
The institutions of AI develop heterogeneous models for specific tasks but face data shortage challenges during training. Traditional federated learning (FL) only supports the collaboration of homogeneous models, which needs architectures identical to all customers. However, customers develop model architectures for their unique requirements. In addition, the sharing of models formed locally at the high intensity of efforts contains an intellectual property and reduces the interest of the participants to engage in collaborations. Heterogeneous federated learning (HTFL) addresses these limits, but literature has no unified reference to assess HTFL in various fields and aspects.
Context and categories of HTFL methods
The existing FL benchmarks focus on the heterogeneity of the data using models of homogeneous customers but neglect real scenarios which imply the heterogeneity of the model. The representative HTFL methods are distributed in three main categories concerning these limits. Partial parameter sharing methods such as LG-FEDAVG, Fedgen and Fedgh maintain heterogeneous characteristics extractors while assuming homogeneous classifier heads for knowledge transfer. Mutual distillation, such as FML, Fedkd and Fedmrl, trains and shares small auxiliary models through distillation techniques. The methods of sharing prototypes transfer light class prototypes as global knowledge, collecting local customer prototypes and collecting servers to guide local training. However, it is not clear if existing HTFL methods work consistently in various scenarios.
Htfllib presentation: a unified reference
Researchers from the University of Shanghai Jiao Tong, Beihang University, the University of Chongqing, Tongji University, Polytechnic University of Hong Kong and Queen's Belfast University proposed the first heterogeneous federated learning library (HTFLIB), an easy and extensible method to integrate several scenarios of data and heterogeneity model. This method integrates:
- 12 data sets in various fields, methods and scenarios of data heterogeneity
- 40 model architectures ranging from small to large, through three modalities.
- A modularized HTFL code base and easy to extend with implementations of 10 representative HTFL methods.
- Systematic assessments covering accuracy, convergence, calculation costs and communication costs.
Data sets and terms in htfllib
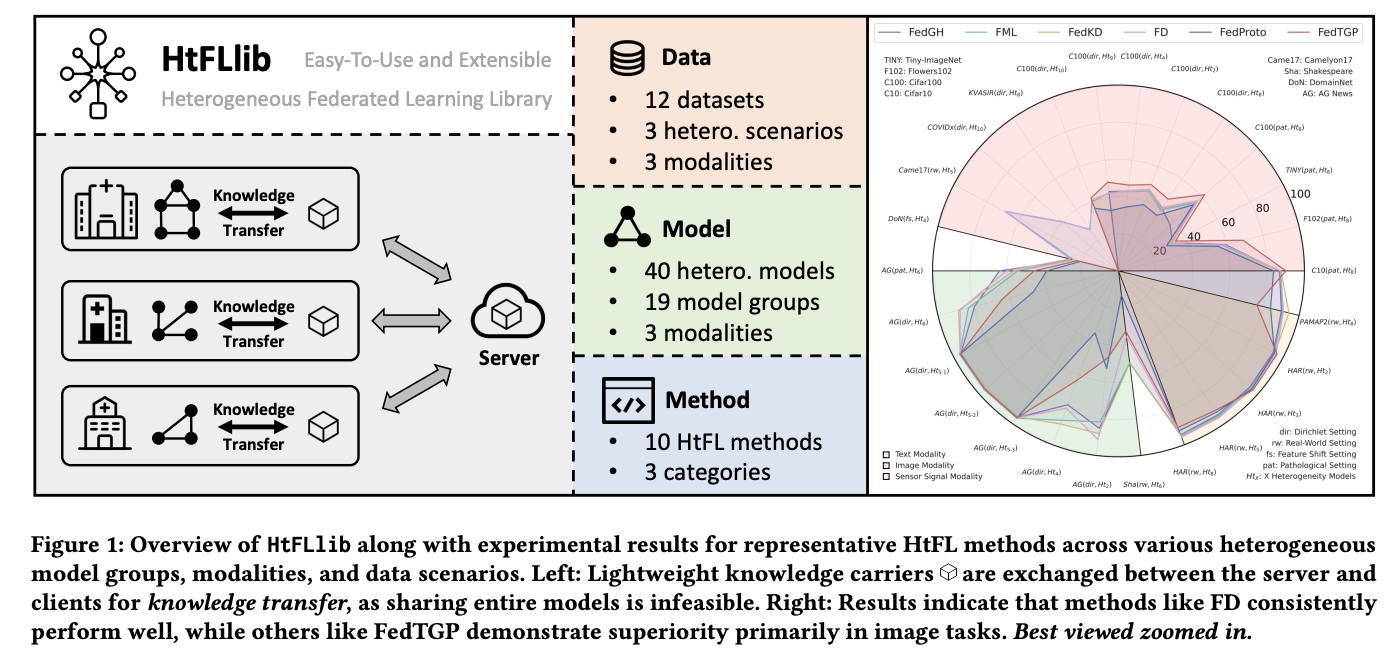
HTFLIB contains heterogeneity scenarios of detailed data divided into three parameters: biased labels with pathological and DIRECHLET as sub-assemblies, shift in functionalities and real world. It incorporates 12 data sets, including CIFAR10, CIFAR100, FLOWERS102, Tiny-Imagenet, KVASIR, COVIDX, Domainnet, Camelyon17, AG News, Shakespeare, HAR and PAMAP2. These data sets vary considerably in the field, data volume and class numbers, demonstrating the complete and versatile nature of HTFLIB. In addition, researchers focus mainly on image data, in particular the label bias setting, because image tasks are the most commonly used tasks in various fields. HTFL methods are evaluated on image, text and sensor signal tasks to assess their respective strengths and weaknesses.
Performance analysis: image modality
For image data, most HTFL methods show decreased precision as the heterogeneity of the model increases. The FedMRL shows a higher force thanks to its combination of world models and auxiliary local. During the introduction of heterogeneous classifiers who make the methods of sharing partial parameters inapplicable, FedTGP maintains superiority through various parameters due to its adaptive prototype refinement capacity. The experiences of medical data together with pre-formed heterogeneous models with black box show that HTFL improves the quality of the model compared to pre-formulated models and reaches larger improvements than auxiliary models, such as FML. For text data, the advantages of FedMRL in label bias settings decrease in the parameters of the real world, while FedProto and Fedtgp work relatively badly compared to image tasks.
Conclusion
In conclusion, the researchers introduced HTFLIB, a framework that addresses the critical gap in the HTFL comparative analysis by providing unified assessment standards in various fields and scenarios. The modular design and the extensible architecture of HTFLIB provide a detailed reference for research and practical applications in HTFL. In addition, its ability to support heterogeneous models in collaborative learning opens the way to future research on the use of large pre-formulated complex models, black box systems and various architectures between different tasks and methods.
Discover the Paper And GitHub page. All the merit of this research goes to researchers in this project. Also, don't hesitate to follow us Twitter And don't forget to join our Subseubdredit 100k + ml and subscribe to Our newsletter.

Sajjad Ansari is a last year's first year of the Kharagpur Iit. As a technology enthusiast, he plunges into AI's practical applications by emphasizing the understanding of the impact of AI technologies and their real implications. It aims to articulate complex AI concepts in a clear and accessible way.
