

The functional theory of density (DFT) serves as a basis for modern computer chemistry and the science of materials. However, its high calculation cost severely limits its use. Interatomic Automatic Learning Potentials (MLIP) have the potential to closely get closer to the precision of the DFT while considerably improving performance, reducing the calculation time of hours for less than a second with an O scale (N) compared to the O (n³). However, the formation of MLIPs which are generalized on different chemical tasks remain an open challenge, because traditional methods are based on specific data sets with smaller problems instead of using the advantages of scaling that have motivated significant progress in language and vision models.
Existing attempts to meet these challenges have focused on the development of universal MLIP trained on larger data sets, data sets like Alexandria and Omat24 leading to improved performance on the Matbench-Discovery ranking. In addition, the researchers explored the scaling relationships to understand the relationships between the calculation, the data and the size of the model, inspired by empirical levels in the LLM which motivated training on more token with more important models for predictable performance improvements. These relationships of scale help to determine the optimal allocation of resources between the data set and the size of the model. However, their application to MLIPs remains limited compared to the transformer impact observed in language modeling.

Researchers from Fair in Meta and Carnegie Mellon University proposed a family of universal models for atoms (UMA) designed to test the limits of precision, speed and generalization for a unique model through chemistry and materials. To meet these challenges, they have developed empirical scale laws regarding the calculation, data and size of the model to determine the optimal dimensioning and model training strategies. This has helped overcome the challenge of balancing precision and efficiency, which was due to the unprecedented data set of around 500 million atomic systems. In addition, the UMA works in a similar or better way than the specialized models both in accuracy and inference speed on a wide range of material, molecular and catalysts, without fine adjustment to specific tasks.
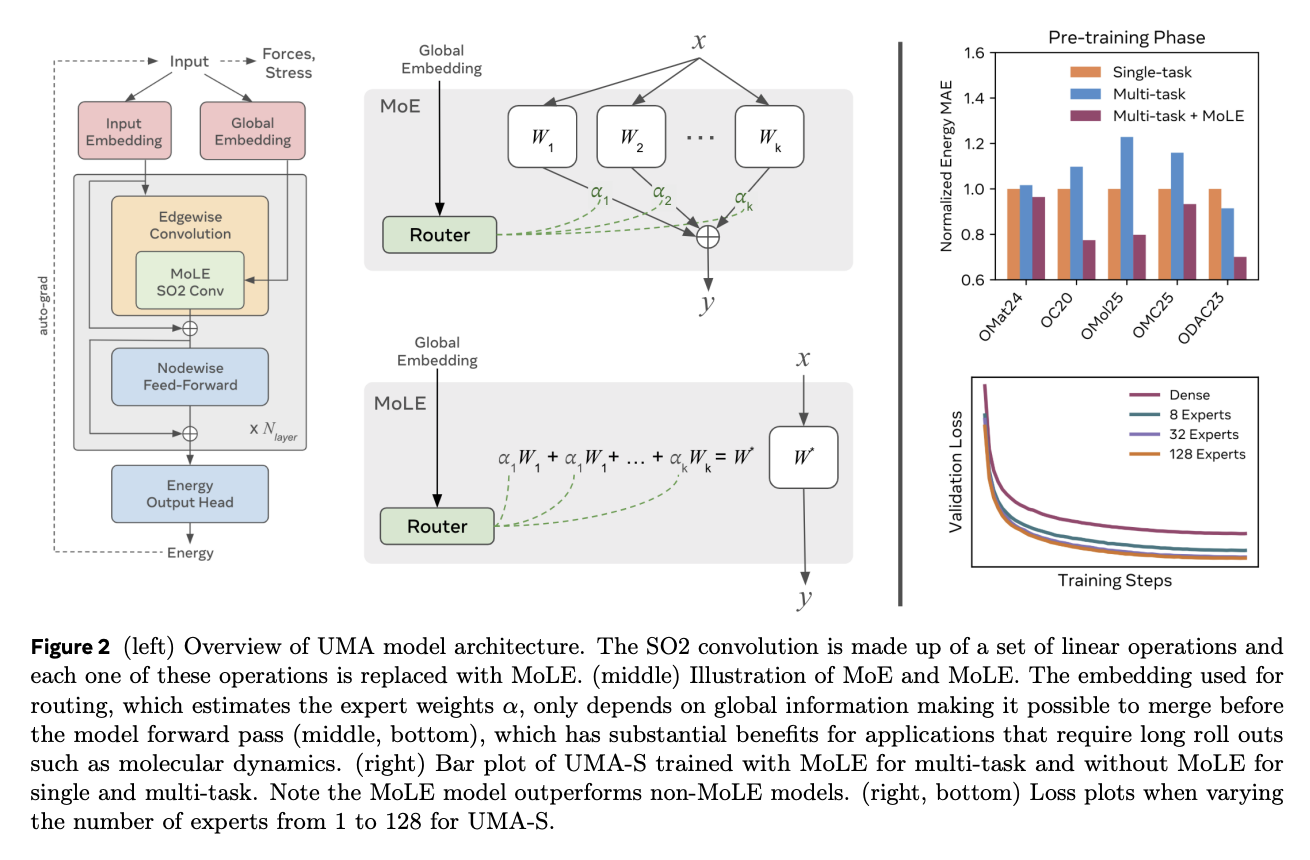
The UMA architecture is based on Esen, an equivalent graphic neurons network, with crucial modifications to allow effective scaling and manage additional inputs, including total load, spin and DFT parameters for emulation. It also incorporates a new integration which allows UMA models to integrate load, spin and DFT tasks. Each of these entries generates an integration of the same dimension as the spherical channels used. The training follows a two -step approach: the first step directly predicts the forces for faster training, and the second step removes the head of force and refines the model to predict the forces and constraints of conservation of the conservation of automatic conservation, guaranteeing the conservation of energy and the potential potential energy landscapes.
The results show that UMA models have log-linear scale behavior through the tested flop beaches. This indicates that a larger model capacity is necessary to adapt to the UMA data set, with these scaling relationships used to select precise model sizes and show the advantages of mole compared to dense architectures. In multi-tamed training, a significant improvement is observed in the loss when the 8 experts are passed, smaller gains with 32 experts and negligible improvements in 128 experts. In addition, the UMA models demonstrate an exceptional inference effectiveness despite a large number of parameters, with UMA-S capable of simulating 1000 atoms at 16 stages per second and adjustment system sizes up to 100,000 atoms in memory on a single 80 GB GPU.
In conclusion, the researchers introduced a family of universal models for atoms (UMA) which have high performance in a wide range of landmarks, including materials, molecules, catalysts, molecular crystals and metal-organic frames. He obtained new cutting -edge results on established benchmarks such as Adsorbml and Matbench Discovery. However, he fails to manage long -range interactions due to the cut -off distance of 6 standard. In addition, it uses distinct interests for discreet load or spin values, which limits generalization to invisible loads or towers. Future research is intended to progress to universal MLIPs and to unlock new possibilities in atomic simulations, while highlighting the need for more difficult references to stimulate future progress.

Sajjad Ansari is a last year's first year of the Kharagpur Iit. As a technology enthusiast, he plunges into AI's practical applications by emphasizing the understanding of the impact of AI technologies and their real implications. It aims to articulate complex AI concepts in a clear and accessible way.