=Layout(width="80%", height="80px")
)
send_button = Button(description="Send", button_style="success")
output_area = Output(layout=Layout(
border="1px solid gray", width="80%", height="200px", overflow='auto'
))
def on_send(btn):
question = input_area.value.strip()
if not question:
return
with output_area:
print(f">> You: {question}")
try:
print("Discover the complete Notebook here
This function, Create_Interactive_Chat, creates a simple and interactive cat interface in Colab. The use of ipywidgets provides a text entry area (textarea) so that users can type questions, a shipment button (button) to trigger the cat and an output area (output) to display the conversation. When the user clicks on Send, the input question is transmitted to the Chatbot Lyzr agent, who generates and displays an answer. This allows users to engage in dynamic questions / answers based on transcribed analysis, which makes interaction as a live conversation with the AI model.
def main():
video_ids = ("dQw4w9WgXcQ", "jNQXAC9IVRw")
processed = ()
for vid in video_ids:
pdf_path = f"{vid}.pdf"
if transcript_to_pdf(vid, pdf_path):
processed.append((vid, pdf_path))
else:
print(f"(!) Skipping {vid} — no transcript available.")
if not processed:
print("(!) No PDFs generated. Please try other video IDs.")
return
first_vid, first_pdf = processed(0)
print(f"(+) Initializing PDF-chat agent for video {first_vid}…")
bot = ChatBot.pdf_chat(
input_files=(first_pdf)
)
questions = (
"Summarize the transcript in 2–3 sentences.",
"What are the top 5 insights and why?",
"List any recommendations or action items mentioned.",
"Write 3 quiz questions to test comprehension.",
"Suggest 5 creative prompts to explore further."
)
responses = {}
for q in questions:
print(f"(?) {q}")
try:
resp = bot.chat(q)
except Exception as e:
resp = f"(!) Agent error: {e}"
responses(q) = resp
print(f"(/) {resp}\n" + "-"*60 + "\n")
with open('responses.json','w',encoding='utf-8') as f:
json.dump(responses,f,indent=2)
md = "# Transcript Analysis Report\n\n"
for q,a in responses.items():
md += f"## Q: {q}\n{a}\n\n"
with open('report.md','w',encoding='utf-8') as f:
f.write(md)
display(Markdown(md))
if len(processed) > 1:
print("(+) Generating comparison…")
_, pdf1 = processed(0)
_, pdf2 = processed(1)
compare_bot = ChatBot.pdf_chat(
input_files=(pdf1, pdf2)
)
comparison = compare_bot.chat(
"Compare the main themes of these two videos and highlight key differences."
)
print("(+) Comparison Result:\n", comparison)
print("\n=== Interactive Chat (Video 1) ===")
create_interactive_chat(bot)
Discover the complete Notebook here
Our main function () serves as a main driver for the entire tutorial pipeline. It deals with a list of YouTube video IDs, converting the transcriptions available to PDF files using the Transcripte_to_PDF function. Once the PDFs have been generated, a PDF-CAT Lyzr agent is initialized on the first PDF, allowing the model to answer predefined questions such as content summary, information identification and generation of quiz questions. The responses are stored in a responses file.Json and formatted in a Markdown report (report.md). If several PDFs are created, the function compares them using the Lyzr agent to highlight the key differences between the videos. Finally, he launches an interactive chat interface with the user, allowing dynamic conversations based on the content of the transcription, presenting the power of Lyzr for transparent PDF analysis and IA -based interactions.
if __name__ == "__main__":
main()
We ensure that the main function () runs only when the script is executed directly, and not when imported as a module. It is a better practice in Python scripts to control the execution flow.
In conclusion, by integrating Lyzr into our workflow as demonstrated in this tutorial, we can effortlessly transform the YouTube videos into a insightful and usable knowledge. The intelligent capacity of the PDF cat of Lyzr simplifies the extraction of central themes and the generation of complete summaries, and also allows an interactive exploration of content via an intuitive conversational interface. The adoption of LYZR allows users to unlock deeper information and to considerably improve productivity when working with video transcriptions, whether for academic research purposes, for educational purposes or a creative content analysis.
Discover the Notebook here. All the merit of this research goes to researchers in this project. Also, don't hesitate to follow us Twitter And don't forget to join our 95K + ML Subdreddit and subscribe to Our newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc .. as a visionary entrepreneur and engineer, AIF undertakes to exploit the potential of artificial intelligence for social good. His most recent company is the launch of an artificial intelligence media platform, Marktechpost, which stands out from its in-depth coverage of automatic learning and in-depth learning news which are both technically solid and easily understandable by a large audience. The platform has more than 2 million monthly views, illustrating its popularity with the public.
