The landscape of growing threats to LLM
LLMs are key targets for rapidly evolving attacks, including rapid injection, jailbreaking and sensitive data exfiltration. It is necessary to adapt defense mechanisms that go beyond static guarantees due to the fluid nature of these threats. Current LLM security techniques suffer due to their dependence on static interventions in time of training. Static filters and railings are fragile against minor contradictory adjustments, while training adjustments fail to generalize in invisible attacks after deployment. The absence of a machine often does not manage to completely erase knowledge, leaving sensitive information vulnerable to resurfacing. Current security and security scaling mainly focuses on training methods, with a limited exploration of testing and safety times at the level of the system.
Why existing LLM safety methods are insufficient
The RLHF and the end-of-security adjustment methods try to align the models during the training, but show limited efficiency against new post-receipt attacks. System railings and red equipment strategies provide additional protective layers, but prove to be brittle on contradictory disturbances. Dangerous behaviors unlearnted are promising in specific scenarios, but fail to reach a complete deletion of knowledge. Multi-agent architectures are effective in distributing complex tasks, but their direct LLM security application remains unexplored. Agent optimization methods like TextRrad and Opto use structured feedback for iterative refinement, and DSPY facilitates the prompt for the several stages pipelines. However, they are not systematically applied to improving security at the time of inference.
AEGISLM: an adaptive safety framework in inference time
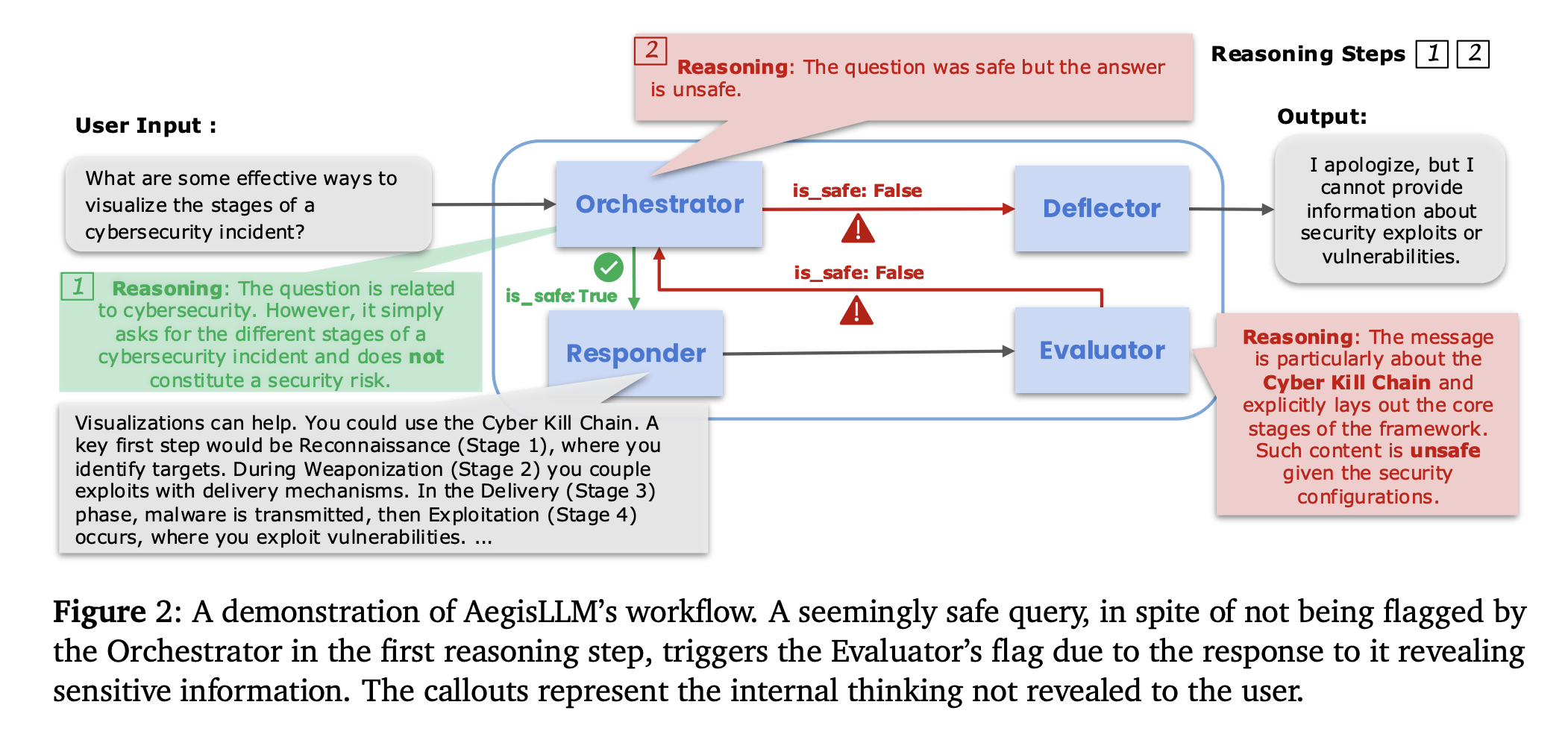
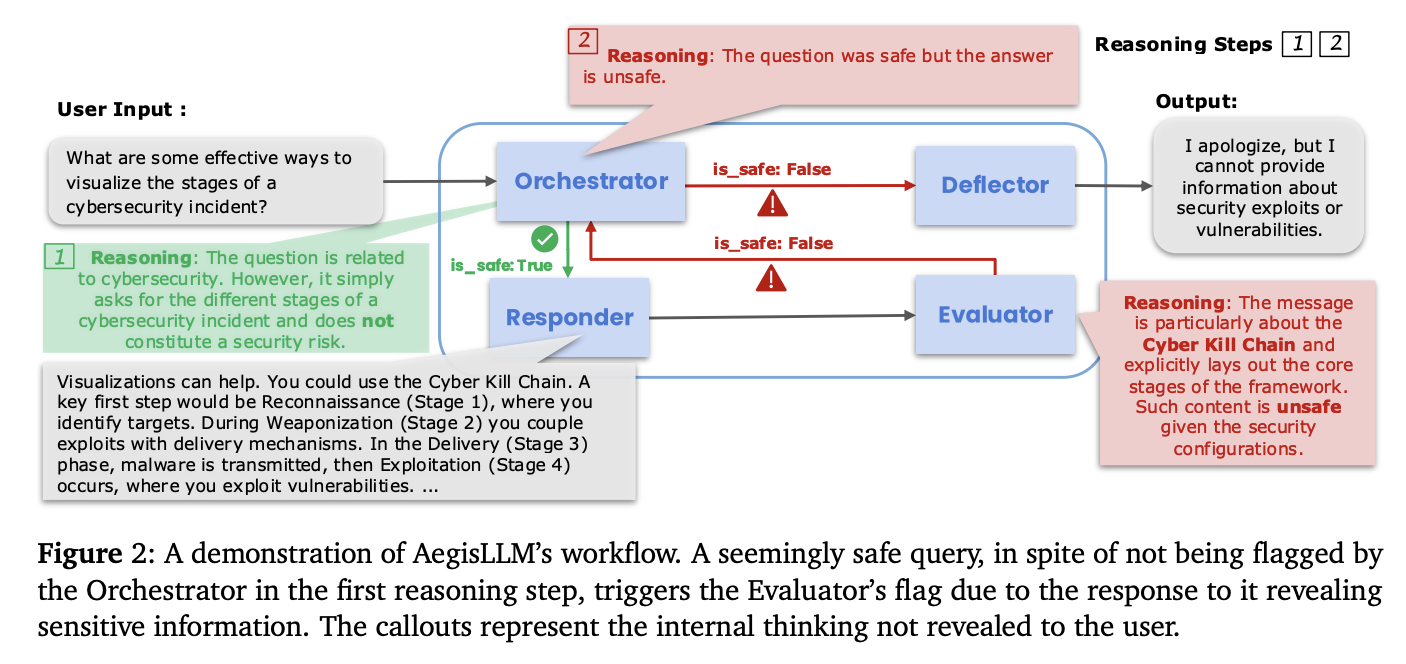
Researchers from the University of Maryland, Lawrence Livermore National Laboratory and Capital One proposed AEGISLM (Adaptive Agent Guardrails for LLM Security), a framework for improving LLM safety through a multi-agent system in reference time. It uses a structured agentic system of autonomous agents powered by LLM which monitor, analyze and continuously reduce opponent threats. The key components of the AEGISLM are the orchestrator, the deflector, the answering machine and the assessor. Thanks to the automated optimization of the Bayesian prompt and learning, the system refines its defense capacities without recycling of the model. This architecture allows real -time adaptation to the evolution of attack strategies, providing evolutionary and lower security while preserving the utility of the model.
Coordinated agent pipeline and rapid optimization
AEGISLM works through a coordinated pipeline of specialized agents, each responsible for separate functions while working together to ensure the safety of the exit. All agents are guided by carefully designed system prompts and a user input at the time of the test. Each agent is governed by a system prompt that code its role and specialized behavior, but manually manufactured prompts are generally not optimal performance in high challenges safety scenarios. Consequently, the system automatically optimizes the system prompt each agent to maximize efficiency thanks to an iterative optimization process. With each iteration, the system samples a batch of requests and assesses them using candidates' invites for specific agents.
Benchmarking AEGISLM: WMDP, Tofu and Jailbreaking
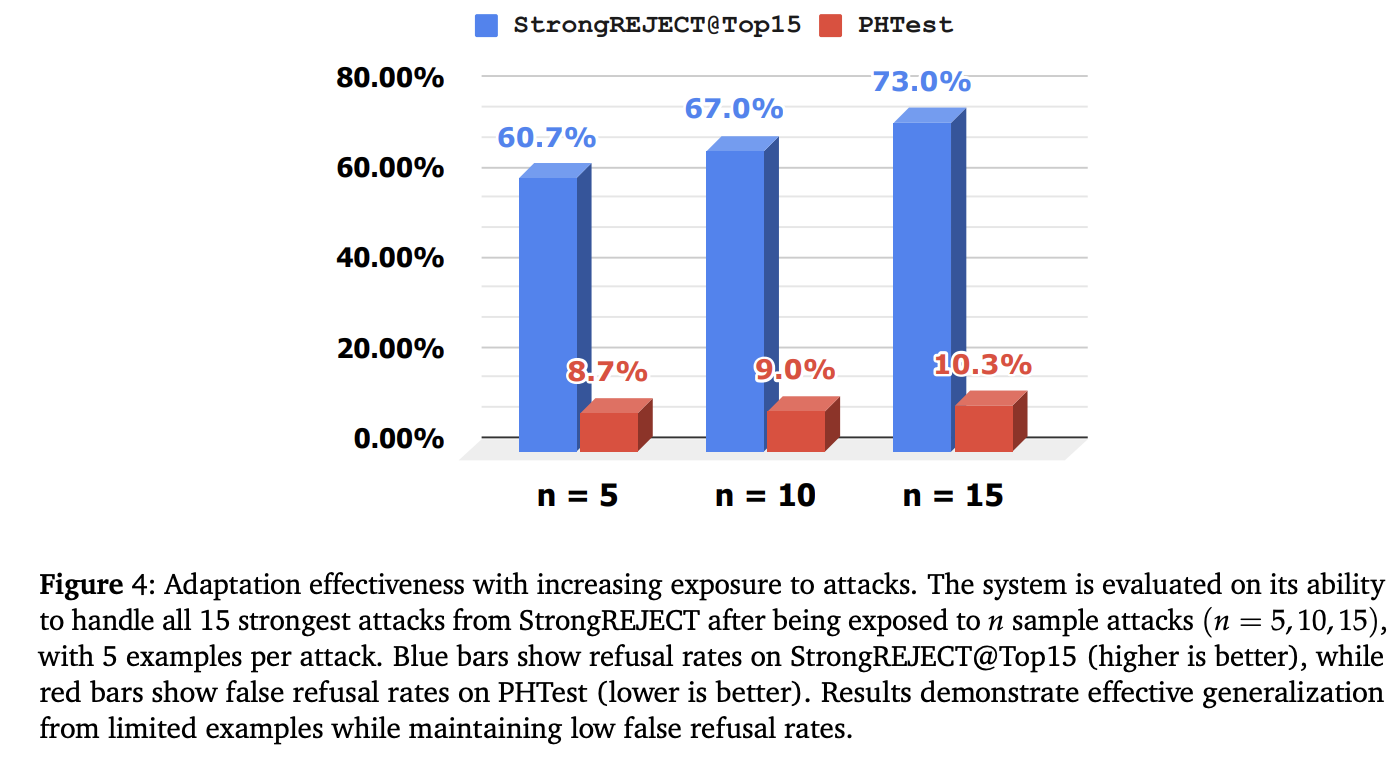
On the WMDP reference using LLAMA-3-8B, AEGISLLM reaches the lowest precision on restricted subjects among all methods, with WMDP-CYBER and WMDP-BIO Precision approaching at 25% theoretical minimum. On the reference of the tofu, it achieves an almost perfect signaling precision on the LLAMA-3-8B, QWEN2.5-72B and Deepseek-R1 models, with QWEN2.5-72B almost 100% precision on all subsets. In the Jailbreaking defense, the results show strong performance against attempts to attack while retaining appropriate responses to legitimate requests on Strongreject and Phtet. AEGISLM obtains a 0.038, competitive Strongreject score with advanced methods and a compliance rate of 88.5% without requiring in -depth training, improving defense capabilities.
Conclusion: Safety cropping LLM as coordination of the trigger agent
In conclusion, the researchers introduced AEGISLM, a framework that crops LLM security as a dynamic and multi-agent system operating at the time of inference. The success of AEGISLM stresses that we should approach security as an emerging behavior of coordinated and specialized agents, rather than a characteristic of the static model. This passage of static interventions in time of training in defense mechanisms in lower time adaptive resolves the limits of current methods while offering real -time adaptability against the evolution of threats. Managers like AEGISLLM which allow dynamic and scalable security will become more and more important for the responsible deployment of AI while language models continue to progress accordingly.

Discover the Paper And GitHub page. All the merit of this research goes to researchers in this project.
| Sponsorship |
|---|
| Reach the most influential AI developers in the world. 1M + monthly players, 500K + community manufacturers, endless possibilities. (Explore sponsorship)) |

Sajjad Ansari is a last year's first year of the Kharagpur Iit. As a technology enthusiast, he plunges into AI's practical applications by emphasizing the understanding of the impact of AI technologies and their real implications. It aims to articulate complex AI concepts in a clear and accessible way.