Diffusion LLMS as a paradigm shift in the generation of code
The LLMs have revolutionized the treatment of natural language with impressive results between tasks, from dialogue to code generation. Masked diffusion models have become an alternative and are extended in LLMs based on diffusion such as Llada and Dream. This model iteratively refines the entire sequence in parallel, allowing global planning of the content. The LLM diffusion approach is a good adjustment for the code generation because code writing often involves non-sequential back and forth refinement. However, it is not clear how the open source LLM perform coding tasks. Indeed, existing post-training efforts show marginal gains or depend on the semi-autoregressive decoding, which deviates from the nature of global dissemination.
Evolution of text diffusion models and their impact on the synthesis of the code
The first text diffusion models include mask diffusion models, with recent scaling efforts producing diffusion LLM such as difference, Llada and dream. The diffusion of the block offers a hybrid approach which applies the diffusion in each block. Multimodal models such as Lavida, MMADA and DIMLE combine text diffusion models with vision models. In the code generation, Codefusion was the first to combine diffusion models with code generation, but it is limited to small -scale models and simple tasks. The LLM of recent commercial dissemination such as mercury and gemini show performance comparable to the main models of self -regressive code. However, the current RL methods for DLLMs, such as D1 and MMADA using GRPO, depend on the dissemination of blocks during deployment and evaluation.

Apple and HKU introduce diffucumer: a specialized dissemination model for code
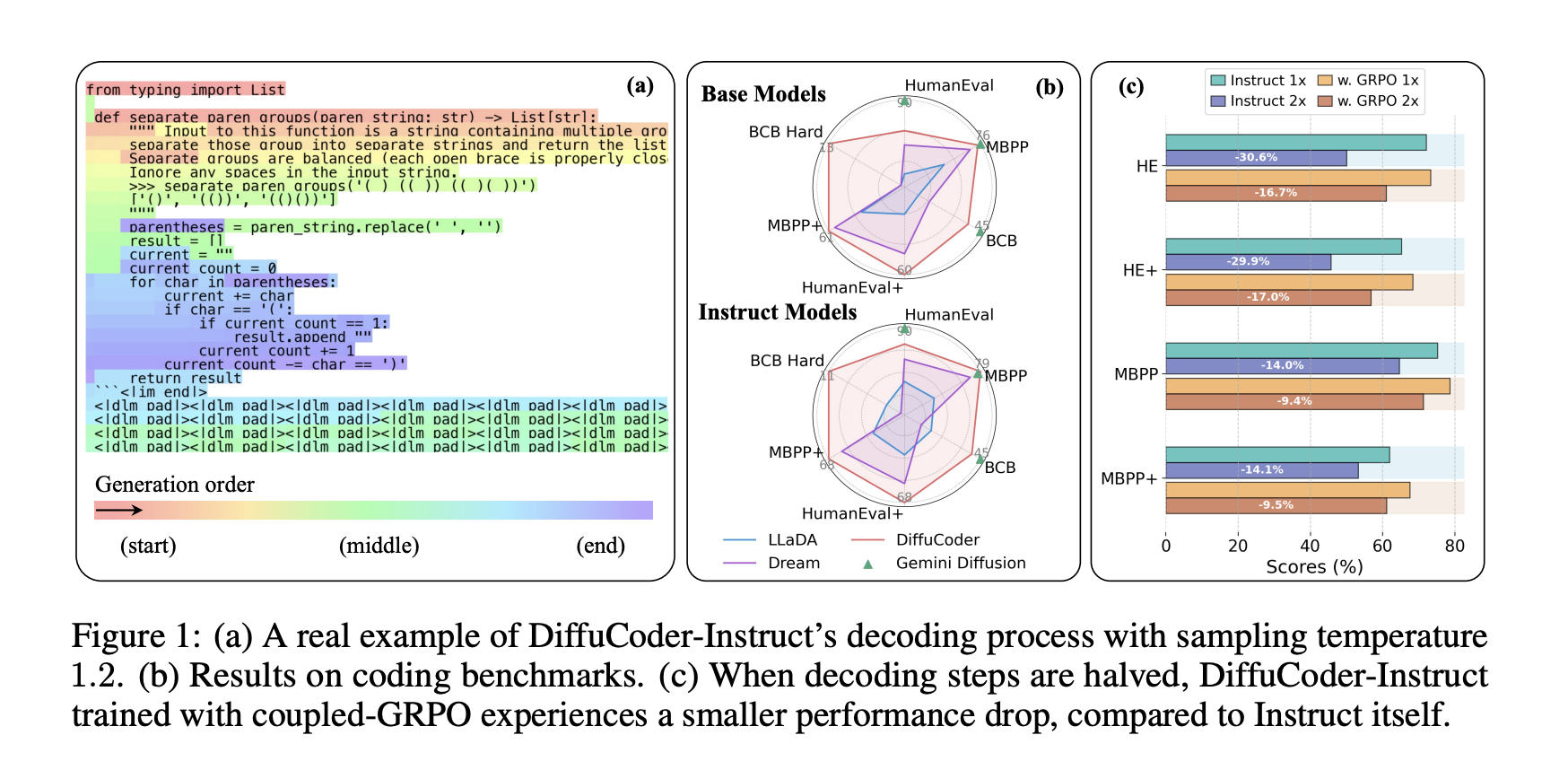
Researchers from Apple and the University of Hong Kong proposed that Diffucoder, a specialized 7B -scale distribution model for code generation, formed on 130B effective tokens. Make it a precious test assessment to explore LLM behaviors based on diffusion and advance post-training methods. Researchers introduce local and global self -regressive measures to measure how much generation follows a scheme from left to right. The analysis reveals that the LLMS diffusion has an effect of entropy wells, causing a strong causal bias during the conditional generation. Diffucumer becomes more flexible in the order of generation of tokens as the sampling temperature goes from 0.2 to 1.2, freeing from strict constraints from left to right and reaching higher precision at 10.

A four-step training pipeline taking advantage of RéfineCode and coupled-GRPO
The researchers adapt their model from the Qwen-2.5 co-coder as a basic model and carry out a continuous pre-training using a 400B-Token Code Code Corpus of Refinecode and Stackv2. The formation consists of four stages: adaptation pre-training, training half-training with 16b of cod data tokens, adjustment of instructions with sFF 436K and post-training samples using GRPO coupled with 21K hard samples from Acecoder-87K. Anticipated stop is applied to stage 1 after treatment of 65B tokens. Step 2 is formed for 4 eras, which leads to a total of 65 billion tokens. The evaluation environments are built using three codes – Humaneval, MBPP and Evalplus – with Bigcodebench. They include complete and hard subsets, covering the completion and the types of requests based on the instruction.
Reference results: Performances and Dipucoder optimization previews
Diffucoder trained on coded tokens 130B, obtains performance on a par with the Co-Coder Qwen2.5 and the OpenCoder. However, all DLLMs show only a marginal improvement compared to their basic models after setting instructions compared to the Coder QWEN2.5 + SFT, which makes it possible to improve significant from the adjustment of instructions on the same data. In addition, the coupled GRPO training shows high efficiency, while basic variants such as D1, completion of the full mask and decoupled sampling tend to present an unstable reward learning behavior. RL Fine-Réglage increases the optimal sampling temperature during the 0.2 evaluation to higher values, which suggests that the drive details by Token. This reduces the dependence of the model to a strict autoregressive decoding and improves its ability to generate tokens in parallel.
Coupled-GRPO and the future of code-based code models
In this article, researchers present Diffucoder, an open source diffusion model on a 7B scale for code with high performance, as well as its complete training recipe and a detailed DLMM analysis for code generation. They also introduce a coupled RL algorithm, an RL algorithm which respects the non -self -regressive nature of the DLMM by a coupled sampling technique for a more precise estimate of likelihood. CoupleD-GRPO improves the performance of Dipucoder, showing the effectiveness of RL methods aligned on the principles of diffusion. This work offers the community a more in -depth overview of DLLMs and establishes a solid basis for future research on their applications in complex reasoning and generative tasks.
Discover the Paper And Codes. All the merit of this research goes to researchers in this project.
Ready to connect with 1 million developers / engineers / researchers? Find out how NVIDIA, LG AI Research and the best IA companies operate Marktechpost to reach their target audience (Learn more)

Sajjad Ansari is a last year's first year of the Kharagpur Iit. As a technology enthusiast, he plunges into AI's practical applications by emphasizing the understanding of the impact of AI technologies and their real implications. It aims to articulate complex AI concepts in a clear and accessible way.